Wolverine has had a very frequent release cadence the past couple months as community contributions, requests from JasperFx Software clients, and yes, sigh, bug reports have flowed in. Right now I think I can justifiably claim that Wolverine is innovating much faster than any of the other comparable tools in the .NET ecosystem.
Some folks clearly don’t like that level of change of course, and I’ve always had to field some only criticism for our frequency of releases. I don’t think that continues forever of course.
I thought that now would be a good time to write a little bit about the new features and improvements just because so much of it happened over the holiday season. Starting somewhat arbitrarily with the first of December to now…
Inferred Message Grouping in Wolverine 5.5
A massively important new feature in Wolverine 5 was our “Partitioned Sequential Messaging” that seeks to effectively head off problems with concurrent message processing by segregating message processing by some kind of business entity identity. Long story short, this feature can almost completely eliminate issues with concurrent access to data without eliminating parallel processing across unrelated messages.
“Classic” .NET Domain Events with EF Core in Wolverine 5.6
Wolverine is attracting a lot of new users lately who might honestly only have been originally interested because of other tool’s recent licensing changes, and those users tend to come with a more typical .NET approach to application architecture than Wolverine’s idiomatic vertical slice architecture approach. These new users are also a lot more likely to be using EF Core than Marten, so we’ve had to invest more in EF Core integration.
There wasn’t many new features of note, but Wolverine 5.7 less than a week after 5.6 had five contributors and knocked out a dozen issues. The open issue count in Wolverine crested in December in the low 70’s and it’s down to the low 30’s right now.
Client Requests in Wolverine 5.8
Wolverine 5.8 gave us some bug fixes, but also a couple new features requested by JasperFx clients:
The Community Went Into High Gear with Wolverine 5.9
Wolverine 5.9 dropped the week before Christmas with contributions from 7 different people.
The highlights are:
Sandeep Desai has been absolutely on fire as a contributor to Wolverine and he made the HTTP Messaging Transport finally usable in this release with several other pull requests in later versions that also improved that feature. This is enabling Wolverine to use HTTP as a messaging transport. I’ve long wanted this feature as a prerequisite for CritterWatch.
The Rabbit MQ integration got more robust about reconnecting on errors
Wolverine 5.10 Kicked off 2026 with a Bang!
Wolverine 5.10 came out last week with contributions from eleven different folks. Plenty of bug fixes and contributions built up over the holidays. The highlights include:
That release also included several bug fixes and an effort from me to go fill in some gaps in the documentation website. That release got us down to the lowest open issue count in years.
Summary
The Wolverine community has been very busy, it is actually a community of developers from all over the world, and we’re improving fast.
I do think that the release cadence will slow down somewhat though as this has been an unusual burst of activity.
The Marten community made our first big release of the new year with 8.18 this morning. I’m particularly happy with a couple significant things in this release:
We had 8 different contributors in just the last month of work this release represents
The entire documentation section on projections got a much needed revamp and now includes a lot more information about capabilities from our big V8 release last year. I’m hopeful that the new structure and content makes this crucial feature set more usable.
The “Composite or Chained Projections” feature has been something we’ve talked about as a community for years, and now we have it
The one consistent theme in those points is that Marten just got a lot better for our users for creating “query models” in systems.
Let’s Build a TeleHealth System!
I got to be a part of a project like this for a start up during the pandemic. Fantastic project with lots of great people. Even though I wasn’t able to use Marten on the project at that time (we used a hand rolled Event Sourcing solution with Node.JS + TypeScript), that project has informed several capabilities added to Marten in the years since including the features shown in this post.
Just to have a problem domain for the sample code, let’s pretend that we’re building a new only TeleHealth system that allows patients to register for an appointment online and get matched up with a healthcare provider for an appointment that day. The system will do all the work of coordinating these appointments as well as tracking how the healthcare providers spend their time.
That domain might have some plain Marten document storage for reference data including:
Provider — representing a medical provider (Nurse? Physician? PA?) who fields appointments
Specialty — models a medical specialty
Patient — personal information about patients who are requesting appointments in our system
Switching to event streams, we may be capturing events for:
Board – events modeling a single, closely related group of appointments during a single day. Think of “Pediatrics in Austin, Texas for January 19th”
ProviderShift – events modeling the activity of a single provider working in a single Board during a single day
Appointment – events recording the progress of an appointment including requesting an appointment through the appointment being cancelled or completed
Better Query Models
The easiest and most common form of a projection in Marten is a simple “write model” that projects the information from a single event stream to a projected document. From our TeleHealth domain, here’s the “self-aggregating” Board:
publicclassBoard
{
privateBoard()
{
}
publicBoard(BoardOpenedopened)
{
Name=opened.Name;
Activated=opened.Opened;
Date=opened.Date;
}
publicvoidApply(BoardFinishedfinished)
{
Finished=finished.Timestamp;
}
publicvoidApply(BoardClosedclosed)
{
Closed=closed.Timestamp;
CloseReason=closed.Reason;
}
publicGuidId { get; set; }
publicstringName { get; privateset; }
publicDateTimeOffsetActivated { get; set; }
publicDateTimeOffset?Finished { get; set; }
publicDateOnlyDate { get; set; }
publicDateTimeOffset?Closed { get; set; }
publicstringCloseReason { get; privateset; }
}
Easy money. All the projection has to do is apply the raw event data for that one stream and nothing else. Marten is even doing the event grouping for you, so there’s just not much to think about at all.
Now let’s move on to more complicated usages. One of the things that makes Marten such a great platform for Event Sourcing is that it also has its dedicated document database feature set on top of the PostgreSQL engine. All that means that you can happily keep some relatively static reference data back in just plain ol’ documents or even raw database tables.
To that end, let’s say in our TeleHealth system that we want to just embed all the information for a Provider (think a nurse or a physician) directly into our ProviderShift for easier usage:
// I was admittedly lazy in the testing, so I just
// completely embedded the Provider document directly
// in the ProviderShift for easier querying later
publicProviderProvider { get; set; } =provider;
}
When mixing and matching document storage and events, Marten has always given you the ability to utilize document data during projections by brute force lookups in your projection code like this:
public async Task<ProviderShift> Create(
// The event data
ProviderJoined joined,
IQuerySession session)
{
var provider = await session
.LoadAsync<Provider>(joined.ProviderId);
return new ProviderShift(joined.BoardId, provider);
}
The code above is easy to write and conceptually easy to understand, but when the projection is being executed in our async daemon where the projection is processing a large batch of events at one time, the code above potentially sets you up for an N+1 query anti-pattern where Marten has to make lots of small database round trips to get each referenced Provider every time there’s a separate ProviderJoined event.
Instead, let’s use Marten’s recent hook for event enrichment and the new declarative syntax we just introduced in 8.18 today to get all the related Provider information in one batched query for maximum efficiency:
public override async Task EnrichEventsAsync(SliceGroup<ProviderShift, Guid> group, IQuerySession querySession, CancellationToken cancellation)
{
await group
// First, let's declare what document type we're going to look up
.EnrichWith<Provider>()
// What event type or marker interface type or common abstract type
// we could look for within each EventSlice that might reference
// providers
.ForEvent<ProviderJoined>()
// Tell Marten how to find an identity to look up
.ForEntityId(x => x.ProviderId)
// And finally, execute the look up in one batched round trip,
// and apply the matching data to each combination of EventSlice, event within that slice
// that had a reference to a ProviderId, and the Provider
.EnrichAsync((slice, e, provider) =>
{
// In this case we're swapping out the persisted event with the
// enhanced event type before each event slice is then passed
// in for updating the ProviderShift aggregates
slice.ReplaceEvent(e, new EnhancedProviderJoined(e.Data.BoardId, provider));
});
}
Now, inside the actual projection for ProviderShift, we can use the EnhancedProviderJoined event from above like this:
// This is a recipe introduced in Marten 8 to just write explicit code
// to "evolve" aggregate documents based on event data
public override ProviderShift Evolve(ProviderShift snapshot, Guid id, IEvent e)
{
switch (e.Data)
{
case EnhancedProviderJoined joined:
snapshot = new ProviderShift(joined.BoardId, joined.Provider)
{
Provider = joined.Provider, Status = ProviderStatus.Ready
};
break;
case ProviderReady:
snapshot.Status = ProviderStatus.Ready;
break;
case AppointmentAssigned assigned:
snapshot.Status = ProviderStatus.Assigned;
snapshot.AppointmentId = assigned.AppointmentId;
break;
case ProviderPaused:
snapshot.Status = ProviderStatus.Paused;
snapshot.AppointmentId = null;
break;
case ChartingStarted charting:
snapshot.Status = ProviderStatus.Charting;
break;
}
return snapshot;
}
In the sample above, I replaced the ProviderJoined event being sent to our projection with the richer EnhancedProviderJoined event, but there are other ways to send data to projections with a new References<T> event type that’s demonstrated in our documentation on this feature.
Sequential or Composite Projections
This feature was introduced in Marten 8.18 in response to feedback from several JasperFx Software clients who needed to efficiently create projections that effectively made de-normalized views across multiple stream types and used reference data outside of the events. Expect this feature to grow in capability as we get more feedback about its usage.
Here are a handful of scenarios that Marten users have hit over the years:
Wanting to use the build products of Projection 1 as an input to Projection 2. You can do that today by running Projection 1 as Inline and Projection 2 as Async, but that’s imperfect and sensitive to timing. Plus, you might not have wanted to run the first projection Inline.
Needing to create a de-normalized projection view that incorporates data from several other projections and completely different types of event streams, but that previously required quite a bit of duplicated logic between projections
Looking for ways to improve the throughput of asynchronous projections by doing more batching of event fetching and projection updates by trying to run multiple projections together
To meet these somewhat common needs more easily, Marten has introduced the concept of a “composite” projection where Marten is able to run multiple projections together and possibly divided into multiple, sequential stages. This provides some potential benefits by enabling you to safely use the build products of one projection as inputs to a second projection. Also, if you have multiple projections using much of the same event data, you can wring out more runtime efficiency by building the projections together so your system is doing less work fetching events and able to make updates to the database with fewer network round trips through bigger batches.
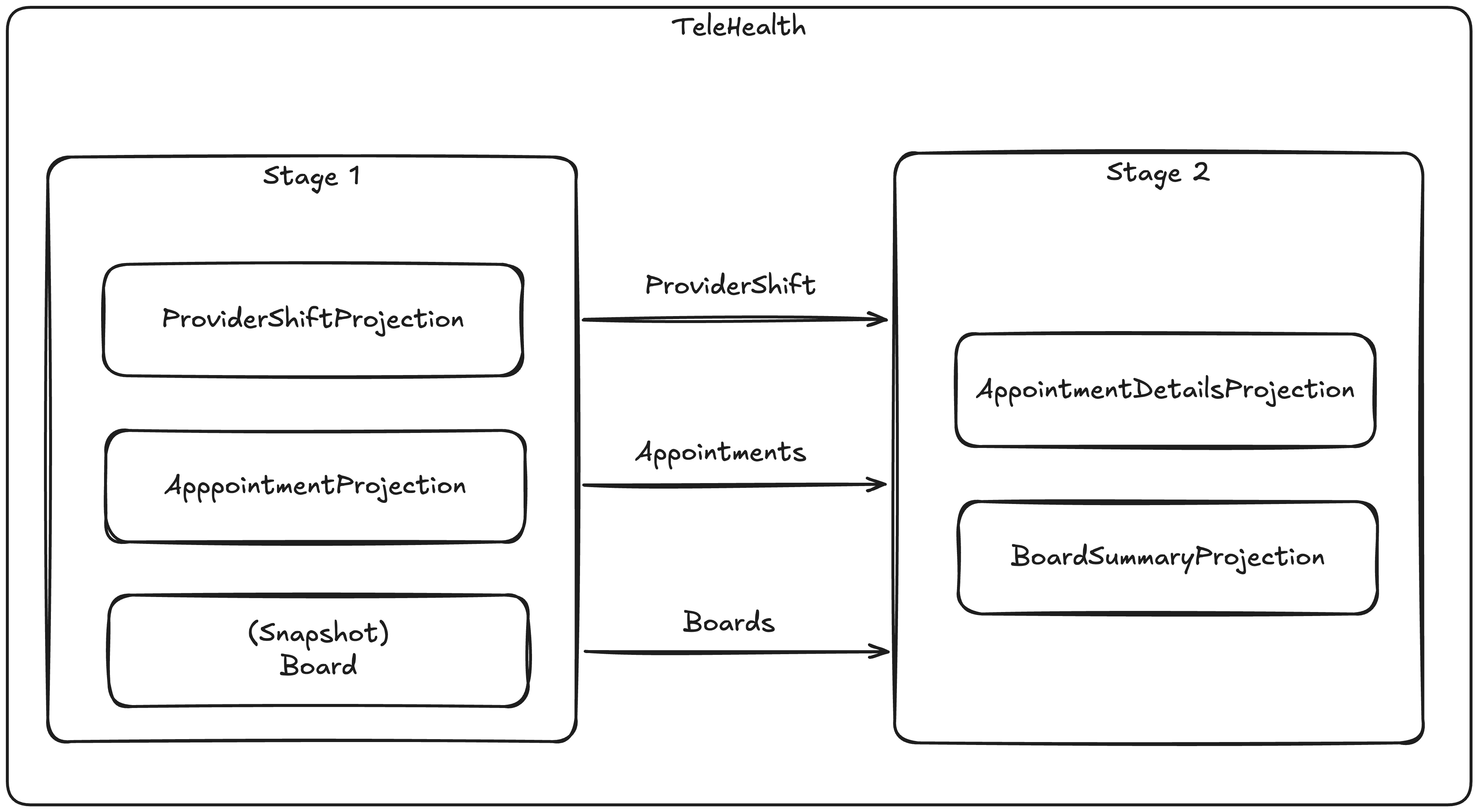
In our TeleHealth system, we need to have single stream “write model” projections for each of the three stream types. We also need to have a rich view of each Board that combines all the common state of the active Appointment and ProviderShift streams in that Board including the more static Patient and Provider information that can be used by the system to automate the assignment of providers to open patients (a real telehealth system would need to be able to match up the requirements of an appointment with the licensing, specialty, and location of the providers as well as “knowing” what providers are available or estimated to be available). We probably also need to build a denormalized “query model” about all appointments that can be efficiently queried by our user interface on any of the elements of Board, Appointment, Patient, or Provider.
What we really want is some way to efficiently utilize the upstream products and updates of the Board, Appointment, and ProviderShift “write model” projections as inputs to what we’ll call the BoardSummary and AppointmentDetails projections. We’ll use the new “composite projection” feature to run these projections together in two stages like this:
Before we dive into each child projection, this is how we can set up the composite projection using the StoreOptions model in Marten:
Now, let’s go downstream and look at the AppointmentDetailsProjection that will ultimately need to use the build products of all three upstream projections:
Note the usage of the Updated<T> event types that the downstream projections are using in their Evolve or DetermineAction methods. That is a synthetic event added by Marten to communicate to the downstream projections what projected documents were updated for the current event range. These events are carrying the latest snapshot data for the current event range so the downstream projections can just use the build products without making any additional fetches. It also guarantees that the downstream projections are seeing the exact correct upstream projection data for that point of the event sequencing.
Moreover, the composite “telehealth” projection is reading the event range once for all five constituent projections, and also applying the updates for all five projections at one time to guarantee consistency.
Some the documentation on Composite Projections for more information about how this feature fits it with rebuilding, versioning, and non stale querying.
Summary
Marten has hopefully gotten much better at building “query model” projections that you’d use for bigger dashboard screens or search within your application. We’re hoping that this makes Marten a better tool for real life development.
The best way for an OSS project to grow healthily is having a lot of user feedback and engagement coupled with the maintainers reacting to that feedback with constant improvement. And while I’d sometimes like to have the fire hose of that “feedback” stop for a couple days, it helps drive the tools forward.
The advent of JasperFx Software has enabled me to spend much more time working with our users and seeing the real problems they face in their system development. The features I described in this post are a direct result of engagements with at least four different JasperFx clients in the past year and a half. Drop us a line anytime at sales@jasperfx.net and I’d be happy to talk to you about how we can help you be more successful with Event Sourcing using Marten.
Reach out anytime to sales@jasperfx.net to ask us about how we could potentially help your shop with software development using the Critter Stack.
It’s a New Year and hopefully we all get to start on some great new software initiatives. If you happen to be starting something this year that’s going to get you into Event Driven Architecture or Event Sourcing, the Critter Stack (Marten and Wolverine) is a great toolset to get you where you’re going. And of course, JasperFx Software is around to help our clients get the most out of the Critter Stack and support you through architectural decisions, business modeling, and test automation as well.
A JasperFx support plan is more than just a throat to choke when things go wrong. We build in consulting time, and mostly interact with our clients through IM tools like Discord or Slack and occasional Zoom calls when that’s appropriate. And GitHub issues of course for tracking problems or feature requests.
Just thinking about the past week or so, JasperFx has helped clients with:
Helped troubleshoot a couple production or development issues with clients
Modeling events, event streams, and strategies for projections
A deep dive into the multi-tenancy support in Marten and Wolverine, the implications of different options, possible performance optimizations that probably have to be done upfront as well as performance optimizations that could be done later, and how these options fit our client’s problem domain and business.
For a greenfield project, we laid out several options with Marten to optimize the future performance and scalability with several opt in features and of course, the potential drawbacks of those features (like event archiving or stream compacting).
Worked with a couple clients on how best to configure Wolverine when multiple applications or multiple modules within the same application are targeting the same database
Worked with a client on how to configure Wolverine to enable a modular monolith approach to utilize completely separate databases and a mix and match of database per tenant with separate databases per module.
How authorization and authentication can be integrated into Wolverine.HTTP — which basically boils down to “basically the same as MVC Core”
A lot of conversations about how to protect your system against concurrency issues and what features in both Marten and Wolverine will help you be more resilient
Talked through many of the configuration possibilities for message sequencing or parallelism in Wolverine and how to match that to different needs
Fielded several small feature requests to improve Wolverine’s usage within modular monolith applications where the same message might need to be handled independently by separate modules
Pushed a new Wolverine release that included some small requests from a client for their particular usage
Conferred with a current client on some very large, forthcoming features in Marten that will hopefully improve its usability for applications that require complex dashboard screens that display very rich data. The feature isn’t directly part of the client’s support agreement per se, but we absolutely pay attention to our client’s use cases within our own internal roadmap for the Critter Stack tools.
But again, that’s only the past couple weeks. If you’re interested in learning more, or want JasperFx to be helping your shop, drop us an email at sales@jasperfx.net or you can DM me just about anywhere.
At least professionally, I tend to be mostly focused on what’s next on the road map or upcoming client work or long planned strategic improvements to the Critter Stack (Marten and Wolverine). One of the things I do every year is to write out a blog post stating the technical goals for the OSS projects that I lead, with this year’s version, Critter Stack Roadmap for 2026 already up (but I’m already going to publish a new version later this week). I’ll frequently look back to what I wrote in the previous January and be frustrated by the hoped for initiatives that still haven’t been completed or even started. All the same though, 2025 was a very productive year for the Critter Stack and there’s plenty of accomplishments and improvements worth reflecting on.
JasperFx Software in 2025
JasperFx Software more than doubled our roster of ongoing support clients while doing quite a bit of one off consulting and delivery work as well. The biggest improvement and growth is that I’ve stopped fretting on a daily basis about whether I gambled my family’s financial well being on an ego driven attempt to stave off a mid life crisis and started confidently planning the company’s future around what appears to be a very successful and promising technical toolset.
Along the way, we helped our clients through interactions on Discord, Slack, MS Teams (I’m not yet a fan), Zoom, and GitHub. Common topics for Critter Stack usage included:
Designing long lived workflows
Event Sourcing usage
Resiliency strategies of all sorts
Multi-Tenancy
Dealing with Concurrency. Lots of concurrency related issues
Test Automation
Quite a bit of troubleshooting
Instrumentation
If you would like any level of help with your Critter Stack usage, feel free to reach out to sales@jasperfx.net for a conversation about what or how JasperFx could help you out.
Marten in 2025
2024 was an insanely busy year for Marten improvements, and after that, I feel like there just wasn’t much lacking anymore in Marten’s feature set for productive event sourcing. You can definitely see Marten development slowed down a bit in 2025. Even so, we had 16 folks commit code this past year — with far more folks contributing through Discord discussions and feedback in GitHub issues.
Marten 8.0 dropped at the first of June, which included:
A big consolidation and reorganization of the shared dependencies underneath Marten and Wolverine
A lot of improvements to Marten’s Projections API including much better (we hope) options for writing explicit code and a streamlined API for “event slicing and grouping” in multi-stream projections
JasperFx Software built the Stream Compacting feature for our largest client as a mechanism to keep a busy system running smoothly over time by keeping the database size relatively stable
We added a lot more support for strong typed identifiers in different usage scenarios to Marten throughout the year. I won’t claim there isn’t still some potential problems out there, but dammit, we tried really hard on that front
Again in collaboration with JasperFx clients, we added far more metrics publishing to understand the Async Daemon behavior in production
Switched Marten from the venerable TPL DataFlow library to using System.Threading.Channels. I was very happy with how smoothly that went after the first day of toe stubbing.
After saying that I felt like Marten was essentially “done” at the beginning of this section, I think we actually do have a pretty ambitious set of enhancements for Marten projection support and cross-document querying teed up for early 2026.
All the same though, I’ll stand by my recent statements that Marten is clearly the best technical tool for Event Sourcing on the .NET platform and competitive with anything else out there in other ecosystems.
Wolverine in 2025
Buckle in, this list is much longer and I’m only going to hit the highlights because Wolverine development was crazily busy in 2025:
Wolverine had 66 different people contribute code in 2025. Some of those are from little pull requests to improve documentation (i.e., fixing my errors in markdown files), but that number dramatically undercounts the contribution from people in GitHub issues and Discord discussions. And also, those little pull requests to improve documentation are very much appreciated by me and I think they definitely improve the project in the whole.
Lots of improvements to Wolverine’s support for Modular Monolith architectures
Yet more support for strong typed identifiers. Curse those little maggots, but some of you really, really like them
Wolverine 3.13 improved Wolverine.HTTP with [AsParameters] binding support
Wolverine 4.0 brought the consolidation of shared dependencies with Marten as well as Multi-Tenancy through separate databases with Entity Framework Core (for a JasperFx client).
More Wolverine transport options support the “named broker” approach such that you can connect to multiple Rabbit MQ brokers, Azure Service Bus namespaces, Kafka brokers, or Amazon SQS endpoints from one system
Wolverine got much better support for “hybrid” HTTP endpoint/handler combinations (in collaboration with a JasperFx support client)
JasperFx working with another client improved the usability of F# idioms with Wolverine
New messaging transport options including GCP Pubsub, SignalR, Redis, an HTTP options, and a NATS.io option ready to go in the first release of 2026. Dang.
And there was a massive rush of activity at the end of the year as I scurried to address issues and requests from recent JasperFx clients for yet more resiliency, error handling, instrumentation, and inevitably some bugs. I’ll be writing a blog post later this week to go over the new additions from the US Thanksgiving holiday through the end of 2025.
I guess the big takeaway is that Wolverine improved a lot in 2025 and I expect that trend to continue at least during the early part of 2026. I would argue that regardless of exactly how Wolverine stacks up on features and usability compared to other options in .NET that Wolverine is improving and innovating much faster than any of its competitors.
Me in 2025
I’m maybe working at a bit of an unsustainable pace for the longer term, but I think I’m good for at least one more year at this pace. At the end of the day though, I feel extremely fortunate to be living out my long term professional dream to have my own company centered around the OSS tools that I’ve created or led.
I normally write this out in January, but I’m feeling like now is a good time to get this out as some of it is in flight. So with plenty of feedback from the other Critter Stack Core team members and a lot of experience seeing where JasperFx Software clients have hit friction in the past couple years, here’s my current thinking about where the Critter Stack development goes for 2026.
As I’m sure you can guess, every time I’ve written this yearly post, it’s been absurdly off the mark of what actually gets done through the year.
Critter Watch
For the love of all that’s good in this world, JasperFx Software needs to get an MVP out the door that’s usable for early adopters who are already clamoring for it. The “Critter Watch” tool, in a nutshell, should be able to tell you everything you need to know about how or why a Critter Stack application is unhealthy and then also give you the tools you need to heal your systems when anything does go wrong.
The MVP is still shaping up as:
A visualization and explanation of the configuration of your Critter Stack application
Performance metrics integration from both Marten and Wolverine
Event Store monitoring and management of projections and subscriptions
Wolverine node visualization and monitoring
Dead Letter Queue querying and management
Alerting – but I don’t have a huge amount of detail yet. I’m paying close attention to the issues JasperFx clients see in production applications though, and using that to inform what information Critter Watch will surface through its user interface and push notifications
This work is heavily in flight, and will hopefully accelerate over the holidays and January as JasperFx Software clients tend to be much quieter. I will be publishing a separate vision document soon for users to review.
The Entire “Critter Stack”
We’re standing up the new docs.jasperfx.net (Babu is already working on this) to hold documentation on supporting libraries and more tutorials and sample projects that cross Marten & Wolverine. This will finally add some documentation for Weasel (database utilities and migration support), our command line support, the stateful resource model, the code generation model, and everything to do with DevOps recipes.
Play the “Cold Start Optimization” epic across both Marten and Wolverine (and possibly Lamar). I don’t think that true AOT support is feasible, but maybe we can get a lot closer. Have an optimized start mode of some sort that eliminates all or at least most of:
Reflection usage in bootstrapping
Reflection usage at runtime, which today is really just occasional calls to object.GetType()
Assembly scanning of any kind, which we know can be very expensive for some systems with very large dependency trees.
Increased and improved integration with EF Core across the stack
Marten
The biggest set of complaints I’m hearing lately is all around views between multiple entity types or projections involving multiple stream types or multiple entity types. I also got some feedback from multiple past clients about the limitation of Marten as a data source underneath UI grids, which isn’t particularly a new bit of feedback. In general, there also appears to be a massive opportunity to improve Marten’s usability for many users by having more robust support in the box for projecting event data to flat, denormalized tables.
I think I’d like to prioritize a series of work in 2026 to alleviate the complicated view problem:
The “Composite Projections” Epic where you might use the build products of upstream projections to create multi-stream projection views. This is also an opportunity to ratchet up even more scalability and throughput in the daemon. I’ve gotten positive feedback from a couple JasperFx clients about this. It’s also a big opportunity to increase the throughput and scalability of the Async Daemon by making fewer database requests
Revisit GroupJoin in the LINQ support even though that’s going to be absolutely miserable to build. GroupJoin() might end up being a much easier usage that all our Include() functionality.
A first class model to project Marten event data with EF Core. In this proposed model, you’d use an EF Core DbContext to do all the actual writes to a database.
Other than that, some other ideas that have kicked around for awhile are:
Improve the documentation and sample projects, especially around the usage of projections
Take a better look at the full text search features in Marten
Finally support the PostGIS extension in Marten. I think that could be something flashy and quick to build, but I’d strongly prefer to do this in the context of an actual client use case.
Continue to improve our story around multi-stream operations. I’m not enthusiastic about “Dynamic Boundary Consistency” (DCB) in regards to Marten though, so I’m not sure what this actually means yet. This might end up centering much more on the integration with Wolverine’s “aggregate handler workflow” which is already perfectly happy to support strong consistency models even with operations that touch more than one event stream.
Wolverine
Wolverine is by far and away the busiest part of the Critter Stack in terms of active development right now, but I think that slows down soon. To be honest, most work at this point is us reacting tactically to JasperFx client or user needs. In terms of general, strategic themes, I think that 2026 will involve:
In conjunction with “CritterWatch”, improving Wolverine’s management story around dead letter queueing
I would love to expand Wolverine’s database support beyond “just” SQL Server and PostgreSQL
Improving the Kafka integration. That’s not our most widely used messaging broker, but that seems to be the leading source of enhancement requests right now
New Critters?
We’ve done a lot of preliminary work to potentially build new Critter Stack event store alternatives based on different database engines. I’ve always believed that SQL Server would be the logical next database engine, but we’ve gotten fewer and fewer requests for this as PostgreSQL has become a much more popular database choice in the .NET ecosystem.
I’m not sure this will be a high priority in 2026, but you never know…
I was helping a new JasperFx Software client this week to best integrate a Domain Events strategy into their new Wolverine codebase. This client wanted to use the common model of using an EF Core DbContext to harvest domain events raised by different entities and relay those to Wolverine messaging with proper Wolverine transactional outbox support for system durability. As part of that assistance — and also to have some content for other Wolverine users trying the same thing later — I promised to write a blog post showing how I’d do this kind of integration myself with Wolverine and EF Core or at least consider a few options. To try to more permanently head this usage problem for other users, I went into mad scientist mode this evening and just rolled out a new Wolverine 5.6 with some important improvements to make this Domain Events pattern much easier to use in combination with EF Core.
Let’s start with some context about the general kind of approach I’m referring to with…
// Base class that establishes the pattern for publishing
// domain events within an entity
public abstract class Entity : IEntity
{
[NotMapped]
private readonly ConcurrentQueue<IDomainEvent> _domainEvents = new ConcurrentQueue<IDomainEvent>();
[NotMapped]
public IProducerConsumerCollection<IDomainEvent> DomainEvents => _domainEvents;
protected void PublishEvent(IDomainEvent @event)
{
_domainEvents.Enqueue(@event);
}
protected Guid NewIdGuid()
{
return MassTransit.NewId.NextGuid();
}
}
public class BacklogItem : Entity
{
public Guid Id { get; private set; }
[MaxLength(255)]
public string Description { get; private set; }
public virtual Sprint Sprint { get; private set; }
public DateTime CreatedAtUtc { get; private set; } = DateTime.UtcNow;
private BacklogItem() { }
public BacklogItem(string desc)
{
this.Id = NewIdGuid();
this.Description = desc;
}
public void CommitTo(Sprint s)
{
this.Sprint = s;
this.PublishEvent(new BacklogItemCommitted(this, s));
}
}
Note the CommitTo() method that publishes a BacklogItemCommitted event that in his sample is published via MediatR with some customization of an EF Core DbContext like this from the referenced post with some comments that I added:
public override async Task<int> SaveChangesAsync(CancellationToken cancellationToken = default(CancellationToken))
{
await _preSaveChanges();
var res = await base.SaveChangesAsync(cancellationToken);
return res;
}
private async Task _preSaveChanges()
{
await _dispatchDomainEvents();
}
private async Task _dispatchDomainEvents()
{
// Find any entity objects that were changed in any way
// by the current DbContext, and relay them to MediatR
var domainEventEntities = ChangeTracker.Entries<IEntity>()
.Select(po => po.Entity)
.Where(po => po.DomainEvents.Any())
.ToArray();
foreach (var entity in domainEventEntities)
{
// _dispatcher was an abstraction in his post
// that was a light wrapper around MediatR
IDomainEvent dev;
while (entity.DomainEvents.TryTake(out dev))
await _dispatcher.Dispatch(dev);
}
}
The goal of this approach is to make DDD style entity types the entry point and governing “decider” of all business behavior and workflow and give these domain model types a way to publish event messages to the rest of the system for side effects in the system outside of the state of the entity. Like for example, maybe the backlog system has to publish a message to a Slack room about the back log item being added to the sprint. You sure as hell don’t want your domain entity to have to know about the infrastructure you use to talk to Slack or web services or whatever.
Mechanically, I’ve seen this typically done with some kind of Entity base class that either exposes a collection of published domain events like the sample above, or puts some kind of interface like this directly into the Entity objects:
// Just assume that this little abstraction
// eventually relays the event messages to Wolverine
// or whatever messaging tool you're using
public interface IEventPublisher
{
void Publish<T>(T @event);
}
// Using a Nullo just so you don't have potential
// NullReferenceExceptions
public class NulloEventPublisher : IEventPublisher
{
public void Publish<T>(T @event)
{
// Do nothing.
}
}
public abstract class Entity
{
public IEventPublisher Publisher { get; set; } = new NulloEventPublisher();
}
public class BacklogItem : Entity
{
public Guid Id { get; private set; } = Guid.CreateVersion7();
public string Description { get; private set; }
// ZOMG, I forgot how annoying ORMs are. Use a document database
// and stop worrying about making things virtual just for lazy loading
public virtual Sprint Sprint { get; private set; }
public void CommitTo(Sprint sprint)
{
Sprint = sprint;
Publisher.Publish(new BackLotItemCommitted(Id, sprint.Id));
}
}
In the approach of using the abstraction directly inside of your entity classes, you incur the extra overhead of connecting the Entity objects loaded out of EF Core with the implementation of your IEventPublisher interface at runtime. I’ll do a few thought experiments later in this post and try out a couple different alternatives.
Before going back to EF Core integration ideas, let me deviate into…
Idiomatic Critter Stack Usage
Forget EF Core for a second, let’s examine a possible usage with the full “Critter Stack” and use Marten for Event Sourcing instead. In this case, a command handler to add a backlog item to a sprint could look something like this (folks, I didn’t spend much time thinking about how a back log system would be built here):
public record BackLotItemCommitted(Guid SprintId);
public record CommitToSprint(Guid BacklogItemId, Guid SprintId);
// This is utilizing Wolverine's "Aggregate Handler Workflow"
// which is the Critter Stack's flavor of the "Decider" pattern
public static class CommitToSprintHandler
{
public static Events Handle(
// The actual command
CommitToSprint command,
// Current state of the back log item,
// and we may decide to make the commitment here
[WriteAggregate] BacklogItem item,
// Assuming that Sprint is event sourced,
// this is just a read only view of that stream
[ReadAggregate] Sprint sprint)
{
// Use the item & sprint to "decide" if
// the system can proceed with the commitment
return [new BackLotItemCommitted(command.SprintId)];
}
}
In the code above we’re appending the BackLotItemCommitted event to Marten that’s returned from the method. If you need to carry out side effects outside of the scope of this handler using that event as a message input, you have a couple options to have Wolverine relay that through any of its messaging through the event forwarding (faster, but un-ordered) or event subscriptions (strictly ordered, but that always means slower).
I should also say that if the events returned from the function above are also being forwarded as messages and not just being appended to the Marten event store, that messaging is completely integrated with Wolverine’s transactional outbox support. That’s a key differentiation all by itself from a similar MediatR based approach that doesn’t come with outbox support.
That’s it, that’s the whole handler, but here are some things I would want you to take away from that code sample above:
Yes, the business logic is embedded directly in the handler method instead of being buried in the BacklogItem or Sprint aggregates. We are very purposely going down a Functional Programming (adjacent? curious?) approach where the logic is primarily in pure “Decider” functions
I think the code above clearly shows the relationship between the system input (the CommitToSprint command message) and the potential side effects and changes in state of the system. This relative ease of reasoning about the code is of the utmost importance for system maintainability. We can look at the handler code and know that executing that message will potentially lead to events or event messages being published. I’m going to hit this point again from some of the other potential approaches because I think this is a vital point.
Testability of the business logic is easy with the pure function approach
There are no marker interfaces, Entity base classes, or jumping through layers. There’s no repository or factory
So enough of that, let’s start with some possible alternatives for Wolverine integration of domain events from domain entity objects with EF Core.
Relay Events from Your Entity Subclass to Wolverine
Switching back to EF Core integration, let’s look at a possible approach to teach Wolverine how to scrape domain events for publishing from your own custom Event or IEventlayer supertype like this one that we’ll put behind our BackLogItem type:
// Of course, if you're into DDD, you'll probably
// use many more marker interfaces than I do here,
// but you do you and I'll do me in throwaway sample code
public abstract class Entity
{
public List<object> Events { get; } = new();
public void Publish(object @event)
{
Events.Add(@event);
}
}
public class BacklogItem : Entity
{
public Guid Id { get; private set; }
public string Description { get; private set; }
public virtual Sprint Sprint { get; private set; }
public DateTime CreatedAtUtc { get; private set; } = DateTime.UtcNow;
public void CommitTo(Sprint sprint)
{
Sprint = sprint;
Publish(new BackLotItemCommitted(Id, sprint.Id));
}
}
Let’s utilize this a little bit within a Wolverine handler, first with explicit code:
public static class CommitToSprintHandler
{
public static async Task HandleAsync(
CommitToSprint command,
ItemsDbContext dbContext)
{
var item = await dbContext.BacklogItems.FindAsync(command.SprintId);
var sprint = await dbContext.Sprints.FindAsync(command.SprintId);
// This method would cause an event to be published within
// the BacklogItem object here that we need to gather up and
// relay to Wolverine later
item.CommitTo(sprint);
// Wolverine's transactional middleware handles
// everything around SaveChangesAsync() and transactions
}
}
public static class CommitToSprintHandler
{
public static IStorageAction<BacklogItem> Handle(
CommitToSprint command,
// There's a naming convention here about how
// Wolverine "knows" the id for the BacklogItem
// from the incoming command
[Entity] BacklogItem item,
[Entity] Sprint sprint
)
{
// This method would cause an event to be published within
// the BacklogItem object here that we need to gather up and
// relay to Wolverine later
item.CommitTo(sprint);
// This is necessary to "tell" Wolverine to put transactional middleware around the handler
// Just taking in the right DbContext type as a dependency
// work work just as well if you don't like the Wolverine
// magic
return Storage.Update(item);
}
}
Now, let’s add some Wolverine configuration to just make this pattern work:
builder.Host.UseWolverine(opts =>
{
// Setting up Sql Server-backed message storage
// This requires a reference to Wolverine.SqlServer
opts.PersistMessagesWithSqlServer(connectionString, "wolverine");
// Set up Entity Framework Core as the support
// for Wolverine's transactional middleware
opts.UseEntityFrameworkCoreTransactions();
// THIS IS A NEW API IN Wolverine 5.6!
opts.PublishDomainEventsFromEntityFrameworkCore<Entity>(x => x.Events);
// Enrolling all local queues into the
// durable inbox/outbox processing
opts.Policies.UseDurableLocalQueues();
});
In the Wolverine configuration above, the EF Core transactional middleware now “knows” how to scrape out possible domain events from the active DbContext.ChangeTracker and publish them through Wolverine. Moreover, the EF Core transactional middleware is doing all the operation ordering for you so that the events are enqueued as outgoing messages as part of the transaction and potentially persisted to the transactional inbox or outbox (depending on configuration) before the transaction is committed.
To make this as clear as possible, this approach is completely reliant on the EF Core transactional middleware.
Oh, and also note that this domain event “scraping” is also supported and tested with the IDbContextOutbox<T> service if you want to use this in application code outside of Wolverine message handlers or HTTP endpoints.
This approach could also support the thread safe approach that the sample from the first section used in the future, but I’m dubious that that’s necessary.
If I were building a system that embeds domain event publishing directly in domain model entity classes, I would prefer this approach. But, let’s talk about another option that will not require any changes to Wolverine…
Relay Events from Entity to Wolverine Cascading Messages
In this approach, which I’m granting that some people won’t like at all, we’ll simply pipe the event messages from the domain entity right to Wolverine and utilize Wolverine’s cascading message feature.
This time I’m going to change the BacklogItem entity class to something like this:
public class BacklogItem
{
public Guid Id { get; private set; }
public string Description { get; private set; }
public virtual Sprint Sprint { get; private set; }
public DateTime CreatedAtUtc { get; private set; } = DateTime.UtcNow;
// The exact return type isn't hugely important here
public object[] CommitTo(Sprint sprint)
{
Sprint = sprint;
return [new BackLotItemCommitted(Id, sprint.Id)];
}
}
With the handler signature:
public static class CommitToSprintHandler
{
public static object[] Handle(
CommitToSprint command,
// There's a naming convention here about how
// Wolverine "knows" the id for the BacklogItem
// from the incoming command
[Entity] BacklogItem item,
[Entity] Sprint sprint
)
{
return item.CommitTo(sprint);
}
}
The approach above let’s you make the handler be a single pure function which is always great for unit testing, eliminates the need to do any customization of the DbContext type, makes it unnecessary to bother with any kind of IEventPublisher interface, and let’s you keep the logic for what event messages should be raised completely in your domain model entity types.
I’d also argue that this approach makes it more clear to later developers that “hey, additional messages may be published as part of handling the CommitToSprint command” and I think that’s invaluable. I’ll harp on this more later, but I think the traditional, MediatR-flavored approach to domain events from the first example at the top makes application code harder to reason about and therefore more buggy over time.
Embedding IEventPublisher into the Entities
Lastly, let’s move to what I think is my least favorite approach that I will from this moment be recommending against for any JasperFx clients but is now completely supported by Wolverine 5.6+! Let’s use an IEventPublisher interface like this:
// Just assume that this little abstraction
// eventually relays the event messages to Wolverine
// or whatever messaging tool you're using
public interface IEventPublisher
{
void Publish<T>(T @event) where T : IDomainEvent;
}
// Using a Nullo just so you don't have potential
// NullReferenceExceptions
public class NulloEventPublisher : IEventPublisher
{
public void Publish<T>(T @event) where T : IDomainEvent
{
// Do nothing.
}
}
public abstract class Entity
{
public IEventPublisher Publisher { get; set; } = new NulloEventPublisher();
}
public class BacklogItem : Entity
{
public Guid Id { get; private set; } = Guid.CreateVersion7();
public string Description { get; private set; }
// ZOMG, I forgot how annoying ORMs are. Use a document database
// and stop worrying about making things virtual just for lazy loading
public virtual Sprint Sprint { get; private set; }
public void CommitTo(Sprint sprint)
{
Sprint = sprint;
Publisher.Publish(new BackLotItemCommitted(Id, sprint.Id));
}
}
Now, on to a Wolverine implementation for this pattern. You’ll need to do just a couple things. First, add this line of configuration to Wolverine, and note there are no generic arguments here:
// This will set you up to scrape out domain events in the
// EF Core transactional middleware using a special service
// I'm just about to explain
opts.PublishDomainEventsFromEntityFrameworkCore();
Now, build a real implementation of that IEventPublisher interface above:
public class EventPublisher(OutgoingDomainEvents Events) : IEventPublisher
{
public void Publish<T>(T e) where T : IDomainEvent
{
Events.Add(e);
}
}
OutgoingDomainEvents is a service from the WolverineFx.EntityFrameworkCore Nuget that is registered as Scoped by the usage of the EF Core transactional middleware. Next, register your custom IEventPublisher with the Scoped lifecycle:
How you wire up IEventPublisher to your domain entities getting loaded out of the your EF Core DbContext? Frankly, I don’t want to know. Maybe a repository abstraction around your DbContext types? Dunno. I hate that kind of thing in code, but I perfectly trust *you* to do that and to not make me see that code.
What’s important is that within a message handler or HTTP endpoint, if you resolve the IEventPublisher through DI and use the EF Core transactional middleware, the domain events published to that interface will be piped correctly into Wolverine’s active messaging context.
Likewise, if you are using IDbContextOutbox<T>, the domain events published to IEventPublisher will be correctly piped to Wolverine if you:
Pull both IEventPublisher and IDbContextOutbox<T> from the same scoped service provider (nested container in Lamar / StructureMap parlance)
So, we’re going to have to do some sleight of hand to keep your domain entities synchronous
Last note, in unit testing you might use a stand in “Spy” like this:
public class RecordingEventPublisher : OutgoingMessages, IEventPublisher
{
public void Publish<T>(T @event)
{
Add(@event);
}
}
Summary
I have always hated this Domain Events pattern and much prefer the full “Critter Stack” approach with the Decider pattern and event sourcing. But, Wolverine is picking up a lot more users who combine it with EF Core (and JasperFx deeply appreciates these customers!) and I know damn well that there will be more and more demand for this pattern as people with more traditional DDD backgrounds and used to more DI-reliant tools transition to Wolverine. Now was an awfully good time to plug this gap.
If it was me, I would also prefer having an Entity just store published domain events on itself and depend on Wolverine “scraping” these events out of the DbContext change tracking so you don’t have to do any kind of gymnastics and extra layering to attach some kind of IEventPublisher to your Entity types.
Lastly, if you’re comparing this straight up to the MediatR approach, just keep in mind that this is not an oranges to oranges comparison because Wolverine also needs to correctly utilize its transactional outbox for resiliency, which is a feature that MediatR does not provide.
Starting today, Babu Annamalai is taking a larger role at JasperFx Software (LLC) to help expand our support coverage to just about every time zone on the planet. Babu is a long time member of the Marten and now Critter Stack core team. In addition to some large contributions like the Partial API in Marten and smoothing out database migrations, he’s been responsible for most of our DevOps support and documentation websites that helps keep the Critter Stack moving forward.
A little more about Babu:
Babu has over 28 years of experience, excelling in technology and product management roles within renowned enterprise firms. His expertise lies in crafting cutting-edge products and solutions customised for the ever-evolving domain of investment management and research. Co-maintainer of Marten. Owns and manages .NET OSS libraries ReverseMarkdown.Net and MysticMind.PostgresEmbed. Drawing from his wealth of knowledge, he recently embarked on a thrilling entrepreneurial journey, establishing Radarleaf Technologies, providing top-notch consultancy and bespoke software development services.
My internal code name for one of the new features I’m describing is “multi-stage tracked sessions” which somehow got me thinking of the ZZ Top song “Stages” and their Afterburner album because the sound track for getting this work done this week. Not ZZ Top’s best stuff, but there’s still some bangers on it, or at least *I* loved how it sounded on my Dad’s old phonograph player when I was a kid. For what it’s worth, my favorite ZZ Top albums cover to cover are Degüello and their La Futura comeback album.
I was heavily influenced by Extreme Programming in my early career and that’s made me have a very deep appreciation for the quality of “Testability” in the development tools I use and especially for the tools like Marten and Wolverine that I work on. I would say that one of the differentiators for Wolverine over other .NET messaging libraries and application frameworks is its heavy focus and support for automated testing of your application code.
The Critter Stack community released Marten 8.14 and Wolverine 5.1 today with some significant improvements to our testing support. These new features mostly originated from my work with JasperFx Software clients that give me a first hand look into what kinds of challenges our users hit automating tests that involve multiple layers of asynchronous behavior.
Jumping into an example, let’s say that your system interacts with another service that estimates delivery costs for ordering items. At some point in the system you might reach out through a request/reply call in Wolverine to estimate an item delivery before making a purchase like this code:
// This query message is normally sent to an external system through Wolverine
// messaging
public record EstimateDelivery(int ItemId, DateOnly Date, string PostalCode);
// This message type is a response from an external system
public record DeliveryInformation(TimeOnly DeliveryTime, decimal Cost);
public record MaybePurchaseItem(int ItemId, Guid LocationId, DateOnly Date, string PostalCode, decimal BudgetedCost);
public record MakePurchase(int ItemId, Guid LocationId, DateOnly Date);
public record PurchaseRejected(int ItemId, Guid LocationId, DateOnly Date);
public static class MaybePurchaseHandler
{
public static Task<DeliveryInformation> LoadAsync(
MaybePurchaseItem command,
IMessageBus bus,
CancellationToken cancellation)
{
var (itemId, _, date, postalCode, budget) = command;
var estimateDelivery = new EstimateDelivery(itemId, date, postalCode);
// Let's say this is doing a remote request and reply to another system
// through Wolverine messaging
return bus.InvokeAsync<DeliveryInformation>(estimateDelivery, cancellation);
}
public static object Handle(
MaybePurchaseItem command,
DeliveryInformation estimate)
{
if (estimate.Cost <= command.BudgetedCost)
{
return new MakePurchase(command.ItemId, command.LocationId, command.Date);
}
return new PurchaseRejected(command.ItemId, command.LocationId, command.Date);
}
}
And for a little more context, the EstimateDelivery message will always be sent to an external system in this configuration:
var builder = Host.CreateApplicationBuilder();
builder.UseWolverine(opts =>
{
opts
.UseRabbitMq(builder.Configuration.GetConnectionString("rabbit"))
.AutoProvision();
// Just showing that EstimateDelivery is handled by
// whatever system is on the other end of the "estimates" queue
opts.PublishMessage<EstimateDelivery>()
.ToRabbitQueue("estimates");
});
In testing scenarios, maybe the external system isn’t available at all, or it’s just much more challenging to run tests that also include the external system, or maybe you’d just like to write more isolated tests against your service’s behavior before even trying to integrate with the other system (my personal preference anyway). To that end we can now stub the remote handling like this:
public static async Task try_application(IHost host)
{
host.StubWolverineMessageHandling<EstimateDelivery, DeliveryInformation>(
query => new DeliveryInformation(new TimeOnly(17, 0), 1000));
var locationId = Guid.NewGuid();
var itemId = 111;
var expectedDate = new DateOnly(2025, 12, 1);
var postalCode = "78750";
var maybePurchaseItem = new MaybePurchaseItem(itemId, locationId, expectedDate, postalCode,
500);
var tracked =
await host.InvokeMessageAndWaitAsync(maybePurchaseItem);
// The estimated cost from the stub was more than we budgeted
// so this message should have been published
// This line is an assertion too that there was a single message
// of this type published as part of the message handling above
var rejected = tracked.Sent.SingleMessage<PurchaseRejected>();
rejected.ItemId.ShouldBe(itemId);
rejected.LocationId.ShouldBe(locationId);
}
After calling making this call:
host.StubWolverineMessageHandling<EstimateDelivery, DeliveryInformation>(
query => new DeliveryInformation(new TimeOnly(17, 0), 1000));
Calling this from our Wolverine application:
// Let's say this is doing a remote request and reply to another system
// through Wolverine messaging
return bus.InvokeAsync<DeliveryInformation>(estimateDelivery, cancellation);
Will use the stubbed logic we registered. This is enabling you to use fake behavior for difficult to use external services.
For the next test, we can completely remove the stub behavior and revert back to the original configuration like this:
public static void revert_stub(IHost host)
{
// Selectively clear out the stub behavior for only one message
// type
host.WolverineStubs(stubs =>
{
stubs.Clear<EstimateDelivery>();
});
// Or just clear out all active Wolverine message handler
// stubs
host.ClearAllWolverineStubs();
}
There’s a bit more to the feature you can read about in our documentation, but hopefully you can see right away how this can be useful for effectively stubbing out the behavior of external systems through Wolverine in tests.
And yes, some older .NET messaging frameworks already had *this* feature and it’s been occasionally requested from Wolverine, so I’m happy to say we have this important and useful capability.
Forcing Marten’s Asynchronous Daemon to “Catch Up”
Marten has had the IDocumentStore.WaitForNonStaleProjectionDataAsync(timeout) API (see the documentation for an example) for quite awhile that lets you pause a test while any running asynchronous projections or subscriptions run and catch up to wherever the event store “high water mark” was when you originally called the method. Hopefully, this lets ongoing background work proceed until the point where it’s now safe for you to proceed to the “Assert” part of your automated tests. As a convenience, this API is also available through extension methods on both IHost and IServiceProvider.
We’ve recently invested time into this API to make it provide much more contextual information about what’s happening asynchronously if the “waiting” does not complete. Specifically, we’ve made the API throw an exception that embeds a table of where every asynchronous projection or subscription ended up at compared to the event store’s “high water mark” (the highest sequential identifier assigned to a persisted event in the database). In this last release we made sure that that textual table also shows any projections or subscriptions that never recorded any process with a sequence of “0” so you can see what did or didn’t happen. We have also changed the API to record any exceptions thrown by the asynchronous daemon (serialization errors? application errors from *your* projection code? database errors?) and have those exceptions piped out in the failure messages when the “WaitFor” API does not successfully complete.
Okay, with all of that out of the way, we also added a completely new, slightly alternative for the asynchronous daemon that just forces the daemon to quickly process all outstanding events through every asynchronous projection or subscription right this second and throw up any exceptions that it encounters. We call this the “catch up” API:
using var daemon = await theStore.BuildProjectionDaemonAsync();
await daemon.CatchUpAsync(CancellationToken.None);
This mode is faster and hopefully more reliable than WaitFor***** because it’s happening inline and shortcuts a lot of the normal asynchronous polling and messaging within the normal daemon processing.
There’s also an IHost.CatchUpAsync() or IServiceProvider.CatchUpAsync() convenience method for test usage as well.
Multi Stage Tracked Sessions
I’m obviously biased, but I’d say that Wolverine’s tracked session capability is a killer feature that makes Wolverine stand apart from other messaging tools in the .NET ecosystem and it goes a long way toward making integration testing through Wolverine asynchronous messaging be productive and effective.
But, what if you have a testing scenario where you:
Carry out some kind of action (an HTTP request invoked through Alba? publishing a message internally within your application?) that leads to messages being published in Wolverine that might in turn lead to even more messages getting published within your Wolverine system or other tracked systems
Along the way, handling one or more commands leads to events being appended to a Marten event store
That might sound a little bit contrived, but it reflects real world scenarios I’ve discussed with multiple JasperFx clients in just the past couple weeks. With their help and some input from the community, we came up with this new extension to Wolverine’s “tracked sessions” to also track and wait for work spawned by Marten. Consider this bit of code from the tests for this feature:
var tracked = await _host.TrackActivity()
// This new helper just resets the main Marten store
// Equivalent to calling IHost.ResetAllMartenDataAsync()
.ResetAllMartenDataFirst()
.PauseThenCatchUpOnMartenDaemonActivity(CatchUpMode.AndResumeNormally)
.InvokeMessageAndWaitAsync(new AppendLetters(id, ["AAAACCCCBDEEE", "ABCDECCC", "BBBA", "DDDAE"]));
To add some context, handling the AppendLetters command message appends events to a Marten stream and possibly cascades another Wolverine message that also appends events. At the same time, there are asynchronous projections and event subscriptions that will publish messages through Wolverine as they run. We can now make this kind of testing scenario much more feasible and hopefully reliable (async heavy tests are super prone to being blinking tests) through the usage of the PauseThenCatchUpOnMartenDaemonActivity() extension method from the Wolverine.Marten library.
In the bit of test code above, that API is:
Registering a “before” action to pause all async daemon activity before executing the “Act” part of the tracked session which in this case is calling IMessageBus.InvokeAsync() against an AppendLetters command
Registering a 2nd stage of the tracked session
When this tracked session is executed, the following sequence happens:
The tracked session calls Marten’s ResetAllMartenDataAsync() in the main DocumentStore for the application to effectively rewind the database state down to your defined initial state
IMessageBus.InvokeAsync(AppendLetters) is called as the actual “execution” of the tracked session
The tracked session is watching everything going on with Wolverine messaging and waits until all “cascaded” messages are complete — and that is recursive. Basically, the tracked session waits until all subsequent messaging activity in the Wolverine application is complete
The 2nd stage we registered to “CatchUp” means the tracked session calls Marten’s new “CatchUp” API to force all asynchronous projections and event subscriptions in the system to immediately process all persisted events. This also restarts the tracked session monitoring of any Wolverine messaging activity so that this stage will only complete when all detected Wolverine messaging activity is completed.
By using this new capability inside of the older tracked session feature, we’re able to effectively test from the original message input through any subsequent messages triggered by the original message through asynchronous Marten behavior caused by the original messages which might in turn publish yet more messages through Wolverine.
Long story short, this gives us a reliable way to know when the “Act” part of a test is actually complete and proceed to the “Assert” portion of a test. Moreover, this new feature also tries really hard to bring out some visibility into the asynchronous Marten behavior and the second stage messaging behavior in the case of test failures.
Summary
None of this is particularly easy conceptually, and it’s admittedly here because of relatively hard problems in test automation that you might eventually run into. Selfishly, I needed to get these new features into the hands of a client tomorrow and ran out of time to better document these new features, so you get this braindump blog post.
If it helps, I’m going to talk through these new capabilities a bit more in our next Critter Stack live stream tomorrow (Nov. 6th):
Just to set myself up with some pressure to perform, let me hype up a live stream on Wolverine I’m doing later this week!
I’m doing a live stream on Thursday afternoon (U.S. friendly this time) entitled Vertical Slices the Critter Stack Way based on a fun, meandering talk I did for Houston DNUG and an abbreviated version at Commit Your Code last month.
So, yes, it’s technically about the “Vertical Slice Architecture” in general and specifically with Marten and Wolverine, but more importantly, the special sauce in Wolverine that does more — in my opinion of course — than any other server side .NET application framework to simplify your code and improve testability. In the live stream, I’m going to discuss:
A little bit about how I think modern layered architecture approaches and “Ports and Adapters” style approaches can sometimes lead to poor results over time
The qualities of a code base that I think are most important (the ability to reason about the behavior of the code, testability of all sorts, ease of iteration, and modularity)
How Wolverine’s low code ceremony improves outcomes and the qualities I listed above by reducing layering and shrinking your code into a much tighter vertical slice approach so you can actually see what your system does later on
Adopting Wolverine’s idiomatic “A-Frame Architecture” approach and “imperative shell, functional core” thinking to improve testability
A sampling of the ways that Wolverine can hugely simplify data access in simpler scenarios and how it can help you keep more complicated data access much closer to behavioral code so you can actually reason about the cause and effects between those two things. And all of that while happily letting you leverage every bit of power in whatever your database or data access tooling happens to be. Seriously, layering approaches and abstractions that obfuscate the database technologies and queries within your system are a very common source of poor system performance in Onion/Clean Architecture approaches.
Using Wolverine.HTTP as an alternative AspNetCore Endpoint model and why that’s simpler in the end than any kind of “Mediator” tooling inside of MVC Core or Minimal API
Wolverine’s adaptive approach to middleware
The full “Critter Stack” combination with Marten and how that leads to arguably the simplest and cleanest code for CQRS command handlers on the planet
Wolverine’s goodies for the majority of .NET devs using the venerable EF Core tooling as well
If you’ve never heard of Wolverine or haven’t really paid much attention to it yet, I’m most certainly inviting you to the live stream to give it a chance. If you’ve blown Wolverine off in the past as “yet another messaging tool in .NET,” come find out why that is most certainly not the full story because Wolverine will do much more for you within your application code than other, mere messaging frameworks in .NET or even any of the numerous “Mediator” tools floating around.
In the announcement for the Wolverine 5.0 release last week, I left out a pretty big set of improvements for modular monolith support, specifically in how Wolverine can now work with multiple databases from one service process.
And all of those features are supported for Marten, EF Core with either PostgreSQL or SQL Server, and RavenDb.
Back to the “modular monolith” approach and what I’m seeing folks do or want to do is some combination of:
Use multiple EF Core DbContext types that target the same database, but maybe with different schemas
Use Marten’s “ancillary or separated store” feature to divide the storage up for different modules against the same database
Wolverine 3/4 supported the previous two bullet points, but now Wolverine 5 will be able to support any combination of every possible option in the same process. That even includes the ability to:
Use multiple DbContext types that target completely different databases altogether
Mix and match with Marten ancillary stores that target completely different database
Use RavenDb for some modules, even if others use PostgreSQL or SQL Server
Utilize either Marten’s built in multi-tenancy through a database per tenant or Wolverine’s managed EF Core multi-tenancy through a database per tenant
And now do that in one process while being able to support Wolverine’s transactional inbox, outbox, scheduled messages, and saga support for every single database that the application utilizes. And oh, yeah, from the perspective of the future CritterWatch, you’ll be able to use Wolverine’s dead letter management services against every possible database in the service.
Okay, this is the point where I do have to admit that the RavenDb support for the dead letter administration is lagging a little bit, but we’ll get that hole filled in soon.
Here’s an example from the tests:
var builder = Host.CreateApplicationBuilder();
var sqlserver1 = builder.Configuration.GetConnectionString("sqlserver1");
var sqlserver2 = builder.Configuration.GetConnectionString("sqlserver2");
var postgresql = builder.Configuration.GetConnectionString("postgresql");
builder.UseWolverine(opts =>
{
// This helps Wolverine "know" how to share inbox/outbox
// storage across logical module databases where they're
// sharing the same physical database but with different schemas
opts.Durability.MessageStorageSchemaName = "wolverine";
// This will be the "main" store that Wolverine will use
// for node storage
opts.Services.AddMarten(m =>
{
m.Connection(postgresql);
}).IntegrateWithWolverine();
// "An" EF Core module using Wolverine based inbox/outbox storage
opts.UseEntityFrameworkCoreTransactions();
opts.Services.AddDbContextWithWolverineIntegration<SampleDbContext>(x => x.UseSqlServer(sqlserver1));
// This is helping Wolverine out by telling it what database to use for inbox/outbox integration
// when using this DbContext type in handlers or HTTP endpoints
opts.PersistMessagesWithSqlServer(sqlserver1, role:MessageStoreRole.Ancillary).Enroll<SampleDbContext>();
// Another EF Core module
opts.Services.AddDbContextWithWolverineIntegration<ItemsDbContext>(x => x.UseSqlServer(sqlserver2));
opts.PersistMessagesWithSqlServer(sqlserver2, role:MessageStoreRole.Ancillary).Enroll<ItemsDbContext>();
// Yet another Marten backed module
opts.Services.AddMartenStore<IFirstStore>(m =>
{
m.Connection(postgresql);
m.DatabaseSchemaName = "first";
});
});
I’m certainly not saying that you *should* run out and build a system that has that many different persistence options in a single deployable service, but now you *can* with Wolverine. And folks have definitely wanted to build Wolverine systems that target multiple databases for different modules and still get every bit of Wolverine functionality for each database.
Summary
Part of the Wolverine 5.0 work was also Jeffry Gonzalez and I pushing on JasperFx’s forthcoming “CritterWatch” tool and looking for any kind of breaking changes in the Wolverine “publinternals” that might be necessary to support CritterWatch. The “let’s let you use all the database options at one time!” improvements I tried to show in the post were suggested by the work we are doing for dead letter message management in CritterWatch.
I shudder to think how creative folks are going to be with this mix and match ability, but it’s cool to have some bragging rights over these capabilities because I don’t think that any other .NET tool can match this.