
Some of this is going to be specific to a .Net ecosystem, but most of what I’m talking about here I think should be applicable to most development shops. This is more or less a companion white paper for a big internal presentation I did at work this week.
My team at work is tasked with a multi-year code and architecture modernization across our large technical platforms. To give just a little bit of context, it’s a familiar story. We have some very large, very old, complex monolithic systems in production using some technologies, frameworks, and libraries that in a perfect world we’d like to update or replace. Being that quite a bit of code was written before Test Driven Development was just a twinkle in Kent Beck’s eye, the automated test coverage on parts of the code isn’t what we’d like it to be.
With all that said, to any of my colleagues that read this, I’d say that we’re in much better shape quality and ecosystem wise than the average shop with old, continuously developed systems.
During a recent meeting right before Christmas, one of my colleagues had the temerity to ask “what’s the end goal of modernization and when can we say we’re done?” — which set off some furious thinking, conversations within the team, and finally a presentation to the rest of our development groups.

We came up with these three main goals for our modernization efforts:
- Arrive at a point where we can practice Continuous Delivery (CD) within all our major product lines
- Improved Developer (and Tester) Happiness
- System Performance
Arguably, I’d say that being able to practice Continuous Delivery with a corresponding DevOps culture would help us achieve the other two goals, so I’m almost ready to declare that our main goal. Everything else that’s been on our “modernization agenda” is arguably just an intermediate step on the way to the goal of continuous delivery, or another goal that is at least partially unlocked by the advances we’ll have to make in order to get to continuous delivery.
Intermediate Steps
Speaking of the major intermediate or enabling steps we’ve identified, I took a shot at showing what we think are the major enabling steps for our future CD strategy in a diagram:
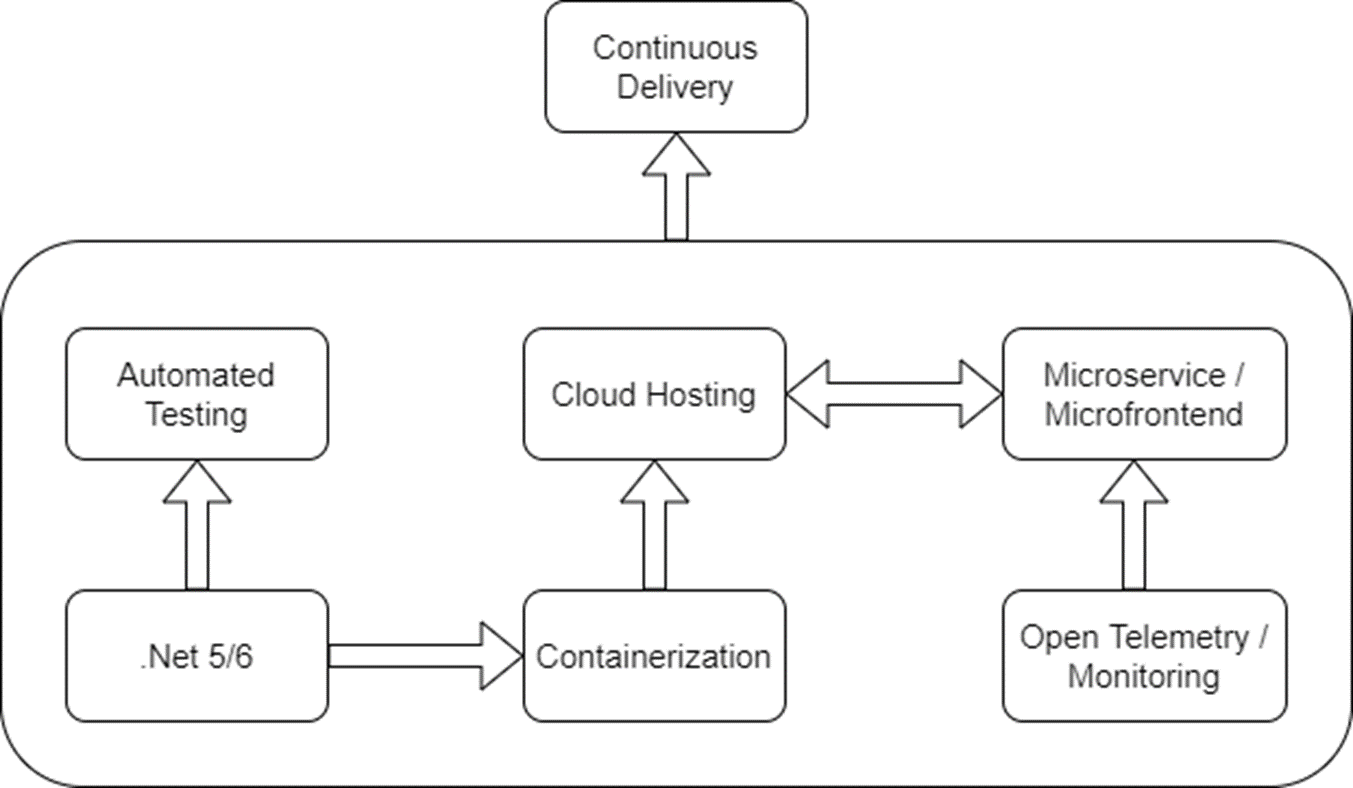
Upgrading to .Net vLatest
Upgrading from the full “classic” Windows-only version of .Net to the latest version of .Net and ASP.Net Core is taking up most of our hands on focus right now. There’s probably some performance gains to be had by merely updating to the latest .Net 5/6, but I see the big advantages to the latest .Net versions as being much more container friendly and allowing us flexibility on hosting options (Linux containers) compared to where we are now. I personally think that the recent generations of .Net and ASP.Net Core are far easier to work with in automated testing scenarios, and that should hopefully be a major enable of CD processes for us.
Most importantly of all, I’d like to get back to using a Mac for daily development work, so there’s that.
Improved Automated Testing
We’re fortunately starting from a decent base of test automation, but there’s plenty of opportunities to get better before we can support more frequent releases. (I’ve written quite a bit about automated testing here). Long story short, I think we have some opportunities to:
- Get better at writing testable code for easier and more effective unit testing
- Introduce a lot more integration testing in the middle zone of the stereotypical “test pyramid”
- Cut back on expensive Selenium-based testing wherever possible in favor of some other form of more efficient test automation. See Jeremy’s Only Rule of Testing.
Since all of this is interrelated anyway, “testability” is absolutely one of the factors we’ll use to decide where service boundaries are as we try to slice our large monoliths into smaller, more focused services. If it’s not valuable to test a service by itself without including other services, then that service boundary is probably wrong.
Containerization
This comes up a lot at work, but I’d call this as mostly an enabler step toward deploying to cloud hosting and easier incremental deployment than we have today rather than any kind of end in itself, especially in areas where we need elastic scaling. I think being able to run our services in containers also going to be helpful for the occasional time when you need to test locally against multiple services or processes.
And yeah, we could try to do a lift and shift to move our big full .Net framework apps to virtual machines in the cloud or try out Windows containers, but previous analysis has suggested that that’s not viable for us. Plus nobody wants to do that.
Open Telemetry Tracing and Production Monitoring
This effort is fortunately well underway, but one of our intermediate goals is to apply effective Open Telemetry tracing through all our products, and I say that for these reasons:
- It enables us to use a growing off the shelf ecosystem of visualization and metrics tooling
- I think it’s an invaluable debugging tool, especially when you have asynchronous messaging or dependencies on external systems — and we’re only going to be increasing our reliance on messaging as we move more and more to micro-services
- Open Telemetry is very handy in diagnosing performance or throughput problems by allowing you to “see” the context of what is happening within and across systems during a logical business operation.
To the last point, my key example of this was helping a team last year analyze some performance issues in their web services. An experienced developer will probably look through database logs to identify slow queries that might explain the poor performance as one of their first steps, but in this case that turned up no single query that was slow enough to explain the performance issues. Fortunately, I was able to diagnose the issue as an N+1 query issue by reading through the code, but let’s just say that I got lucky.
If we’d had open telemetry tracing between the web service calls and the database queries that each service invocation made, I think we would have been able to quickly see a relationship between slow web service calls and the sheer number of little database queries that the web service was making during the slow web service requests, which should have led the team to immediately suspect an N+1 problem.
As for production monitoring, we of course already do that but there’s some opportunity to be more responsive at least to performance issues detected by the monitoring rules. We’re working under the assumption that deploying more often and more incrementally means that we’ll also have to be better at detecting production issues. Not that you purposely try to let problems get through testing, but if we’re going to convince the greater company that it’s safe to deploy small changes in an automated fashion, we need to have ways to rapidly detect when new problems in production are introduced.
Again, the general theme is for us to be resilient and adaptive because problems are inevitable — but don’t let the fear of potential problems put us into an analysis paralysis spiral.
Cloud Hosting
I think that’s a major enabler of continuous delivery, with the real goal for us being more flexible in how our development, testing, and production environments are configured as we continue to break up the monolith codebases and change our current architecture. I’d also love for us to be able to flexibly spin up environments for testing on demand, and tear them down when they’re not needed without a lot of formal paperwork in the middle.
There might also be an argument for shifting to the cloud if we could reduce hosting and production support costs along the way, but I think there’s a lot of analysis left to do before we can make that claim to the folks in the high backed chairs.
System Performance
Good runtime performance and meeting our SLA agreements for such is absolutely vital for us as medical analytics company. I wrestled quite a bit with making this a first class goal of our “modernization” initiative and came down on the side of “yes, but…” My thinking here, with some agreement from other folks, is that system performance issues will be much easier to address when we’re backed by a continuous delivery backbone.
There’s something to be said for doing upfront architecture work to consider known performance risks before a single line of code is written, but the truth is that a great deal of the code is already written. Moreover, the performance issues and bottlenecks that pop up in production aren’t always where we would have expected them to be during upfront architecture efforts anyway.
Improving performance in a complicated system is generally going to require a lot of measurement and iteration. Knowing that, having the faster release cycle made safe by effective automated test coverage should help us react quicker to performance problems or take advantage of newer ideas to improve performance as we learn more about how our systems behave or gain some insights into client data sets. Likewise, we’ll have to improve our production monitoring and instrumentation to anyway to enable continuous delivery, and we’re hopeful that that will also help us more quickly identify and diagnose performance issues.
To phrase this a bit more bluntly, I believe that upfront design and architecture can be valuable and sometimes necessary, but consistent success in software development is more likely a result of feedback and adaptation over time than being dependent on getting everything right the first time.
Ending this post abruptly….
I’m tired, it’s late, and I’m going to play the trick of making this a blog series instead of one gigantic post that never gets finished. In following posts, I’d like to discuss my thoughts on:
- Creating the circumstances for “Developer Happiness” with some thinking about what kind of organizational structure and technical ecosystem allows developers and testers to be maximally productive and at least have a chance to be happy within their roles
- Some thinking around micro-services and micro-frontends as we try to break up the big ol’ monoliths with some focus on intermediate steps to get there
