Wolverine is part of the larger “Critter Stack” suite that provides a robust and productive approach to Event Driven Architecture approaches in the .NET ecosystem. Through its various elements provides an asynchronous messaging framework, an alternative HTTP endpoint framework, and yes, it can be used as just a “mediator” tool (but I’d recommend using Wolverine’s HTTP support directly instead of “Wolverine as MediatR”). What’s special about Wolverine is how much, much more it does to reduce project boilerplate, code ceremony, and the complexity of application code compared to other .NET messaging or “mediator” tools. We the Wolverine team and community would ask that you keep this in mind instead of strictly comparing Wolverine as an apples to apples analogue to other .NET frameworks.
The Wolverine community has been busy, and I was just able to publish a very large Wolverine 3.13 release this evening. I’m happily going to use this release as a demonstration of the health of Wolverine as an ongoing OSS project because it has:
Big new features from other core team members like Jakob Tikjøb Andersen‘s work with HTTP form posts and [AsParameters] support
A significant improvement in the documentation structure from core team member JT
An F# usability improvement from the Critter Stack’s de facto F# support owner nkosi23
New feature work sponsored by a JasperFx Software client for some specific needs, and this is important for the health of Wolverine because JasperFx support and consulting clients are directly responsible for making Wolverine and the rest of the Critter Stack be viable as a longer term technical choice
Quite a few improvements to the Kafka transport that were suggestions from newer community members who came to Wolverine in the aftermath of other tool’s commercialization plans
Pull requests that made improvements or fixed problems in the documentation website — and those kinds of little pull requests do make a difference and are definitely appreciated by myself and the other team members
New contributors, including Bjørn Madsen‘s improvements to the Pulsar support
Anyway, I’ll be blogging about some of the highlights of this new release starting tomorrow with our new HTTP endpoint capabilities that add some frequently requested features, but I wanted to get the announcement and some thanks out to the community first. And of course, if there’s any issues with the new release or old bits (and there will be), just ask away in the Critter Stack Discord server.
Wrapping Up
Large OSS project releases can sometimes become their own gravity source that sucks in more and more work when a project owner starts getting enamored of doing a big, flashy release. I’d strongly prefer to be a little more steady with weekly or bi-weekly releases instead of ever doing a big release like this, but a lot of things just happened to come in all at once here.
JasperFx Software has some contractural obligations to deliver Wolverine 4.0 soon, so this might be the last big release of new features in the 3.* line.
Work is continuing on the “Critter Stack 2025” round of releases, but we have finally got an alpha release of Marten 8 (8.0.0-alpha-5) that’s good enough for friendly users and core team members to try out for feedback. 8.0 won’t be a huge release, but we’re making some substantial changes to the projections subsystem and this is where I’d personally love any and all feedback about the changes so far that I’m going to try to preview in this post.
Just know that first, here are the goals of the projection changes for Marten 8.0:
Eliminate the code generation for projections altogether and instead using dynamic Lambda compilation with FastExpressionCompiler for the remaining convention-based projection approaches. That’s complete in this alpha release.
Expand the support for strong typed identifiers (Vogen or StronglyTypedId or otherwise) across the public API of Marten. I’m personally sick to death of this issue and don’t particularly believe in the value of these infernal things, but the user community has spoken loudly. Some of the breaking API changes in this post were caused by expanding the strong typed identifier support.
Better support explicit code options for all projection categories (single stream projections, multi-stream projections, flat table projections, or event projections)
Extract the basic event sourcing types, abstractions, and most of the projection and event subscription support to a new shared JasperFx.Events library that is planned to be reusable between Marten and future “Critter” tools targeting Sql Server first, then maybe CosmosDb or DynamoDb. We’ll write a better migration guide later, but expect some types you may be using today to have moved namespaces. I was concerned before starting this work for the 2nd time that it would be a time consuming boondoggle that might not be worth the effort. After having largely completed this planned work I am still concerned that this was a time consuming boondoggle and opportunity cost. Alas.
Some significant performance and scalability improvements for asynchronous projections and projection rebuilds that are still a work in progress
Alright, on to the changes.
Single Stream Projection
Probably the most common projection type is to aggregate a single event stream into a view of that stream as either a “write model” to support decision making in commands or a “read model” to support queries or user interfaces. In Marten 8, you will still use the SingleStreamProjection base class (CustomProjection is marked as obsolete in V8), but there’s one significant change that now you have to use a second generic type argument for the identity type of the projected document (blame the proliferation of strong typed identifiers for this), with this as an example:
// This example is using the old Apply/Create/ShouldDelete conventions
public class ItemProjection: SingleStreamProjection<Item, Guid>
{
public void Apply(Item item, ItemStarted started)
{
item.Started = true;
item.Description = started.Description;
}
public void Apply(Item item, IEvent<ItemWorked> worked)
{
// Nothing, I know, this is weird
}
public void Apply(Item item, ItemFinished finished)
{
item.Completed = true;
}
public override Item ApplyMetadata(Item aggregate, IEvent lastEvent)
{
// Apply the last timestamp
aggregate.LastModified = lastEvent.Timestamp;
var person = lastEvent.GetHeader("last-modified-by");
aggregate.LastModifiedBy = person?.ToString() ?? "System";
return aggregate;
}
}
The same Apply, Create, and ShouldDelete conventions from Marten 4-7 are still supported. You can also still just put those conventional methods directly on the aggregate type just like you could in Marten 4-7.
The inline lambda options are also still supported with the same method signatures:
So far the only different from Marten 4-7 is the additional type argument for the identity. Now let’s get into the new options for explicit code when either you just prefer that way, or your logic is too complex for the limited conventional approach.
First, let’s say that you want to use explicit code to “evolve” the state of an aggregated projection, but you won’t need any additional data lookups except for the event data. In this case, you can override the Evolve method as shown below:
public class WeirdCustomAggregation: SingleStreamProjection<MyAggregate, Guid>
{
public WeirdCustomAggregation()
{
ProjectionName = "Weird";
}
public override MyAggregate Evolve(MyAggregate snapshot, Guid id, IEvent e)
{
// Given the current snapshot and an event, "evolve" the aggregate
// to the next version.
// And snapshot can be null, just meaning it hasn't been
// started yet, so start it here
snapshot ??= new MyAggregate(){ Id = id };
switch (e.Data)
{
case AEvent:
snapshot.ACount++;
break;
case BEvent:
snapshot.BCount++;
break;
case CEvent:
snapshot.CCount++;
break;
case DEvent:
snapshot.DCount++;
break;
}
return snapshot;
}
}
I should note that you may want to explicitly configure what event types the projection is interested in as a way to optimize the projection when running in the async daemon.
Now, if you want to “evolve” a snapshot with explicit code, but you might need to do query some reference data as you do that, you can instead override the asynchronous EvolveAsync method with this signature:
public virtual ValueTask<TDoc?> EvolveAsync(TDoc? snapshot, TId id, TQuerySession session, IEvent e,
CancellationToken cancellation)
But wait, there’s (unfortunately) more options! In the recipes above, you’re assuming that the single stream projection has a simplistic lifecycle of being created, updated one or more times, then maybe being deleted and/or archived. But what if you have some kind of complex workflow where the projected document for a single event stream might be repeatedly created, deleted, then restarted? We had to originally introduce the CustomProjection mechanism to Marten 6/7 as a way of accommodating complex workflows, especially when they involved soft deletes of the projected documents. In Marten 8, we’re (for now) proposing reentrant workflows with this syntax by overriding the DetermineAction() method like so:
public class StartAndStopProjection: SingleStreamProjection<StartAndStopAggregate, Guid>
{
public StartAndStopProjection()
{
// This is an optional, but potentially important optimization
// for the async daemon so that it sets up an allow list
// of the event types that will be run through this projection
IncludeType<Start>();
IncludeType<End>();
IncludeType<Restart>();
IncludeType<Increment>();
}
public override (StartAndStopAggregate?, ActionType) DetermineAction(StartAndStopAggregate? snapshot, Guid identity,
IReadOnlyList<IEvent> events)
{
var actionType = ActionType.Store;
if (snapshot == null && events.HasNoEventsOfType<Start>())
{
return (snapshot, ActionType.Nothing);
}
var eventData = events.ToQueueOfEventData();
while (eventData.Any())
{
var data = eventData.Dequeue();
switch (data)
{
case Start:
snapshot = new StartAndStopAggregate
{
// Have to assign the identity ourselves
Id = identity
};
break;
case Increment when snapshot is { Deleted: false }:
if (actionType == ActionType.StoreThenSoftDelete) continue;
// Use explicit code to only apply this event
// if the snapshot already exists
snapshot.Increment();
break;
case End when snapshot is { Deleted: false }:
// This will be a "soft delete" because the snapshot type
// implements the IDeleted interface
snapshot.Deleted = true;
actionType = ActionType.StoreThenSoftDelete;
break;
case Restart when snapshot == null || snapshot.Deleted:
// Got to "undo" the soft delete status
actionType = ActionType.UnDeleteAndStore;
snapshot.Deleted = false;
break;
}
}
return (snapshot, actionType);
}
}
And of course, since *some* of you will do even more complex things that will require making database calls through Marten or maybe even calling into external web services, there’s an asynchronous alternative as well with this signature:
public virtual ValueTask<(TDoc?, ActionType)> DetermineActionAsync(TQuerySession session,
TDoc? snapshot,
TId identity,
IIdentitySetter<TDoc, TId> identitySetter,
IReadOnlyList<IEvent> events,
CancellationToken cancellation)
Multi-Stream Projections
Multi-stream projections are similar in mechanism to single stream projections, but there’s an extra step of “slicing” or grouping events across event streams into related aggregate documents. Experienced Marten users will be aware that the “slicing” API in Marten has not been the most usable API in the world. I think that even though it didn’t change *that* much in Marten 8, the “slicing” will still be easier to use.
First, here’s a sample multi-stream projection that didn’t change at all from Marten 7:
public class DayProjection: MultiStreamProjection<Day, int>
{
public DayProjection()
{
// Tell the projection how to group the events
// by Day document
Identity<IDayEvent>(x => x.Day);
// This just lets the projection work independently
// on each Movement child of the Travel event
// as if it were its own event
FanOut<Travel, Movement>(x => x.Movements);
// You can also access Event data
FanOut<Travel, Stop>(x => x.Data.Stops);
ProjectionName = "Day";
// Opt into 2nd level caching of up to 100
// most recently encountered aggregates as a
// performance optimization
Options.CacheLimitPerTenant = 1000;
// With large event stores of relatively small
// event objects, moving this number up from the
// default can greatly improve throughput and especially
// improve projection rebuild times
Options.BatchSize = 5000;
}
public void Apply(Day day, TripStarted e)
{
day.Started++;
}
public void Apply(Day day, TripEnded e)
{
day.Ended++;
}
public void Apply(Day day, Movement e)
{
switch (e.Direction)
{
case Direction.East:
day.East += e.Distance;
break;
case Direction.North:
day.North += e.Distance;
break;
case Direction.South:
day.South += e.Distance;
break;
case Direction.West:
day.West += e.Distance;
break;
default:
throw new ArgumentOutOfRangeException();
}
}
public void Apply(Day day, Stop e)
{
day.Stops++;
}
}
The options to use conventional Apply/Create methods or to override Evolve, EvolveAsync, DetermineAction, or DetermineActionAsync are identical to SingleStreamProjection.
Now, on to a more complicated “slicing” sample with custom code:
public class UserGroupsAssignmentProjection: MultiStreamProjection<UserGroupsAssignment, Guid> { public UserGroupsAssignmentProjection() { CustomGrouping((_, events, group) => { group.AddEvents<UserRegistered>(@event => @event.UserId, events); group.AddEvents<MultipleUsersAssignedToGroup>(@event => @event.UserIds, events);
return Task.CompletedTask; }); }
I know it’s not that much simpler than Marten 8, but one thing Marten 8 is doing is handling tenancy grouping behind the scenes for you so that you can just focus on defining how events apply to different groupings. The sample above shaves 3-4 lines of code and a level or two of nesting from the Marten 7 equivalent.
EventProjection and FlatTableProjection
The existing EventProjection and FlatTableProjection models are supported in their entirety, but we will have a new explicit code option with this signature:
public virtual ValueTask ApplyAsync(TOperations operations, IEvent e, CancellationToken cancellation)
And of course, you can still just write a custom IProjection class to go straight down to the metal with all your own code, but that’s been simplified a little bit from Marten 7 such that you don’t have to care about whether it’s running Inline or in Async lifetimes:
public class QuestPatchTestProjection: IProjection
{
public Guid Id { get; set; }
public string Name { get; set; }
public Task ApplyAsync(IDocumentOperations operations, IReadOnlyList<IEvent> events, CancellationToken cancellation)
{
var questEvents = events.Select(s => s.Data);
foreach (var @event in questEvents)
{
if (@event is Quest quest)
{
operations.Store(new QuestPatchTestProjection { Id = quest.Id });
}
else if (@event is QuestStarted started)
{
operations.Patch<QuestPatchTestProjection>(started.Id).Set(x => x.Name, "New Name");
}
}
return Task.CompletedTask;
}
}
What’s Still to Come?
I’m admittedly cutting this post short just because I’m a good (okay, not horrible) Dad and it’s time to do bedtime in a minute. Beyond just responding to whatever feedback comes in, there’s some more test cases for the explicit coding options, more samples to write for documentation, and a seemingly endless array of use cases for strong typed identifiers.
Beyond that, there’s still a significant effort to come with Marten 8 to try some performance and scalability optimizations for asynchronous projections, but I’ll warn you all that anything too complex is likely to land in our theoretical paid add on model.
So, yes, Wolverine overlaps quite a bit with both MediatR and MassTransit. If you’re a MediatR user, Wolverine just does a helluva lot more and we have an existing guide for converting from MediatR to Wolverine. For MassTransit (or NServiceBus) users, Wolverine covers a lot of the same asynchronous messaging framework use cases, but does much, much more to simplify your application code than any other .NET messaging framework and should not be compared as an apples to apples messaging feature comparison. And no other tool in the entire .NET ecosystem can come even remotely close to the Critter Stack’s support for Event Sourcing from soup to nuts.
It’s kind of a big day in .NET OSS news with both MediatR and MassTransit respectively announcing moves to commercial licensing models. I’d like to start by wishing the best of luck to my friends Jimmy Bogard and Chris Patterson respectively with their new ventures.
As any long term participant in or observer of the .NET ecosystem knows, there’s about to be a flood of negativity from various people in our community about these moves. There will also be an outcry from a sizable cohort in the .NET community who seem to believe that all development tools should be provided by Microsoft and that only Microsoft can ever be a reliable supplier of these types of tools while somehow suffering from amnesia about how Microsoft has frequently abandoned high profile tools like Silverlight or WCF.
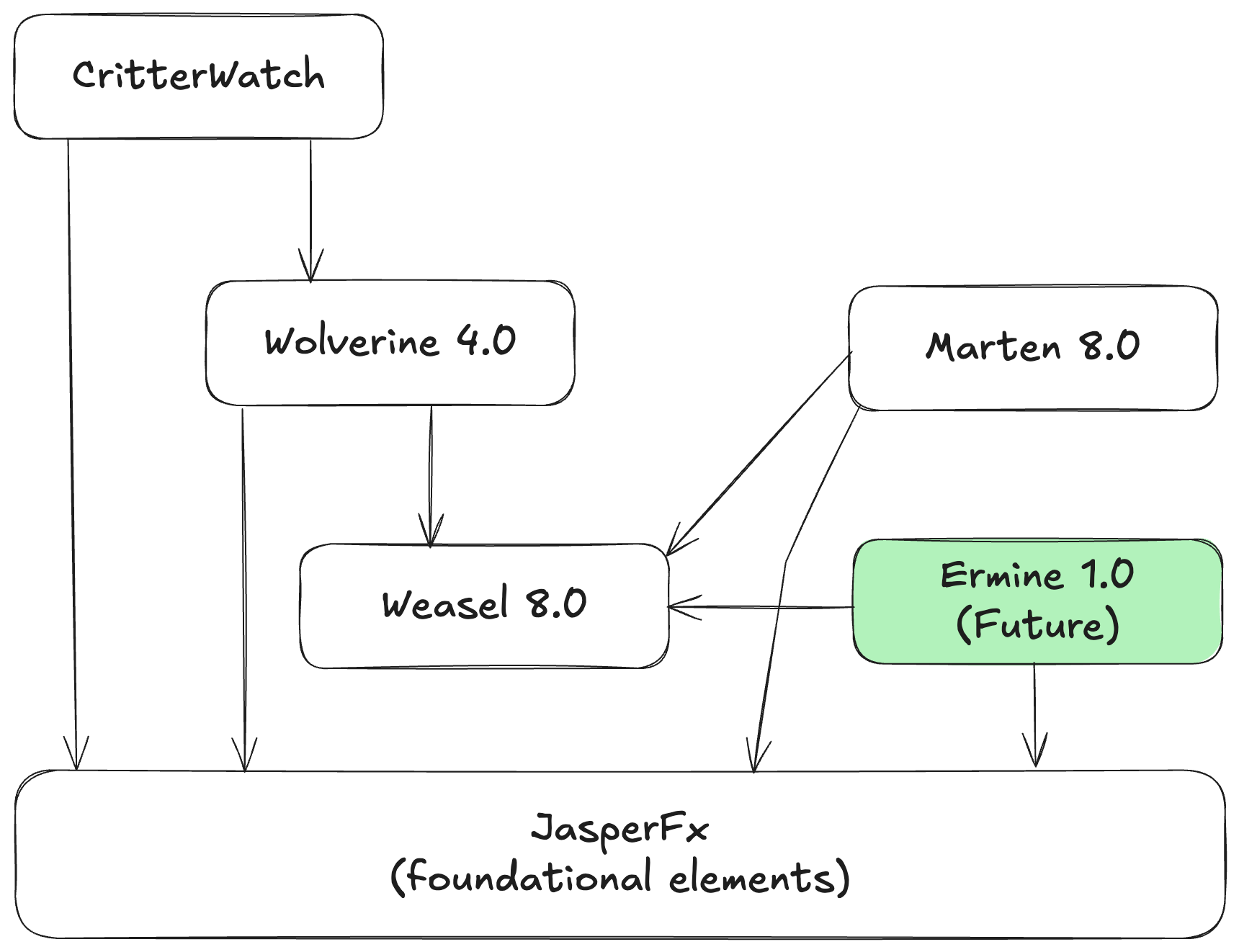
As for Marten, Wolverine, and other future Critter Stack tools, the current JasperFx Software strategy remains following the “open core” model where the existing capabilities in the MIT-licensed tools (note below) remain under an OSS license and JasperFx Software focuses on services, support plans, and the forthcoming commercial CritterWatch tool for monitoring, management, and some advanced features for data privacy, multi-tenancy, and extreme scalability. While we certainly respect MassTransit’s decision, we’re going to try a different path and stay down the “open core” model and Marten 8 / Wolverine 4 will be released under the MIT OSS license. I will admit that you may see some increasing reluctance to be providing as much free support through Discord as we have to users in the past though.
To be technical, there is one existing feature in Marten 7.* for optimized projection rebuilds that I think we’ll redesign and move to the commercial add on tooling in the Marten 8 timeframe, but in this case the existing feature is barely usable anyway so ¯\_(ツ)_/¯
It’s just time for an update from my last post on Critter Stack Roadmap Update for February as the work has progressed in the past weeks and we have more clarity on what’s going to change.
Work is heavily underway right now for a round of related releases in the Critter Stack (Marten, Wolverine, and other tools) I was originally calling “Critter Stack 2025” involving these tools:
Ermine for Event Sourcing with SQL Server
“Ermine” is our next full fledged “Critter” that’s been a long planned port of a significant subset of Marten’s functionality to targeting SQL Server. At this point, the general thinking is:
Focus on porting the Event Sourcing functionality from Marten
Quite possibly build around the JSON field support in EF Core and utilize EF Core under the covers. Maybe.
Use a new common JasperFx.Events library that will contain the key abstractions, metadata tracking, and even projection support. This new library will be shared between Marten, Ermine, and theoretical later “critters” targeting CosmosDb or DynamoDb down the line
Maybe try to lift out more common database handling code from Marten, but man, there’s more differences between PostgreSQL and SQL Server than I think people understand and that might turn into a time sink
Support the same kind of “aggregate handler workflow” integration with Wolverine as we have with Marten today, and probably try to do this with shared code, but that’s just a detail
Is this a good idea to do at all? We’ll see. The work to generalize the Marten projection support has been a time sink so far. I’ve been told by folks for a decade that Marten should have targeted SQL Server, and that supporting SQL Server would open up a lot more users. I think this is a bit of a gamble, but I’m hopeful.
JasperFx Dependency Consolidation
Most of the little, shared foundational elements of Marten, Wolverine, and soon to be Ermine have been consolidated into a single JasperFx library. That now includes what was:
JasperFx.Core (which in turn was renamed from “Baseline” after someone else squatted on that name and in turn was imported from ancient FubuCore for long term followers of mine)
The command line discovery, parsing, and execution model that is in Oakton today. That might be a touch annoying for the initial conversion, but in the little bit longer term that’s allowed us to combine several Nuget packages and simplify the project structure over all. TL;DR: fewer Nugets to install going forward.
Marten 8.0
I hope that Marten 8.0 is a much smaller release than Marten 7.0 was last year, but the projection model changes are turning out to be substantial. So far, this work has been done:
.NET 6/7 support has been dropped and the dependency tree simplified after that
Synchronous database access APIs have been eliminated
All other API signatures that were marked as [Obsolete] in the latest versions of Marten 7.* were removed
Marten.CommandLine was removed altogether, but the “db-*” commands are available as part of Marten’d dependency tree with no difference in functionality from the “marten-*” commands
Upgraded to the latest Npgsql 9
The projection subsystem overhaul is ongoing and substantial and frankly I’m kind of expecting Vizzini to show up in my home office and laugh at me for starting a land war in Southeast Asia. For right now I’ll just say that the key goals are:
The aforementioned reuse with Ermine and potential other Event Store implementations later
Making it as easy as possible to use explicit code instead as desired for the projections in addition to the existing conventional Apply / Create methods
Eliminate code generation for just the projections
Simplify the usage of “event slicing” for grouping events in multi-stream projections. I’m happy how this is shaping up so far, and I think this is going to end up being a positive after the initial conversion
Improve the throughput of the async daemon
There’s also a planned “stream compacting” feature happening, but it’s too early to talk about that much. Depending on how the projection work goes, there may be other performance related work as well.
Wolverine 4.0
Wolverine 4.0 is mostly about accomodating the work in other products, but there are some changes. Here’s what’s already been done:
Dropped .NET 7 support
Significant work for a single application being able to use multiple databases from within one application for folks getting clever with modular monoliths. In Wolverine 4.*, you’ll be able to mix and match any number of data stores with the corresponding transactional inbox/outbox support much better than Wolverine 3.* can do. This is 100% about modular monoliths, but also fit into the CritterWatch work
Work to provide information to CritterWatch
There are some other important features that might be part of Wolverine 4.0 depending on some ongoing negotiations with a potential JasperFx customer.
CritterWatch Minimal Viable Product Direction
“CritterWatch” is a long planned commercial add on product for Wolverine, Marten, and any future “critter” Event Store tools. The goal is to create both a management and monitoring dashboard for Wolverine messaging and the Event Sourcing processes in those systems.
The initial concept is shown below:
At least for the moment, the goal of the CritterWatch MVP is to deliver a standalone system that can be deployed either in the cloud or on a client premises. The MVP functionality set will:
Explain the configuration and capabilities of all your Critter Stack systems, including some visualization of how messages flow between your systems and the state of any event projections or subscriptions
Work with your OpenTelemetry tracking to correlate ongoing performance information to the artifacts in your system.
Visualize any ongoing event projections or subscriptions by telling you where each is running and how healthy they are — as well as give you the ability to pause, restart, rebuild, or rewind them as needed
Manage the dead letter queued (DLQ) messages of your system with the ability to query the messages and selectively replay or discard the DLQ messages
We have a world of other plans for CritterWatch, but the feature set above is the most requested features from the companies that are most interested in this tool first.
This content will later be published as a tutorial somewhere on one of our documentation websites.This was originally “just” an article on doing blue/green deployments when using projections with Marten, so hence the two martens up above:)
Event Sourcing may not seem that complicated to implement, and you might be tempted to forego any kind of off the shelf tooling and just roll your own. Just appending events to storage by itself isn’t all that difficult, but you’ll almost always need projections of some sort to derive the system state in a usable way and that’s a whole can of complexity worms as you need to worry about consistency models, concurrency, performance, snapshotting, and you inevitably need to change a projection in a deployment down the road.
Fortunately, the full combination of Marten and Wolverine (the “Critter Stack”) for Event Sourcing architectures gives you powerful options to cover a variety of projection scenarios and needs. Marten by itself provides multiple ways to achieve strongly consistent projected data when you have to have that. When you prefer or truly need eventual consistency instead for certain projections, Wolverine helps Marten scale up to larger data loads by distributing the background work that Marten does for asynchronous projection building. Moreover, when you put the two tools together, the Critter Stack can support zero downtime deployments that involve projections rebuilds without sacrificing strong consistency for certain types of projections.
Consistency Models in Marten
One of the decision points in building projections is determining for each individual projection view whether you need strong consistency where the projected data is guaranteed to match the current state of the persisted events, or if it would be preferable to rely on eventual consistency where the projected data might be behind the current events, but will “eventually” be caught up. Eventual consistency might be attractive because there are definite performance advantages to moving some projection building to an asynchronous, background process (Marten’s async daemon feature). Besides the performance benefits, eventual consistency might be necessary to accommodate cases where highly concurrent system inputs would make it very difficult to update projection data within command handling without either risking data loss or applying events out of sequential order.
“Live” projections are calculated in memory by fetching the raw events and building up an aggregated view. Live projections are strongly consistent.
“Inline” projections are persisted in the Marten database, and the projected data is updated as part of the same database transaction whenever any events are appended. Inline projections are also strongly consistent.
“Async” projections are continuously built and updated in the database as new events come in a background process in Marten called the “Async Daemon“. On its face this is obviously eventual consistency, but there’s a technical wrinkle where Marten can “fast forward” asynchronous projections to still be strongly consistent on demand.
For Inline or Async projections, the projected data is being persisted to Marten using its document database capabilities and that data is available to be loaded through all of Marten’s querying capabilities, including its LINQ support. Writing “snapshots” of the projected data to the database also has an obvious performance advantage when it comes to reading projection state, especially if your event streams become too long to do Live aggregations on demand.
Now let’s talk about some common projection scenarios and how you should choose projection lifecycles for these scenarios:
A “write model” projection for a single event stream that represents a logical business entity or workflow like an “Invoice” or an “Order” with all the necessary information you would need in command handlers to “decide” how to process incoming commands. You will almost certainly need this data to be strongly consistent with the events in your command processing. I think it’s a perfectly good default to start with a Live lifecycle, and maybe even move to Inline if you want snapshotting in the case of longer event streams, but there’s a way in Marten to actually use Async as well with its FetchForWriting() API as shown below in this sample MVC controller that acts as a command handler (the “C” in CQRS):
[HttpPost("/api/incidents/categorise")]
public async Task<IActionResult> Post(
CategoriseIncident command,
IDocumentSession session,
IValidator<CategoriseIncident> validator)
{
// Some validation first
var result = await validator.ValidateAsync(command);
if (!result.IsValid)
{
return Problem(statusCode: 400, detail: result.Errors.Select(x => x.ErrorMessage).Join(", "));
}
var userId = currentUserId();
// This will give us access to the projected current Incident state for this event stream
// regardless of whatever the projection lifecycle is!
var stream = await session.Events.FetchForWriting<Incident>(command.Id, command.Version, HttpContext.RequestAborted);
if (stream.Aggregate == null) return NotFound();
if (stream.Aggregate.Category != command.Category)
{
stream.AppendOne(new IncidentCategorised
{
Category = command.Category,
UserId = userId
});
}
await session.SaveChangesAsync();
return Ok();
}
The FetchForWriting() API is the recommended way to write command handlers that need to use a “write model” to potentially append new events. FetchForWriting helps you opt into easy optimistic concurrency protection that you probably want to protect against concurrent access to the same event stream. As importantly, FetchForWriting completely encapsulates whatever projection lifecycle we’re using for the Incident write model above. If Incident is registered as:
Inline, then this API just loads the persisted snapshot out of the database similar to IQuerySession.LoadAsync<Incident>(id)
Async, then this API does a “catch up” model for you by fetching — in one database round trip mind you! — the last persisted snapshot of the Incident and any captured events to that event stream after the last persisted snapshot, and incrementally applies the extra events to effectively “advance” the Incident to reflect all the current events captured in the system.
The takeaway here is that you can have the strongly consistent model you need for command handlers with concurrent access protections and be able to use any projection lifecycle as you see fit. You can even change lifecycles later without having to make code changes!
In the next section I’ll discuss how that “catch up” ability will allow you to make zero downtime deployments with projection changes.
I didn’t want to use any “magic” in the code sample above to discuss the FetchForWriting API in Marten, but do note that Wolverine’s “aggregate handler workflow” approach to streamlined command handlers utilizes Marten’s FetchForWriting API under the covers. Likewise, Wolverine has some other syntactic sugar for more easily using Marten’s FetchLatest API.
A “read model” projection for a single stream that again represents the state of a logical business entity or workflow, but this time optimized for whatever data needs a user interface or query endpoint of your system needs. You might be okay in some circumstances to get away with eventually consistent data for your “read model” projections, but for the sake of this article let’s say you do want strongly consistent information for your read model projections. There’s also a little bit lighter API called FetchLatest in Marten for fetching a read only view of a projection (this only works with a single stream projection in case you’re wondering):
public static async Task read_latest(
// Watch this, only available on the full IDocumentSession
IDocumentSession session,
Guid invoiceId)
{
var invoice = await session
.Events.FetchLatest<Projections.Invoice>(invoiceId);
}
Our third common projection role is simply having a projected view for reporting. This kind of projection may incorporate information from outside of the event data as well, combine information from multiple “event streams” into a single document or record, or even cross over between logical types of event streams. At this point it’s not really possible to do Live aggregations like this, and an Inline projection lifecycle would be problematic if there was any level of concurrent requests that impact the same “multi-stream” projection state. You’ll pretty well have to use the Async lifecycle and accept some level of eventual consistency.
It’s beyond the scope of this paper, but there are ways to “wait” for an asynchronous projection to catch up or to take “side effect” actions whenever an asynchronous projection is being updated in a background process.
I should note that “read model” and “write model” are just roles within your system, and it’s going to be common to get by with a single model that happily plays both roles in simpler systems, but don’t hesitate to use separate projection representations of the same events if the consumers of your system’s data just have very different needs.
Persisting the snapshots comes with a potentially significant challenge when there is inevitably some reason why the projection data has to be rebuilt as part of a deployment. Maybe it’s because of a bug, new business requirements, a change in how your system calculates a metric from the event data, or even just adding an entirely new projection view of the same old event data — but the point is, that kind of change is pretty likely and it’s more reliable to plan for change rather than depend on being perfect upfront in all of your event modeling.
Fortunately, Marten with some serious help from Wolverine, has some answers for that!
As I alluded to just above, one of the biggest challenges with systems using event sourcing is what happens when you need to deploy changes that involve projection changes that will require rebuilding persisted data in the database. As a community we’ve invested a lot of time into making the projection rebuild process smoother and faster, but there’s admittedly more work yet to come.
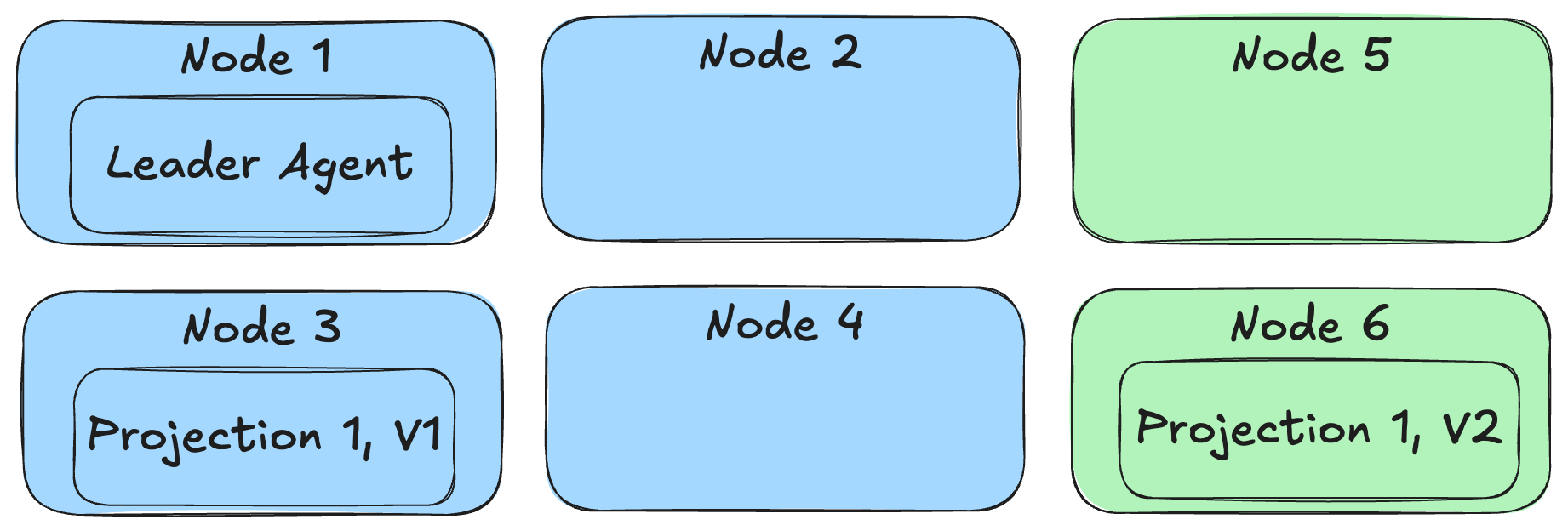
Instead of requiring some system downtime in order to do projection rebuilds before a new deployment though, the Critter Stack can now do a true “blue / green” deployment where both the old and new versions of the system and even versioned projections can run in parallel as shown below:
Let’s rewind a little bit and talk about how to make this happen, because it is a little bit of a multi-step process.
First off, try to only use FetchForWriting() or FetchLatest() when you need strongly consistent access to any kind of single stream projection (definitely “write model” projections and probably “read model” projections as well).
Next, if you need to make some kind of breaking changes to a projection of any kind, use the ProjectionVersion property and increment it to the next version like so:
// This class contains the directions for Marten about how to create the
// Incident view from the raw event data
public class IncidentProjection: SingleStreamProjection<Incident>
{
public IncidentProjection()
{
// THIS is the magic sauce for side by side execution
// in blue/green deployments
ProjectionVersion = 2;
}
public static Incident Create(IEvent<IncidentLogged> logged) =>
new(logged.StreamId, logged.Data.CustomerId, IncidentStatus.Pending, Array.Empty<IncidentNote>());
public Incident Apply(IncidentCategorised categorised, Incident current) =>
current with { Category = categorised.Category };
// More event type handling...
}
By incrementing the projection version, we’re effectively making this a completely new projection in the application that will use completely different database tables for the Incident projection version 1 and version 2. This allows the “blue” nodes running the starting version of our application to keep chugging along using the old version of Incident while “green” nodes running the new version of our application can be running completely in parallel, but depending on the new version 2 of the Incident projection.
You will also need to make every single newly revised projection run under the Async lifecycle as well. As we discussed earlier, the FetchForWriting API is able to “fast forward” a single Incident write model projection as needed for command processing, so our “green” nodes will be able to handle commands against Incident event streams with the correct system state. Admittedly, the system might be running a little slower until the asynchronous Incident V2 projection gets caught up, but “slower” is arguably much better than “down”.
With the case of multi-stream projections (our reports), there is no equivalent to FetchLatest, so we’re stuck with eventual consistency. What you can at least do is deploy some “green” nodes with the new version of the system and the revisioned projections and let it start building the new projections from scratch as it starts — but not allow those nodes to handle outside requests until the new versions of the projection are “close” to being caught up to the current event store.
Now, the next question is “how does Marten know to only run the “green” versions of the projections on “green” nodes and make sure that every single projection + version combination is running somewhere?
// This would be in your application bootstrapping
opts.Services.AddMarten(m =>
{
// Other Marten configuration
m.Projections.Add<IncidentProjection>(ProjectionLifecycle.Async);
})
.IntegrateWithWolverine(m =>
{
// This makes Wolverine distribute the registered projections
// and event subscriptions evenly across a running application
// cluster
m.UseWolverineManagedEventSubscriptionDistribution = true;
});
Referring back to the diagram from above, that option above enables Wolverine to distribute projections to running application nodes based on each node’s declared capabilities. This also tries to evenly distribute the background projections so they’re spread out over the running service nodes of our application for better scalability instead of only running “hot/cold” like earlier versions of Marten’s async daemon did.
As “blue” nodes are pulled offline, it’s safe to drop the Marten table storage for the projection versions that are no longer used. Sorry, but at this point there’s nothing built into the Critter Stack, but you can easily do that through PostgreSQL by itself with pure SQL.
Summary
This is a powerful set of capabilities that can be valuable in real life, grown systems that utilize Event Sourcing and CQRS with the Critter Stack, but I think we as a community have failed until now to put all of this content together in one place to unlock its usage by more people.
I am not aware of any other Event Sourcing tool in .NET or any other technical ecosystem for that matter that can match Marten & Wolverine’s ability to support this kind of potentially zero downtime deployment model. I’ve also never seen another Event Sourcing tool that has something like Marten’s FetchForWriting and FetchLatest APIs. I definitely haven’t seen any other CQRS tooling enable your application code to be as streamlined as the Critter Stack’s approach to CQRS and Event Sourcing.
I hope the key takeaway here is that Marten is a mature tool that’s been beaten on by real people building and maintaining real systems, and that it already solves challenging technical issues in Event Sourcing. Lastly, Marten is the most commonly used Event Sourcing tool for .NET as is, and I’m very confident in saying it has by far the most complete and robust feature set while also having a very streamlined getting started experience.
So this was meant to be a quick win blog post that I was going to bang out at the kitchen table after dinner last night, but instead took most of the next day. The Critter Stack core team is working on a new set of tutorials for both Marten and Wolverine, and this will hopefully take its place with that new content soon.
Wolverine 4.0 is also under way, but there will be at least some Wolverine.HTTP improvements in the 3.* branch before we get to 4.0.
Big thanks to the whole Critter Stack community for continuing to support Wolverine, including the folks who took the time to create actionable bug reports that led to several of the fixes and the folks who made fixes to the documentation website as well!
I have been writing up a little one pager for a JasperFx Software client for their new CTO on why and how their flagship system could use some technical transformation and modernization. I ran my write up past one of their senior developers that I’ve been collaborating on for tactical performance improvements, and he more or less agreed with everything but felt bad that I was maybe throwing the original development team (all since departed for other opportunities) under the bus a bit — my words, not his.
My response was that their planned approach might have been working just fine upfront when the system was simpler, but maybe they would have happily and competently adapted over time as the system overgrew the original patterns and reference architecture, but just weren’t around to get that feedback.
And let’s be honest, I know I’ve created some clever architectures that got dropped on unsuspecting other people in my day too. Including the (actually kind of successful) workflow system I did in Classic ASP + Oracle that had ~70 metadata tables and the system that was written in 6 different programming languages.
That brings me finally to my main point here, and that’s even though I see plenty of systems where the codebase is very challenging to work with and puts the system at risk, I don’t think that any of the teams were necessarily incompetent or didn’t care about doing good work or didn’t have an organized theory about how the code should be structured or even what the architecture should be. Moreover, I can’t say that I’ve even seen a true, classic ball of mud in a couple decades.
Instead, I would say that the systems that I’ve seen in the past decade that were widely known as having code that was hard to work on and suffered from poor performance all had a pretty cohesive coding approach and architecture. The real problem was that at some point the system or the database had grown enough to expose the flaws in the approach or simply grown too complex to be confined within the system’s prescriptive approach, but the teams who owned those systems did not, or were not able to, adapt over time.
To try to make this post not ramble on too long, here’s a couple follow up points:
I think that if you have technical ownership over any kind of large system, or are tasked with creating what’s likely going to grow to become a large system, you should adopt an attitude of constantly challenging the basic approach and at a minimum, being aware of when intended changes to the system are difficult because of the current architectural approach
Moderate on the idea of consistency throughout your codebase or at least between features. On my recent appearance on DotNetRocks, I veered into a sports metaphor about “raising the floor” vs “raising the ceiling” of the technical quality of a codebase. Technical leads who are worried about consistency and prescriptive project templates are trying to “raise the floor” on code quality — and that works to a point. On the other hand, I think that if you empower a development team to adapt or change their technical approach over time or even just for new subsystems, and if the team has the skillset to do so, you can “raise the ceiling” on technical quality because I have found that one of the main contributors to bad system code is rigid adherence to some kind of prescriptive approach that just doesn’t scale up to the more complicated use cases in a big system.
If you follow me or have ever stumbled into many discussions about the Critter Stack, you’ll know that I very strongly believe that reducing code ceremony. For me this means forsaking too many abstractions over persistence, reducing layering, favoring a vertical slice architecture, and honestly, letting in some “magic” through conventional approaches (that’s a debate all by itself of course). I think there’s a huge advantage in being able to easily reason about a codebase throughout a use case from system inputs all the way down to the database. On the other side of that, I think that complex layering strategies will often put too many layers of code to the point where teams cannot easily understand the cause and effect between system inputs and what the outcomes actually are. That is, I think, the number one cause of poor system performance by teams comes from not being able to easily see how chatty a system becomes between its front end, server layer, and database. As an aside, I’ve seen OpenTelemetry tracing be a godsend for identifying performance bottlenecks in unnecessarily complicated code by showing you exactly how many queries a single web request is really making.
Just to hammer on the code ceremony angle yet again, I think the only truly reliable way to arrive at a good system that meets your company’s needs over time and is easy to change is iteration and adaptation. High ceremony coding approaches retard your ability to quickly iterate and adapt, and but more of an onus on teams to get things right upfront — which just isn’t consistently possible no matter how hard your try.
Summary
Anyway, to close out, I think that the mass majority of us really do care about doing a good job in our software development work, but we’re all quite capable of having ideas about how a system should be coded, structured, and architected that simply will not work out over time. The only real solution is empowered teams that constantly adapt as necessary instead of letting a codebase get out of control in the first place.
Wait, what’s that you ask? How do you work with your product owners to give you the space to do that? And that’s my cue to start my week long vacation!
Good luck folks, and try to be a little easier on your feelings toward the “previous folks”. And that goes double for me.
And look, I got through this whole post without ranting about how prescriptive Onion/Clean/Hexagonal/Ports and Adapters/iDesign approaches and all the cruft that the DDD community dares each other to build into systems is the root of all coding evil! Oops, never mind.
JasperFx Software offers custom consulting engagements or ongoing support contracts for any part of the Critter Stack. Some of the features in this post were either directly part of client engagements or inspired by our work with JasperFx clients.
This week brought out some new functionality and inevitably some new bug fixes in Marten 7.38 and Wolverine 3.10. I’m actually hopeful this is about the last Marten 7.* release, and Marten 8.0 is heavily underway. Likewise, Wolverine 3.* is probably about played out, and Wolverine 4.0 will come out at the same time. For now though, here’s some highlights of new functionality.
Delete All Marten Data for a Single Tenant
A JasperFx client has a need to occasionally remove all data for a single named tenant across their entire system. Some of their Marten documents and the events themselves are multi-tenanted, while others are global documents. In their particular case, they’re using Marten’s support for managed table partitions by tenant, but other folks might not. To make the process of cleaning out all data for a single tenant as easy as possible regardless of your particular Marten storage configuration, Marten 7.38 added this API:
var builder = Host.CreateApplicationBuilder();
builder.UseWolverine(opts =>
{
opts
.UseRabbitMq(builder.Configuration.GetConnectionString("rabbit"))
// You can configure the queue type for declaration with this
// usage as well
.DeclareQueue("stream", q => q.QueueType = QueueType.stream)
// Use quorum queues by default as a policy
.UseQuorumQueues()
// Or instead use streams
.UseStreamsAsQueues();
opts.ListenToRabbitQueue("quorum1")
// Override the queue type in declarations for a
// single queue, and the explicit configuration will win
// out over any policy or convention
.QueueType(QueueType.quorum);
});
Note that nothing in Wolverine changed other than giving you the ability to make Wolverine declare Rabbit MQ queues as quorum queues or as streams.
Easy Access to Marten Event Sourced Aggregation Data in Wolverine
While the Wolverine + Marten “aggregate handler workflow” is a popular feature for command handlers that may need to append events, sometimes you just want a read only version of an event sourced aggregate. Marten has its FetchLatest API that lets you retrieve the current state of an aggregated projection consistent with the current event store data regardless of the lifecycle of the projection (live, inline, or async). Wolverine now has a quick short cut for accessing that data as a value “pushed” into your HTTP endpoints by decorating a parameter of your handler method with the new [ReadAggregate] attribute like so:
[WolverineGet("/orders/latest/{id}")]
public static Order GetLatest(Guid id, [ReadAggregate] Order order) => order;
public record FindAggregate(Guid Id);
public static class FindLettersHandler
{
// This is admittedly just some weak sauce testing support code
public static LetterAggregateEnvelope Handle(
FindAggregate command,
[ReadAggregate] LetterAggregate aggregate)
=> new LetterAggregateEnvelope(aggregate);
}
This feature was inspired by a session with a JasperFx Software client where their HTTP endpoints frequently needed to access projected aggregate data for multiple event streams, but only append events to one stream. This functionality was probably already overdue anyway as a way to quickly get projection data any time you just need to read that data as part of a command or query handler.
So roughly, here’s what I said or at least tried to say:
I would generally recommend against using wrapping repository abstractions around low level persistence tooling like Marten, EF Core, or Dapper in systems in most cases. Hence the title of this post:). I say this for a couple reasons:
The typical IRepository<T> abstraction does pretty well nothing to add any value and frequently blows up the complexity of code when you inevitably have use cases that work on more than one domain entity type at a time
Those abstractions frequently push teams toward using least common denominator capabilities of those tools and accidentally eliminate the usage of a lot of features like batch data querying that would help make system performance better
Despite the theory that using these abstractions will make it easier or at least possible to swap out technical infrastructure later, I think that’s patently not true, especially not when these abstractions are combined with an emphasis on horizontal layering by technical concern and every little bit of data access for the system is in one giant project.
Instead, I prefer to directly utilize Marten or RavenDb’s IDocumentSession or an EF Core DbContext and utilize every last bit of special capabilities these tools have to improve performance. Moreover, following that theme of “vertical slice”, if some kind of database query is only used by a single HTTP request or command handler, I’d strongly prefer that query be right smack dab in the vertical slice code instead of scattered all over your codebase in different horizontal layers because that frequently has some bearing on understanding how the entire message handling or HTTP request or whatever the transaction is actually works.
A large part of this is the feeling that we mostly need to reason about the complete functionality of a single use case or a closely related set of use cases at a time from system inputs down to database queries. On the other hand, I have almost never needed to reason about a system’s entire data access layer in isolation even though that’s held up as an advantage of Clean/Onion/Hexagonal layering approaches. Some folks will argue that there’s value in having all the system’s business logic in one domain layer, but I would think that’s not that valuable in a bigger system anyway.
I think a reasonable person could easily disagree with everything I just said with concerns about testability, consistency in code (a little bit overrated in my personal opinion), and the coupling to technical infrastructure. On that note, let’s shift to what I think does actually lead to maintainable system code:
Code that is easy to reason about. At this point, I think this is the single most important attribute of a long lived, non trivial sized business system that is constantly needing to change. The harder it is for the developers working on the system to understand the impact of changes in logic are within the system, or the harder it is to understand the behavior of the code around a reported bug, the less successful you’ll be. In my experience, the very techniques that we’ve been told lead to maintainable code (layering, abstractions, dependency inversion, prescriptive architectural patterns) are a large part of why systems I’ve worked with have been hard to reason about. To that end, I’m a big believer in reducing code ceremony and code noise so it’s easier to read (and write) the code by just having less junk to wade through. I also strongly recommend trying collapse layering so that it’s easier to just see how an entire feature actually works by having a lot less code to wade through and putting the closely related code together regardless of its technical stereotype (the very basis of the whole “vertical slice” idea).
Effective automated testing coverage. The single best way to truly have “reversible” technical decisions or just being able to actually upgrade technical infrastructure is having a strong level of automated test coverage to make changing the system safe.
With this emphasis on effective test coverage, I naturally believe in having testable code as an important enabler — but yet I’m strongly recommending reducing the number of abstractions and layering that many feel is necessary for testability. To that end, Wolverine’s encourages the idea of the A Frame Architecture approach to “vertical slices” as a way to achieve high testability without having to introduce abstractions and bloat your IoC container. Plus it’s just nice being able to write focused unit tests on business logic without having to fuss with lots of testing fakes. To be clear, I absolutely think it is possible to keep your business logic decoupled from infrastructure concerns without having to introduce additional layers of abstraction and layering.
Organize code around the “verbs” of the system more than the “nouns” (entities) of the system. Especially for a system that has any level of workflow logic rather than being a straight up CRUD system (and if you’re truly building a CRUD system, I think you can ignore everything I’ve said and just go bang out code). So structure your code around an “approve invoice” handler, and not automatically by the “Invoice” entity. And especially don’t prematurely try to divide up a system into separate micro-services or bounded contexts by entity. That’s maybe another way of saying “vertical slice”, but the point here is to avoid having massively bloated “InvoiceController” or “InvoiceRepository” classes that take part in a potentially large number of use cases. When you are dividing your system into separate modules or bounded contexts, pay attention to where the messages are going in between. If you ever have 2 or more modules that frequently have to access each other’s data or change together or be chatty in terms of messaging between themselves, you’re probably wanting to combine them into one single bounded context even if they technically involve more than one entity (invoice *and* inventory in one context maybe). It’s easy to reason about the shape of the system data sometimes, but that noun-centric/data-centric code organization doesn’t lend itself to code that’s easy to reason about when the workflow gets complicated in my experience.
If you possibly can, keep the system somewhat modularized so you could technically upgrade libraries or frameworks or databases in part of the system at a time. You can do all the “Clean Architecture” layering you want, but if your system is huge and there’s just one giant horizontal technical layer for data access, you won’t be able to swap it out easily because of the sheer amount of effort it might take to regression test the entire system when we all know damn well that your product managers will not give you months at a tie with no feature work just to do technical upgrades.
In the absence of reasons not to, I would strongly recommend defaulting to technology choices that play nicely in local integration testing. For a concrete example, if there’s no compelling reason otherwise, I’d prefer to use Rabbit MQ over Azure Service Bus strictly because Rabbit MQ has a fantastic local development story and Azure Service Bus does not (the new emulator is a nice step, but I didn’t find it to be usable yet). Likewise, PostgreSQL with Marten makes it very easy to quickly spin up an application database from a fresh Docker image for fast local development and isolated integration tests.
There’s a reddit thread going right now about people’s experiences with “vertical slice architecture vs clean architecture” on the /dotnet subreddit, and the one and only one thing that’s clear is that there’s a ton of disagreement about what the hell it is that “vertical slice architecture” actually means and a lot of folks conflating that with bounded contexts or micro-services. My takeaway is that like “ReST” before it, the “vertical slice” nomenclature may be quickly made useless by the variance of understanding of that terminology.
Summary
I banged this out fast and it probably shows. I’ll aim for some YouTube videos expanding on this some day soon.
The last time I wrote about the Critter Stack / JasperFx roadmap, I was admittedly feeling a little conservative about big new releases and really just focused on stabilization. In the past week though, the rest of the Critter Stack Core Team decided it was time to get going on the next round of releases for what will be Marten 8.0 and Wolverine 4.0, so let’s get into the details.
Definitely in Scope:
Upgrade Marten (and Weasel/Wolverine) to Npgsql 9.0
Drop .NET 6/7 support in Marten and .NET 7 support in Wolverine. Both will have targets for .NET 8/9
Consolidation of supporting libraries. What is today JasperFx.Core, JasperFx.CodeGeneration, and Oakton are getting combined into a new library called JasperFx. That’s partially to simplify setup by reducing the number of dotnet add ... calls you need to do, but also to potentially streamline configuration that’s today duplicated between Marten & Wolverine.
Drop the synchronous APIs that are already marked as [Obsolete] in Marten’s API surface
“Stream Compacting” in Marten/Wolverine/CritterWatch. This feature is being done in partnership with a JasperFx client
In addition to that work, JasperFx Software is working hard on the forthcoming “Critter Watch” tooling that will be a management and monitoring console application for Wolverine and Marten, so there’s also a bit of the work to help support Critter Watch through improvements to instrumentation and additional APIs that will land in Wolverine or Marten proper.
I’ll write much more about Critter Watch soon. Right now the MVP looks to be:
A dead letter message explorer and management tool for Wolverine
A view of your Critter Watch application configuration, which will be able to span multiple applications to better understand how messages flow throughout your greater ecosystem of services
Viewing and managing asynchronous projections in Marten, which should include performance information, a dashboard explaining what projections or subscriptions are running, and the ability to trigger projection rebuilds, rewind subscriptions, and to pause/restart projections at runtime
Displaying performance metrics about your Wolverine / Marten application by integration with your Otel tooling (we’re initially thinking about PromQL integration here).
Maybe in Scope???
It may be that we go for a quick and relatively low impact Marten 8 / Wolverine 4 release, but here are the things we are considering for this round of releases and would love any feedback or requests you might have:
Overhaul the Marten projection support, with a very particular emphasis on simplifying the multi-stream projections especially. The core team & I did quite a bit of work on that in the 4th quarter last year in the first attempt at Marten 8, and that work might feed into this effort as well. Part of that goal is to make it as easy as possible to use purely explicit code for projections as a ready alternative to the conventional Apply/Create method conventions. There’s an existing conversation in this issue.
Multi-tenancy support for EF Core with Wolverine commensurate with the existing Marten + Wolverine + multi-tenancy support. I really want to be expanding the Wolverine user base this year, and better EF Core support feels like a way to help achieve that.
Revisit the async daemon and add support for dependencies between asynchronous projections and/or the ability to “lock” the execution of 2 or more projections together. That’s 100% about scalability and throughput for folks who have particularly nasty complicated multi-stream projections. This would also hopefully be in partnership with a JasperFx client.
Revisiting the event serialization in Marten and its ability to support “downcasters” or “upcasters” for event versioning. There is an opportunity to ratchet up performance by moving to higher performance serializers like MessagePack or MemoryPack for the event serialization. You’d have to make that an opt in model, probably support side by side JSON & whatever other serialization, and make sure folks know that means losing the LINQ querying support for Marten events if you opt for the better performance.
Potentially risky time sink: pull quite a bit of the event store support code in Marten today into a new shared library (like the IEvent model and maybe quite a bit of the projection subsystem) where that code could be shared between Marten and the long planned Sql Server-backed event store. And maybe even a CosmosDb integration.
Some improvements to Wolverine specifically for modular monolith usage discussed in more depth in the next section.
I think we’re in good shape with Wolverine message handler discovery and routing for modular monoliths, but there’s some challenges around database integration, the transactional inbox/outbox support, and transactional middleware within with a single application that’s potentially talking to multiple databases from a single process — and then make things more complicated still by throwing in the possibility of using multi-tenancy through separated databases.
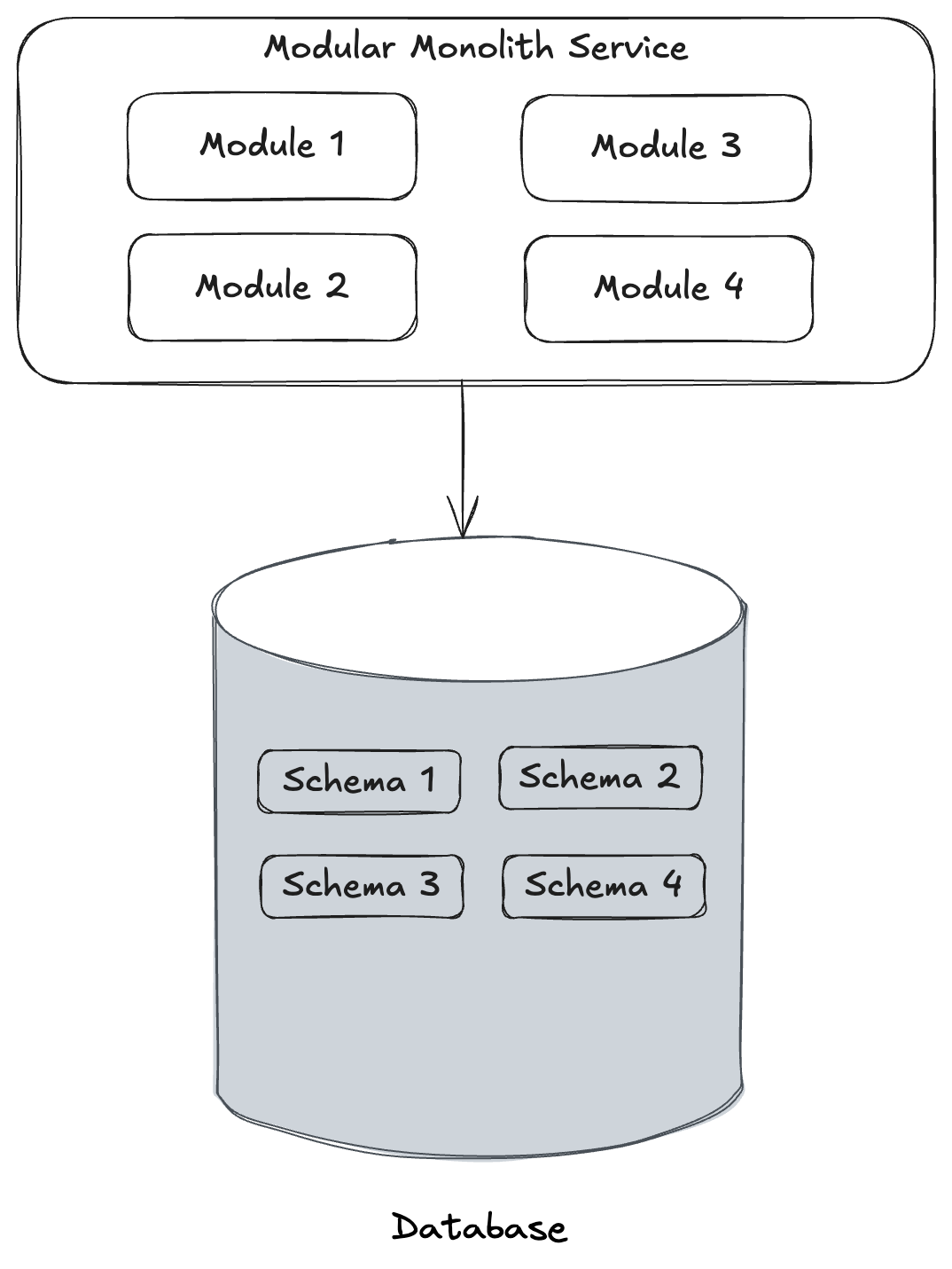
Wolverine already does fine with an architecture like the one below where you might have separate logical “modules” in your system that generally work against the same database, but using separate database schemas for the isolation:
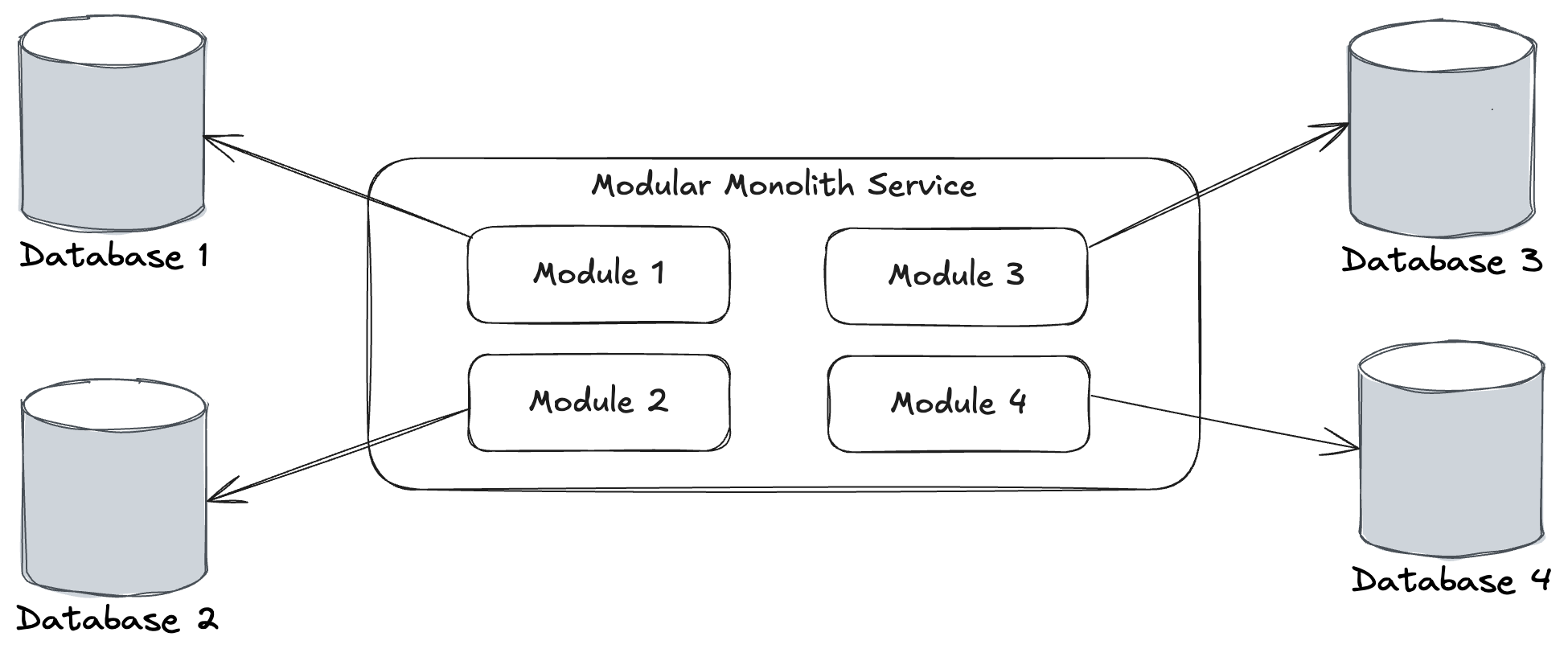
Where Wolverine doesn’t yet go (and I’m also not aware of any other .NET tooling that actually solves this) is the case where separate modules may be talking to completely separate physical databases as shown below:
The work I’m doing right now with “Critter Watch” touches on Wolverine’s message storage, so it’s somewhat convenient to try to improve Wolverine’s ability to allow you to mix and match different databases and even different database engines from one Wolverine application as part of this release.