To try to explain “Dynamic Consistency Boundary” usage in Event Sourcing, I’d contrast it to “traditional” Event Sourcing where events are only organized into a stream of related events. For example, all the events related to a single invoice in an invoicing system are an example of an event stream. DCB came about because Axon IQ has weak consistency and couldn’t support transactions across multiple streams the way that Marten or Polecat can it’s often impossible to model a system where every operation only involves a single event stream. To that end, folks created the idea of “Dynamic Consistency Boundary” Event Sourcing where events are more organized by tags and the event stores that support DCB are able to enforce transactional boundaries based on an event tag query (think: all the events of these types that are related to either this class id, student id, or instructor id) so that systems can be much more flexible over time.
Marten has had support for the Dynamic Consistency Boundary approach (DCB) to Event Sourcing for a little while. The Marten 9.0 release last week added a new, potentially more performant option for DCB using the PostgreSQL HSTORE extension — which is supported by all the major cloud providers plus specialized cloud providers for managed PostgreSQL like Neon and Supabase.
Unfortunately, we don’t yet have a way to retroactively switch from “classic” DCB to the HSTORE style DCB in an existing application, but let’s say that you’re starting:
A greenfield application
A problem domain where the event stream boundaries either aren’t clear upfront or you think will never cleanly line up neatly in terms of event streams
You might want to adopt DCB style Event Sourcing from the get go, then use the HSTORE flavor of Marten DCB to be more performant. To get started, just opt into that style of DCB storage like this:
// This is all you need to do, but this does assume
// that the HSTORE extension is available
opts.Events.DcbStorageMode=DcbStorageMode.HStore;
});
The HSTORE style of DCB is a big performance improvement if you are querying events by two or more tag values at a time, which I’d probably argue is the only time DCB is worthwhile to use from a logical structure perspective anyway:)
I was the technical lead of a very successful software project for supply chain management in the early 2000’s. The most popular feature within that early web application was a last minute throw in report that I did as a favor for our business contact that wasn’t even part of our original specification. Once the system was live and folks found out about that report, we actually had to add new servers to the application cluster to keep up with the unexpected load just because that one single report was so popular with supply chain analysts.
My only point there is that I’m not always sure what features will actually resonate with users. Sometimes you know based on reported friction that a new feature will eliminate a pain point, but with the DCB support in Marten and Wolverine, I flat out don’t know. DCB is very popular in the Event Sourcing community outside of the Critter Stack, and it was clear we had to have that feature set just to be competitive from an adoption perspective, but I’m not seeing a lot of interest in DCB from our existing community as Marten is much more able to handle more flexible transactional consistency across event streams than specialist Event Store databases seem to be able to do.
But, if DCB is something you’re interested in or just works much easier for your mental model of how the domain should be modeled in your system, Marten has you covered!
The JasperFx AI Skills are already updated with content to help you upgrade quickly to our new versions.
The Critter Stack 2026 releases that I first mentioned a couple weeks ago have all hit Nuget — and in some cases might already have bug fix or even a small enhancement release since that major version release. It’s not a huge release at all, but it helps makes systems built with the Critter Stack tools potentially more performant, puts the technical foundation in a bit better place, and positions our tools to be much more usable within Serverless scenarios.
The major goals of this release wave have been to:
Optimize the “cold start” time of both Marten and Wolverine (Polecat was purposely built with somewhat different internals and less flexibility than Marten to have an optimized cold start time from the get go) with the goal of making the tools better for Serverless applications, dynamic scaling, and just having faster cycle times in local development
Believe it or not (I was pleasantly surprised), it’s now possible to compile applications using Marten, Polecat, and/or Wolverine with AOT compliance (there’s a catch or two of course)
Reduce the technical duplication between Marten and Polecat with the hopes of having less code to support in general and improving Polecat’s usage by relying more on proven internals from the much older Marten
Smuggle in a lot of new observability in the internals for CritterWatch usage soon
Establish what had been recommended “opt in” configurations as the new defaults for better greenfield development with Wolverine and especially Marten
I don’t have final numbers, but there was an attempt to make some performance improvements to the internals of all the tools along the way. I’ll publish some benchmarking by the end of this coming week.
There will inevitably be problems with these new releases — and there’s already been a couple reports related to the projection changes in Marten that have been addressed so far. My attitude about this never ending stream of bug reports is summed up by the great philosopher of my youth, Vanilla Ice:
“If there was a problem, yo I’ll solve it” (or Babu or Anne or someone else active in the community will).
I’ve got to tell you that I love that the open issue and pull requests count across the entire Critter Stack is very low (single digits as I write this) and I’d like to keep it that way going forward, so we’ll just try to jump on whatever comes in.
Alright, on to some details:
Marten 9.0
The first change and most important change is that Marten 9.0 completely eliminated all usage of the runtime code generation that Marten has used since the 4.0 release in 2021. There’s still just the tiniest bit of FastExpressionCompiler usage for being able to read or write identity values to persisted types, but no other code generation. That’s where the cold start improvement happened for Marten 9.0. That also got us a lot farther along to the AOT compliance.
Got a maybe significant performance boost as we adopted a purely source generator approach around the conventional methods in place of our previous FastExpressionCompiler approach that didn’t build up the most efficient possible code by any means (FEC was not the problem by any means). Your experience will vary of course, and I expect that to probably be the biggest issue with the release just because of the sheer possible permutations of usage, but I think these changes will ultimately be beneficial for performance.
Marten 9.0 also adjusted some of the out of the box defaults and corrected what I think is “Marten’s original sin” (identity map enabled by default) when we were purposely building Marten at first as a drop in replacement for an existing tool way back when. The big changes are:
Lightweight sessions (no identity map) are now the Marten default. If you’re building a greenfield system or follow “Critter Stack” best practices and idioms, you’ll see a small performance improvement. If you have very deep call stacks where the same Marten session is getting reused at different times and possibly loading the same entity multiple times, you may want to explicitly enable identity sessions by default.
The event store append mode is “quick append with server timestamps” by default. The performance and even reliability benefits are so great that we made this the new default
There is a set of new features coming for Marten in the next week around truly massive scalability of the event store for a JasperFx Software client but I didn’t want to hold up the Marten 9.0 release for that other than making some internal changes that will enable what we’re going to try to do.
Polecat 4.0
Polecat 4.0 benefits from all of the shared changes in the projections library with Marten and now shares far more internal guts with Marten. Polecat 4.1 that should be out before you read this post will also tighten up some error handling to be more consistent with proven patterns in Marten.
Wolverine 6.0
Wolverine 6.0 was a smaller release in terms of what users will notice. The release mostly revolved around the changes in the underlying dependencies, the AOT compliance, and cold start improvements. The runtime code generation with Roslyn is still there (and not going anywhere folks, not without Wolverine becoming a completely different tool anyway), but the JasperFx.RuntimeCompiler can now be just a development time dependency if you want so that you can have a much smaller deployed image. This again is part of the long standing plan to get around to having a better Serverless story for Wolverine.
I also smuggled in quite a bit of extra observability meant for CritterWatch, and we’ll hopefully show that off soon!
There’s a couple features still in the back log, with maybe an upcoming integration with job schedulers like Quartz.Net or TickerQ. Then a much bigger story for improving the usability of Wolverine with F# (more or less, being able to generate F# code instead of C# code).
JasperFx and Weasel
The baseline JasperFx, JasperFx.Events, and their related source generators flipped over to 2.0. Again, the goals where AOT compliance and improvements to the source generators for Marten & Polecat’s projection support. There was quite a bit of work smuggled into this layer as well for CritterWatch.
Weasel 9.0 did go through an effort to reduce code duplication across the different database engines that it supports, but otherwise just dropped .NET 8.0 and added a little bit of work meant for CritterWatch down the line (dynamic tenancy management).
This is in lieu of the “official” release post I’ll make early next week after the Memorial Day holiday when I have enough rest and energy to do something much better by hand. Until then, here’s a peek at the new releases we’ll be announcing early next week — but with some published updates to our AI Skills tomorrow morning that will help you do the migrations!
The whole stack just shipped to NuGet — a coordinated major release across every Critter Stack project, built on a shared JasperFx 2.0 foundation and targeting .NET 9 + .NET 10. Headline themes: AOT-friendly, faster cold-start, and Marten ↔ Polecat dedupe onto shared infrastructure.
(Quick notes for now — a full writeup written by an actual human being with benchmarks lands next week.)
JasperFx 2.0 (foundation)
The shared base for the whole stack — also ships JasperFx.Events 2.0 + JasperFx.RuntimeCompiler 5.0.
AOT-compatible core; runtime Roslyn split into JasperFx.RuntimeCompiler so Static-mode apps drop it and the trimmer removes Roslyn.
Source generators for projection dispatch (FEC-free), CLI command discovery, and options descriptions — less runtime reflection.
Database-primitive foundation on JasperFx 2.0; the consolidation home for IStorageOperation, OperationRole, BulkInsertMode, and the SQL Server advisory lock (dedupe pillar).
Postgres / SQL Server / Sqlite / MySql / Oracle / EF Core providers, all 9.0.0.
No more runtime code generation — Roslyn is gone. Closed-shape document/event storage + Marten.SourceGenerator compiled queries. No codegen write step for Marten; AOT-publishable in Static mode.
Best-perf defaults flipped on: Quick append w/ server timestamps, advanced async tracking, bigint events, lightweight sessions, System.Text.Json. One-line revert with opts.RestoreV8Defaults().
IRevisioned.Version stays int (V8-compatible); new ILongVersioned for long. DCB gains optional HSTORE tag storage + identity-less boundary aggregates.
SQL Server / EF Core-rooted event sourcing on the shared foundation — source-generator-first and AOT-clean end to end.
Adopted the lifted JasperFx.Events async-daemon abstractions; folded SqlServerAppLock into Weasel.SqlServer.AdvisoryLock; SingleTenant lock-ids now align with Marten.
⚠️ Runtime codegen decoupled from core. Apps in the default Dynamic mode must add WolverineFx.RuntimeCompilation (dev/test), or pre-generate via codegen write + Static mode (prod). This is the #1 upgrade gotcha — see the migration guide.
⚠️ ServiceLocationPolicy.NotAllowed is the new default — restructure registrations or call opts.RestoreV5Defaults() to revert.
AOT-clean; Tier-1 cold-start static handler registry. Newtonsoft extracted to WolverineFx.Newtonsoft; IForwardsTo<T> discovery is now explicit.
Upgrading? Bump the whole stack in lockstep — JasperFx 2.0 / Weasel 9.0 / Marten 9.0 / Polecat 4.0 / Wolverine 6.0. Each migration guide above has an at-a-glance table of breaking changes. The big perf/benchmark writeup is coming next week. 🚀
Babu Annamalai and I have been working very hard on JasperFx Software‘s officially curated AI Skills for the “Critter Stack,” and I’m very pleased to announce today that these skills are officially open for business! Many of our support clients already have access, but as of today anyone interested is able to purchase access to the skills online at https://jasperfx.net/our-products/#ai-skills.
And these skills will be curated, meaning that we’ll work to continuously improve and add to the skills. As a matter of fact, there will be a new revision as early as tomorrow to provide AI assisted conversions to the next major releases of Marten, Polecat, and Wolverine.
Pardon the mess, but the Critter Stack 2026 releases are heavily underway in the JasperFx GitHub Organization. Busy enough that I am getting hit with GitHub rate limiting messages the past couple days and I think that’s a good sign about our productivity? It’s also blessedly coincided with a couple very quiet days in the community which has certainly helped too!
Optimize the “cold start” times across the entire stack, have a better story for “Serverless” usage and, knock on wood, get to AOT compliance. To be clear, this will change the pattern of our previous Roslyn runtime compilation into a development time only thing where pre-generation of Wolverine or Marten types will be mandatory for production usage. And that’s the part I expect to be a little bit controversial or inconvenient.
Bring Polecat up to par quality wise with Marten. Polecat has had growing pains.
Adjusting some of our default settings to reflect more optimized usage for greenfield usage, which I mostly outlined in this post. But don’t worry, all of this will be documented in the migration guide, Marten will have a RestoreV8Defaults() and Wolverine is getting a RestoreV5Defaults() to make it easier to stay right were you are. Some of this is getting driven by real efficiency concerns, and other parts are purposely meant to enable CritterWatch management and oversight of production applications.
CritterWatch 1.0 – Our white whale, our “Duke Nukem Forever” release, “Winds of Winter” finally coming out so we can find out if Jon Snow survives! Add in Half Life 3 too. No seriously, it’s coming out on May 18th come hell or the river don’t rise.
For some other details:
There’s plenty of low level performance optimization and object allocation savings happening, but I don’t yet have numbers to know how much difference that’s going to make yet. We will be doing much more benchmarking before the release though
We’re pulling Newtonsoft references out of the main tools altogether, but replacing the integration with extra extension packages. That feels like the end of an era!
We’ll do the inevitable work of eliminating [Obsolete] APIs, but I don’t think there’s much
We’re doing a huge amount of work to promote code sharing between Marten and Polecat, with me hoping that that improves Polecat especially. Some of that is driven by CritterWatch needs. This is also happily reducing code duplication throughout the Wolverine codebase as well.
.NET 8 support was dropped, but we’re maintaining .NET 9 and .NET 10 for the lifetime of these versions. I realize that .NET 9 is EOL later this year, but I’m not eager to get yelled at for dropping it earlier than some of our users. We’ll add .NET 11 whenever that hits. For anyone wondering why this is a big deal at all, our usage of EF Core means that we do struggle somewhat with diamond dependency conflicts through major .NET versions.
Marten is getting a more efficient option for “Dynamic Consistency Boundaries” (DCB) using PostgreSQL HSTORE
There was also a big time round of code de-duplication in Weasel across the database engines that we support
Migration?
Other than some changes to the shape of our MultiStreamProjection types in Marten and Polecat, I’m expecting no other breaking changes except for some public types moving namespaces. I’m confident this time around that we’ll have a comprehensive migration guide that will cover all of those moves in a form that should be helpful for both humans or LLM tools.
If you utilize the new defaults though, there will be database migrations for extra fields and new tables that have been added in the past year or two for enhanced auditing and observability — but all of this will be purely additive.
This post is ostensibly about a sample usage of Wolverine middleware, but I’m going to meander a bit.
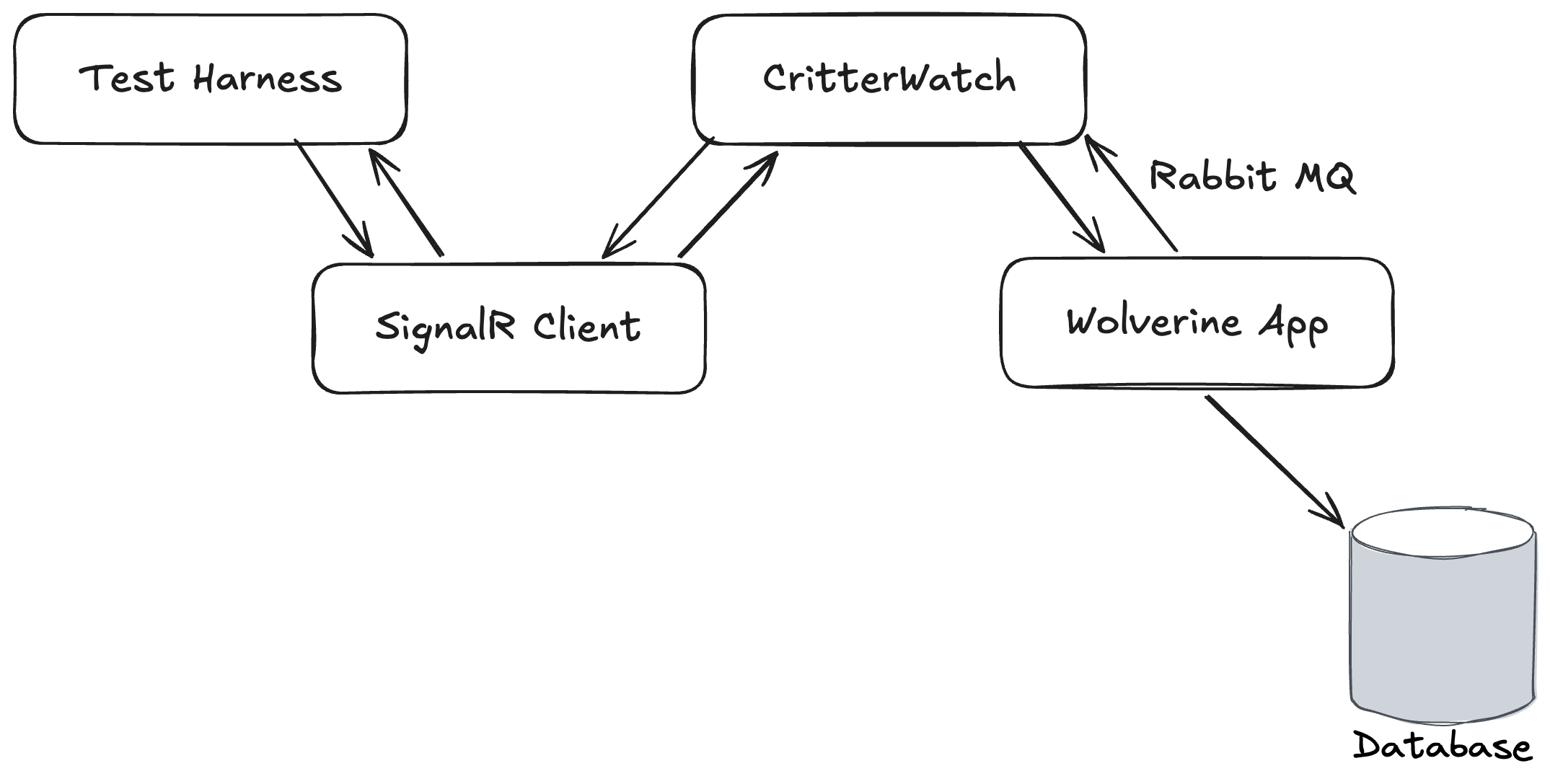
I’m working pretty hard this week trying to make some serious progress on CritterWatch, our long planned production monitoring and management console for the “Critter Stack.” At one point late in the day I was working to troubleshoot some failing tests in the CritterWatch codebase with a harness like this:
CritterWatch itself and a test Wolverine application were both running in memory as separate IHost instances. CritterWatch heavily utilizes the Wolverine SignalR messaging transport for communication between its Vue.js based user interface and the CritterWatch server. Part of Wolverine’s SignalR integration is a SignalR Client Transport option that makes it easy for us to use WebSockets communication in integration tests to mimic the client, but live completely in the world of strong typed C# objects.
The integration tests in question were trying to:
Send a message through the SignalR client to mimic commands from the user interface
Which would be relayed from CritterWatch to the right monitored Wolverine service
Which would execute a command against its database, then send a response message back to CritterWatch
Which would relay that response message right back to the original caller through SignalR
The test was failing in a very annoying way by timing out waiting for the ultimate response message to come all the way back with no real feedback about why it was failing.
More on this in a bit, but some of the handler code and automated testing code was written somewhat naively by AI agents and I have some thoughts.
As I wrote about recently in On Debugging Problems, I frequently start debugging efforts by formulating a theory about the most likely cause of the problem and trying to take a quick way to either prove or disprove that theory. This time I happened to be exactly right as I found this code:
After dithering back and forth on this, we landed on the idea of making CritterWatch a “freemium” model where all the advanced features require an installed license and I retrofitted the license protection with a little bit of help from my friend Claude — and wouldn’t you know it, in all the constant sprinting on the user interface, the test harness didn’t have a license applied so it could test through the message handler above. Easy fix to bring the tests back to green, but I wanted to improve the license guard usage by utilizing Wolverine middleware and that might be a great example for a blog post!
Then I remembered that the way that message handler is built completely sidesteps Wolverine middleware, so hold that thought.
The first problem was that we weren’t getting any obvious indication in the test harness that the test was failing because the license file wasn’t applied during tests. That’s an easy thing to fix by just changing the guard clause to this:
if (!LicenseGuard.IsOperationAllowed())
{
thrownewLicenseRequiredException();
}
And a bit of corresponding error handling configuration for Wolverine to know to discard these messages rather than let them go to the dead letter queue or waste any time retrying:
By throwing an exception — and I’m not too worried about using an exception here for flow control because after all, you’re doing something naughty if you manage to hit that message handler — I knew that would be automatically written out to any test failures with the Wolverine tracked session testing helpers that these tests were using even though the exceptions are happening in asynchronous message handling and would be handled internally by Wolverine.
The key point here is that it is very often important in your test automation strategy to think about how you can report contextual information about test failures that will help developers troubleshoot said failures.
Alright, so let’s pretend that I’m working with normal Wolverine message handlers and middleware strategies are available. In that case I can get the license guard out of the message handler code as a cross cutting concern. A way to do that is to design a new [RequiresLicense] attribute that will add middleware for the license guard to any handler class or method decorated with that attribute. Here’s the Wolverine flavor of that strategy:
With that attribute marking up either the handler class or the main message handler method, Wolverine is going to do some “code weaving” so that this line of code will appear on the first line of in the generated code that Wolverine builds around your handler code:
Just to make sure this is clear, Wolverine does not use any kind of Reflection at runtime but instead “bakes” the middleware application in on the first usage of the handler or even completely ahead of time in production usage.
Wolverine’s Configuration vs Runtime Model
It’s admittedly a goofy model that is quite different than basically every other “Russian Doll” tool out there where there’s usually some kind of wrapping model like MediatR’s IPipelineBehavior<TRequest, TResponse>. Wolverine’s model was intentionally designed to avoid the bloated object allocations that tools like MediatR accidentally cause when folks get a little slap happy with middleware usage. Wolverine’s model is also designed to minimize the dreadful exception stack traces that many application frameworks that support middleware create for you by doing so much object wrapping and delegation *cough* ASP.Net Core *cough*.
I had an extremely popular professor in college for all our heat transfer classes who had a legendary drinking game that had been passed down for generations (if Dr. Chapman gets chalk on his pants, take a drink). If there was a drinking game for me, it would be “if Jeremy quotes the original C2 Wiki or links to a Martin Fowler post…”
Wolverine’s middleware strategy also varies quite a bit from a MediatR or most other is our usage of an internal “Semantic Model” that is built up at configuration and bootstrapping time, then compiled into a runtime model:
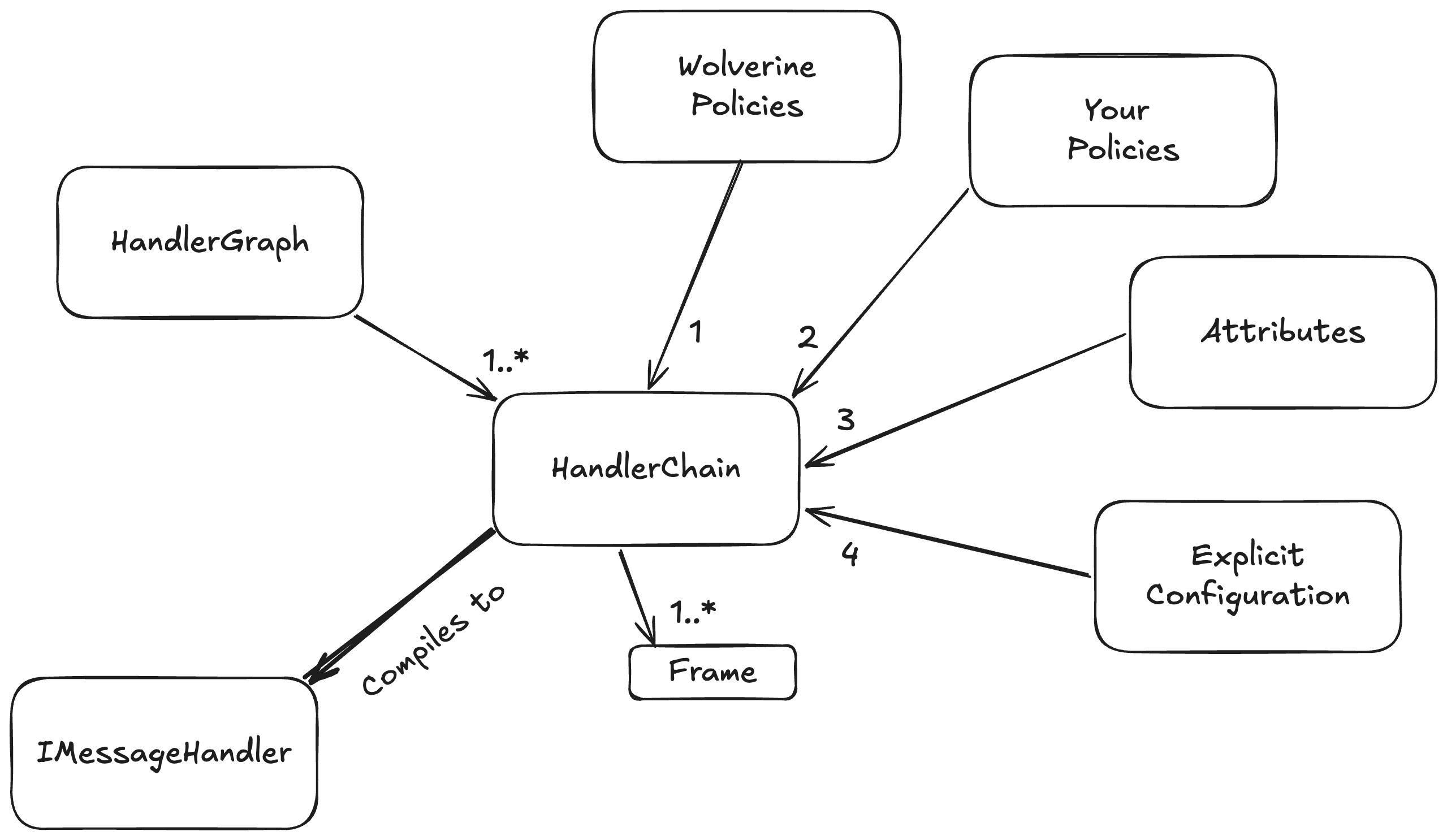
At bootstrapping time, we build up a configuration model for how every discovered message handler or HTTP endpoint method will be handled. That same model also models the application of middleware, post processors, error handling for message handlers, and a ton of HTTP specific elements for each message handler or HTTP endpoint. In order, the configuration is built up by:
Built in Wolverine policies like “an HTTP endpoint method that returns a string will write out content type text/plain go first
User defined policies go next, and can override anything from the Wolverine policies
Attributes on the message handler or HTTP endpoint type and method apply individual overrides on specific message handlers or HTTP endpoint handling. We do this through the base ModifyChainAttribute or ModifyHttpChainAttribute classes that expose a method that directly modifies the HandlerChain configuration model for each message handler or likewise the HttpChain model for an HTTP endpoint. Attributes of course win out over policies
Lastly, Wolverine has a way to expose direct manipulation of the underlying HandlerChain model for individual handlers, and the more explicit mechanisms always win out over any kind of policies
This HandlerChain model is also built up with knowledge of your application’s IoC container and through that, the dependencies of any given message handler or HTTP endpoint method. Wolverine can use this to selectively apply middleware. For example:
Wolverine’s Fluent Validation middleware doesn’t apply if there are no matching validators for a message type and can effectively inline a single or collection of validators otherwise. No runtime probing of the IoC containers like you see in many validation middleware approaches out there
In a system using multiple EF Core DbContext types, Wolverine can choose the right one for a given Saga type and generate the most efficient code possible to use that DbContext without having to use any kind of wrappers or runtime IoC tricks
In a system that uses both EF Core and Marten, Wolverine can tell from the dependencies of a single handler if it should use Marten based or EF Core based transactional middleware
The key point here is that the “Semantic Model” usage and the way we do configuration in Wolverine allows you a great deal of control over the application of middleware in a fine grained way and this is frequently valuable.
NServiceBus also has their BehaviorGraph concept that is the same “Semantic Model” concept I’m discussing here that allows either Wolverine or NServiceBus users to fine tune the application of middleware to specific messaging handlers based on user or framework defined conventions. The similarity is not the slightest bit coincidental because NServiceBus’s model was taken from FubuMVC that was the spiritual predecessor of Wolverine.
About the AI Thing
Ages ago I read a quote from Martin Fowler (take a drink) something to the effect of:
The only way to know how far a new tool or technique can go is to take it too far, then back off a bit
I’m in my “back off” phase for AI assisted development after feeling completely blown away at first by how much I was able to accomplish. Up above, I explained that I ran into some trouble because of code written naively by AI that I had not reviewed well enough. I’ve also been the victim or perpetrator of several AI coding related problems in the past couple months alone that have let regression bugs slip out into the wild.
I don’t think that anybody is going all the way back to coding completely by hand, but for my part, I think that AI tempts you into trying to develop faster than you should and that you need to exert more control over the code than I apparently had before this week. I guess my only main takeaway is to slow down, not make too many risky changes just because an AI tool made it easy, and if you are responsible for code used by other people, make sure you have eyeballs on it.
I miss long form blogging
If you’ll allow me a little diversion, I used to enjoy technical blogging when that was the way that developers communicated online. Before social media took off, I would take time to formulate and craft a blog post to explain some idea I had or to share something I’d learned that I self importantly thought other developers should know too. At one point I had an hour and change commute on a train every morning, and used to occasionally write a series of mini essays I called a “Train of Thought” for topics that were on my mind but not worthy of a long form blog post by themselves. As I thought tonight about writing up a little blog post sample of Wolverine middleware, it occurred to me that that was going to touch on several other topics and that reminded me of that magic little time when I enjoyed writing technical blog posts.
Then came Twitter of course, and that acted as a release valve that let you blurt things out without ever building up a cohesive, long form post and everything changed forever. Now, of course, what was Twitter isn’t nearly as important, there’s basically no technical content on BluSky, Mastodon has “Linux on the Desktop” energy, and LinkedIn posts are nothing but non stop self-promotion. Younger developers are on Twitch or cranking out YouTube videos. I still blog, but I’m admittedly almost completely focused on promoting the “Critter Stack” tools or JasperFx Software and it’s not the same at all. For what it’s worth, I enjoyed just sitting down tonight and trying to write something by hand.
I spent some time yesterday writing and thinking about the road map for the Critter Stack. Call this post a mix of me sorting out what I personally think happens next, but mostly asking for feedback and input on these thoughts.
Wrapping up Marten 8 and Wolverine 5
I think we’re pretty close to turning the page on the current versions of Marten and Wolverine. I made a housecleaning effort yesterday to either deal with any outstanding issues or pull requests against the current versions, or to tag issues for the next major milestone.
To that end, a new Marten 8.34 and Wolverine 5.34 release dropped this morning that I’m going to say symbolically marks the current versions of both tools as “done.”
Of course, software tools are never actually completed, only abandoned. At this point though, I think the only enhancements to these versions will be merely reacting to reported issues or client requests that don’t require any breaking changes (or changes for CritterWatch). We’re certainly happy to continue taking in community pull requests, but at least for me, I’m out of any ideas for new functionality right now.
I also snuck in quite a few minor improvements for the “cold start” with both tools, and that’s going to be a theme of this post.
And I know full well that between the time I write this and you read it that there will be some new kind of bug report like “if I hop up and down on my left foot while pointing at the Big Dipper, I would have expected…” to land. Which we’ll address of course:)
CritterWatch and JasperFx Update
Just speaking personally, I should be putting the majority of my time for awhile pushing CritterWatch to a 1.0 release. We’re also working toward having all the infrastructure in place to allow customers to purchase licensing for CritterWatch and access to our new AI Skills collection on our website. Babu and I have also been very busy doing a complete overhaul of the JasperFx Software website.
At a bare minimum, I’m hoping to have every single bit of functionality in flight today for CritterWatch in a usable and somewhat polished state by the end of this week.
While the sales mechanisms aren’t completely in place yet, you can see the updated pricing online now.
And just so everybody knows, CritterWatch will be available on Nuget, but only usable in a read only way without the presence of a license file.
On to the next cycle!
The next big set of releases will be Marten 9, Wolverine 6, and Polecat 3. The key goals for me are to do everything possible to improve the “cold start” performance of Marten, Wolverine, and Polecat to make our tools much more usable in “serverless” usage and to attempt to ruthlessly remove duplication today between Marten and Polecat.
The big ticket and potentially breaking changes are to:
Move JasperFx.RuntimeCompiler and its massive dependency on Roslyn to being a development time dependency. We’ve already got a plan underway to allow you to deploy Marten and/or Wolverine applications (Polecat strictly uses source generators instead of our older code generation model) without that dependency so that we can actually do…
AOT Compliance. I didn’t think this was ever going to be possible before, but it looks like we can pull this off
We’re going to make a large effort to switch default configurations of the tools to reflect the absolute best performing and monitored application you can have. See Building a Greenfield System with the Critter Stack for plenty examples of the settings I mean. We introduced quite a few improvements to both Marten and Wolverine over the past year that we made “opt in” because using them would require database schema changes. A new major release is always the time to reconsider those defaults. I’m also hoping that AI tools make the converstions and upgrades a lot easier even with these kinds of changes to behavior.
Dump [Obsolete] APIs of course, but I don’t think there are too many of those floating around anymore
Drop support for .NET 8, then add support for .NET 11 when that hits later this year. If nothing else, our EF Core support is a nightmare for diamond dependency problems and our multi-targeting makes that much worse. Fewer .NET versions leads to fewer headaches.
Try hard to eliminate duplication between Marten and Polecat, with more utility and infrastructure code landing in JasperFx.Events or Weasel.Core. I’m hoping that this work would shrink the Marten codebase especially, and open up some opportunities to reduce duplication in Wolverine too. I’m also hopeful that this elimination of duplication can lead to more advanced visualizations and tracking in CritterWatch.
JasperFx will be working with a client this year for some pretty extreme scalability of the Event Store features in Marten. As part of that, I would like us to pursue using the HSTORE extension in PostgreSQL for more efficient “Dynamic Consistency Boundary” usage and to also pursue using alternative serializers for just event data as some early experimentation with MemoryPack inside of Marten has been very promising.
And just in case anyone asks, I don’t think it’s remotely possible to convert Wolverine to use source generators instead of our current source code generation model.
Bobcat?
This is my rough notes here, so don’t take any of this too seriously.
I haven’t talked about this much, but I’ve been playing a bit with a new Gherkin test runner tentatively called “Bobcat” half inspired by Storyteller (https://storyteller.github.io). What’s different about Bobcat from Reqnroll is much more focus on data intensive testing, and making it more CLI friendly purposely to create visibility on runtime activity so AI agents could iterate on the test execution results. This is my current thinking for “Spec Driven Development” w/ the Critter Stack as opposed to a quixotic attempt to do anything with user interface centric tooling.
So for example, if your spec calls through the Wolverine tracked sessions, the test output would have information about every exception encountered and the full messaging history on test failures. The test output itself is written to the CLI too where AI tools can scrape it.
I’ve already played w/ built in helper packages for Alba and the Wolverine tracked sessions. Also trying to think through how Bobcat could be optimized for real integration testing where you have to juggle Docker dependencies and `IHost` lifecycles.
To some degree, Bobcat is maybe just what I’ve always wanted to test the Critter Stack tools themselves.
I’m also thinking about how to make Bobcat + AI skills drive Spec Driven Development w/ the Critter Stack. So accelerators build the Gherkin runners based on event types and projection types. Then being able to generate code from the Gherkin specs. I’ve been watching a couple other event sourcing toolsets and how they’re trying to do Access 97 style user interfaces to “model” event sourcing workflows and have yet to see anything out there that would be faster than just writing C# or F# event types and maybe even the projection types themselves. My thought is just to lean on our existing code tools and build generators to quickly translate from C#/F# types to Gherkin syntax. I’m also hoping we can leverage the existing Gherkin language integration in Rider or VS Code rather than building something all new.
And lastly, I’m not opposed to trying to make this work with Reqnroll in the end.
Before you read any of this, just know that it’s perfectly possible to mix and match Wolverine.HTTP, MVC Core controllers, and Minimal API endpoints in the same application.
Edit: The documentation links were all wrong when I pushed this late at night of course, so:
If you’ve built ASP.NET Core applications of any size, you’ve probably run into the same friction: MVC controllers that balloon with constructor-injected dependencies, or Minimal API handlers that accumulate scattered app.MapGet(...) calls across multiple files. And if you’ve reached for a Mediator library to impose some structure, you’ve added a layer of abstraction that — while familiar — brings its own ceremony and a seam that can make unit testing harder than it should be.
Wolverine.HTTP is a different model. It’s a first-class HTTP framework built on top of ASP.NET Core that’s designed from the ground up for vertical slice architecture, has built-in transactional outbox support, and delivers a middleware story that is arguably more powerful than IEndpointFilter. And it doesn’t need a separate “Mediator” library because the Wolverine HTTP endpoints very naturally support a “Vertical Slice” style without so many moving parts as the average “check out my vertical slice architecture template!” approach online.
Moreover, Wolverine.HTTP has first class support for resilient messaging through Wolverine’s transactional outbox and asynchronous messaging. No other HTTP endpoint library in .NET has any such smooth integration.
What Is Vertical Slice Architecture?
The core idea is organizing code by feature rather than by technical layer. Instead of a Controllers/ folder, a Services/ folder, and a Repositories/ folder that all have to be navigated to understand one feature, you co-locate everything that belongs to a single use case: the request type, the handler, and any supporting types.
The payoff is locality. When a bug is filed against “create order”, you open one file. When a feature is deleted, you delete one file. There’s no hunting across layers.
Wolverine.HTTP is a natural fit for this style. A Wolverine HTTP endpoint is just a static class — no base class, no constructor injection, no framework coupling. The framework discovers it by scanning for [WolverineGet], [WolverinePost], [WolverinePut], [WolverineDelete], and [WolverinePatch] attributes.
And because of the world we live in now, I have to mention that there is already plenty of anecdotal evidence that AI assisted coding works better with the “vertical slice” approach than it does against heavily layered approaches.
Getting Started
Install the NuGet package:
dotnet add package WolverineFx.Http
Wire it up in Program.cs:
varbuilder=WebApplication.CreateBuilder(args);
builder.Host.UseWolverine();
builder.Services.AddWolverineHttp();
varapp=builder.Build();
app.MapWolverineEndpoints();
returnawaitapp.RunJasperCommands(args;
A Complete Vertical Slice
Here’s what a full feature slice looks like with Wolverine.HTTP. Request type, response type, and handler all in one place:
// The request
publicrecordCreateTodo(stringName);
// The response
publicrecordTodoCreated(intId);
// The handler — a plain static class, no base class required
publicstaticclassCreateTodoEndpoint
{
[WolverinePost("/todoitems")]
publicstaticasyncTask<IResult>Post(
CreateTodocommand,
IDocumentSessionsession) // injected by Wolverine from the IoC container
Compare that to what this would look like in MVC Core with a service layer and constructor injection. The Wolverine version is shorter, has no framework coupling in the handler method itself, and every dependency is explicit in the method signature. There’s no hidden state, and the method is trivially unit-testable in isolation.
No controller. No service interface. No repository abstraction. Just the feature.
No Separate Mediator Needed
One of the most common patterns in .NET vertical slice architecture is using a Mediator library like MediatR to dispatch commands from controllers to handlers. Wolverine makes this unnecessary — it handles both HTTP routing and in-process message dispatch with the same execution pipeline.
If you’re coming from MediatR, the key difference is that there’s no IRequest<T> base type to implement, no IRequestHandler<TRequest, TResponse> to wire up, and no _mediator.Send(command) call to thread through your controllers. The HTTP endpoint is the handler. When you also want to dispatch a message for async processing, you just return it from the method (more on that below).
Here is where Wolverine.HTTP really pulls ahead. In any event-driven architecture, HTTP endpoints frequently need to do two things atomically: save data to the database and publish a message or event. If you do these as two separate operations and something crashes between them, you’ve lost a message — or worse, written corrupted state.
The standard solution is a transactional outbox: write the message to the same database transaction as the data change, then have a background process deliver it reliably.
With plain IMessageBus in a Minimal API handler, you’re responsible for the outbox mechanics yourself. With Wolverine.HTTP, the outbox is automatic. Any message returned from an endpoint method is enrolled in the same transaction as the handler’s database work.
The simplest pattern uses tuple return values. Wolverine recognizes any message types in the return tuple and routes them through the outbox:
publicstaticclassCreateTodoEndpoint
{
[WolverinePost("/todoitems")]
publicstatic (Todotodo, TodoCreatedcreated) Post(
CreateTodocommand,
IDocumentSessionsession)
{
vartodo=newTodo { Name=command.Name };
session.Store(todo);
// Both the HTTP response (Todo) and the outbox message (TodoCreated)
// are committed in the same transaction. No message is lost.
return (todo, newTodoCreated(todo.Id));
}
}
The Todo becomes the HTTP response body. The TodoCreated message goes into the outbox and is delivered durably after the transaction commits. The database write and the message write are atomic — no coordinator needed.
If you need to publish multiple messages, use OutgoingMessages:
All four database and message operations commit together. This is the kind of correctness that is genuinely difficult to achieve with raw IMessageBus calls in Minimal API, and it comes for free in Wolverine.HTTP.
Middleware: Better Than IEndpointFilter
ASP.NET Core Minimal API introduced IEndpointFilter as its extensibility hook — a way to run logic before and after an endpoint handler. It works, but it has a few rough edges: you write a class that implements an interface with a single InvokeAsync method that receives an EndpointFilterInvocationContext, and you have to dig values out by index or type from the context object. It’s not especially readable, and composing multiple filters is verbose.
Wolverine.HTTP’s middleware model is different. Middleware is just a class with Before and After methods that can take any of the same parameters the endpoint handler can take — including the request body, IoC services, HttpContext, and even values produced by earlier middleware. Wolverine generates the glue code at compile time (via source generation), so there’s no runtime reflection and no boxing.
Here’s a stopwatch middleware that times every request:
A middleware method can also return IResult to conditionally stop the request. If the returned IResult is WolverineContinue.Result(), processing continues. Anything else — Results.Unauthorized(), Results.NotFound(), Results.Problem(...) — short-circuits the handler and writes the response immediately:
This same pattern powers Wolverine’s built-in FluentValidation middleware — every validation failure becomes a ProblemDetails response with no boilerplate in the handler itself.
The IHttpPolicy interface lets you apply middleware conventions across many endpoints at once:
Wolverine.HTTP is built on top of ASP.NET Core, not around it. Every piece of standard ASP.NET Core middleware works exactly as you’d expect — Wolverine endpoints are just routes in the middleware pipeline.
Authentication and Authorization work via the standard [Authorize] and [AllowAnonymous] attributes:
The UseRateLimiter() call in the pipeline hooks standard ASP.NET Core rate limiting middleware, and the [EnableRateLimiting] attribute wires up the policy exactly as it does for Minimal API or MVC — no Wolverine-specific configuration required.
OpenAPI / Swagger Support
Wolverine.HTTP integrates with Swashbuckle and the newer Microsoft.AspNetCore.OpenApi package. Endpoints are discovered as standard ASP.NET Core route metadata, so Swagger UI works out of the box. You can use [Tags], [ProducesResponseType], and [EndpointSummary] to enrich the generated spec:
TL;DR: Wolverine has a pretty good development and production time story for developers using EF Core and that is constantly being improved.
Wolverine was explicitly restarted 3-4 years back specifically to combine with Marten as a complete end to end solution for Event Sourcing and CQRS with asynchronous messaging support. While that “Critter Stack” strategy has definitely paid off, vastly more .NET developers and systems are using EF Core as their primary persistence mechanism. And since I’d personally like to see Wolverine get much more usage and see JasperFx Software continue to grow, we’ve made a serious effort to improve the development time experience with EF Core and Wolverine.
I should say, that’s not expressly necessary, but all of the development time accelerators, middleware, and transactional inbox/outbox integration we’re about to utilize require that library.
Let’s just get started with a simple Wolverine bootstrapping configuration that is going to use a single EF Core DbContext (for now, Wolverine happily supports using multiple DbContext types in a single application) and SQL Server for the Wolverine message persistence we’ll need for transactional outbox support later:
// Adding EF Core transactional middleware, saga support,
// and EF Core support for Wolverine storage operations
opts.UseEntityFrameworkCoreTransactions();
});
// Rest of your bootstrapping...
With that in place, let’s look at a simple message handler that uses our ItemsDbContext:
publicstaticclassCreateItemCommandHandler
{
publicstaticItemCreatedHandle(
// This would be the message
CreateItemCommandcommand,
// Any other arguments are assumed
// to be service dependencies
ItemsDbContextdb)
{
// Create a new Item entity
varitem=newItem
{
Name=command.Name
};
// Add the item to the current
// DbContext unit of work
db.Items.Add(item);
// This event being returned
// by the handler will be automatically sent
// out as a "cascading" message
returnnewItemCreated
{
Id=item.Id
};
}
}
In the handler above, you’ll notice there’s no synchronous calls at all, and that’s because we’ve turned on Wolverine’s transactional middleware for EF Core that will handle the actual transaction management. You’ll also notice that we’re using Wolverine’s cascading messages syntax to kick out an ItemCreated domain event upon the successful completion of this handler. With the EF Core transactional middleware, that is also handling any integration with Wolverine’s transactional outbox for reliable messaging. Absolutely nothing else for you to do in that handler to enable any of that behavior, and we can shove off some of the typically ugly async/await mechanics into Wolverine itself while keeping our actual application behavior cleaner.
Now let’s go a little farther and utilize some Wolverine optimizations for our EF Core usage and change the service registration up above to this:
// If you're okay with this, this will register the DbContext as normally,
// but make some Wolverine specific optimizations at the same time
That version of the integration optimizes application performance by fine tuning the service lifetimes in a way that improves Wolverine’s internal usage of the DbContext type, and adds direct mappings for Wolverine’s internal inbox and outbox storage. By using a “Wolverine optimized DbContext” like this, Wolverine is able to improve your system’s performance by allowing EF Core to batch the SQL commands for your application code and Wolverine’s transactional outbox storage in a single database round trip — and that’s important because the single most common killer of performance in enterprise applications is database chattiness!
So that’s the bare bones basics, now let’s look at some recent improvements in Wolverine for…
Development Time Usage with EF Core
We’ve invested a lot of time recently in trying to make EF Core easier to work with at development time with Wolverine. Coming from Marten where our database migrations have an “it should just work” model that quietly configures the database to match your application configuration at runtime for quick iteration at development time.
With the Wolverine.EntityFrameworkCore library, you can get that same behavior with EF Core through this option:
// This will make Wolverine do any necessary database migration
// work happen at application startup
opts.Services.AddResourceSetupOnStartup();
});
To be clear, with this setup, you can change your EF Core mappings, then restart the application or an IHost in testing and your application will automatically detect any database differences from the configuration and quietly apply a patch for you on application startup. This enables a much faster iteration cycle than EF Core Migrations do in my opinion.
The Weasel docs go deeper on the diff engine, opt-outs, and how it handles schemas.
Another feature in Marten that our community utilizes very heavily is the ability to quickly reset the state of a database in tests. I’ve also occasionally used the Respawn library for the same kind of ability when developing closer to the metal of a relational database to do the same. In a recent version of Wolverine, we’ve added similar abilities to our EF Core support including a version of Marten’s IInitialData concept to help you reset data in tests:
The ResetAllDataAsync<T>() method will look through a DbContext object to see all the tables it maps to, and delete all the data in those tables. It does take into account foreign key relationships to order its operations. After the data is wiped out, each IInitialData<T> registered in your system will be applied to lay down baseline data.
While this feature will surely have to be enhanced if many people start using it, this is already helping us make the Wolverine internal EF Core testing a lot more reliable and easier to use.
Declarative Persistence with EF Core
The next usage is special to Wolverine. A lot of times in simpler HTTP endpoints or command handlers you simply need to load an entity by its identity or primary key. And frequently, you’ll need to apply some repetitive validation that the entity exists in the first place. For that common need, Wolverine has its declarative persistence helpers like the [Entity] attribute shown below that can automatically load an entity through EF Core by its identity on the incoming command type implied by some naming conventions like this sample below:
The mapping of the identity can be explicitly mapped as well of course, and the pre-generated code always reveals Wolverine’s behavior around handlers or HTTP endpoint methods.
In the code above, Wolverine “knows” that the ItemsDbContext persists both the BacklogItems and Sprint entities, so it’s generating code around your handler to load these entities through ItemsDbContext. We can also tell Wolverine to automatically stop handling or in HTTP usage return a 400 ProblemDetails response if either of the requested entities are missing in the database. This helps keep Wolverine handler or HTTP endpoint code simpler by eliminating asynchronous code and letting you write more and more business or workflow logic in pure functions that are easy to test.
In the code above, the EF Core transactional middleware is calling ItemsDbContext.SaveChangesAsync() for you, and the automatic EF Core change tracking will catch the change to the BacklogItem.
And now, I think this is cool, Wolverine has its own new mechanism to batch up the two queries above through a custom EF Core futures query mechanism so that the handler above can fetch both the BacklogItem and the Sprint entity in one database round trip.
But wait, there’s more!
At the risk of making this blog post way too long, here’s more ways that Wolverine can make EF Core usage more successful:
When you develop with Wolverine as your application framework, Wolverine is really trying to push you toward using pure functions for your main message handler or HTTP endpoint methods. Recently, I was reviewing a large codebase using Wolverine and found several message handlers that had to use a simple interface like this one just get the next assigned identifier:
(the real life handlers were a little more complicated than this because real code is almost always far more complex than the simplistic samples people like me use to demonstrate concepts)
Of course, the code above isn’t very difficult to understand conceptually and maybe it’s not worth the effort to write it any differently. But all the same, let me show you a Wolverine capability to customize the code generation to turn that handler method above into a synchronous pure function.
First off — and shockingly maybe for anybody who has seen me complain about these dad gum little things online — I want to introduce a little custom value type for the report id like this:
// You'd probably use something like Vogen
// on this too, but I didn't need that just
// for the demo here
publicrecordReportId(intNumber);
Just so we can use this little type to identify our Report entities:
publicclassReport(ReportIdId)
{
publicstringName { get; set; }
}
And next, what we want to get to is an HTTP endpoint signature that’s a pure function where the next ReportId is just poked in as a parameter argument:
Alright, so the next step is to teach Wolverine how to generate a ReportId automatically and relay that to handler or endpoint methods that express a need for that through a method parameter. As an intermediate step, let’s do this simply and say that we’re just using a PostgreSQL Sequence for the number (I think my client’s implementation was something meaningful and more complicated than this, but just go with it please).
Knowing that our application has this sequence:
builder.Services.AddMarten(opts=>
{
// Set the connection string and database schema...
// Create a sequence to generate unique ids for documents
And as usual, the generated code is an assault on the eyeballs, but if you squint and look for ReportId, you’ll see the generated code is executing our helper method to fetch the next report id value and pushing that into the call to our Handle() method.
Summary
I don’t know that this capability is something many teams would bother to employ, but it’s a possible way to simplify handler or endpoint code that hasn’t been previously documented very well. Wolverine itself uses this capability quite a bit for conventions.
What I think is more likely, I hope anyway, is that our continuing investment in AI Skills for the Critter Stack is that folks still get value out of these capabilities by either the AI skills recommending the usage upfront or helping people apply this later to continuously shrink the codebase and improve testability of the actual business logic and workflow code.
And because Wolverine has been such a busy project of the type that sometimes throws spaghetti up against the wall to see what sticks, there is another option for this kind of code generation customization you can see here in a sample that “pushes” DateTimeOffset.UtcNow into method parameters.
Lastly, we’re in the midst of an ongoing effort to improve the documentation across the JasperFx / Critter Stack family of projects and you can find more information about the code generation subsystem at https://shared-libs.jasperfx.net/codegen/.