This is continuing a series about multi-tenancy with Marten, Wolverine, and ASP.Net Core:
- What is it and why do you care?
- Marten’s “Conjoined” Model (this post)
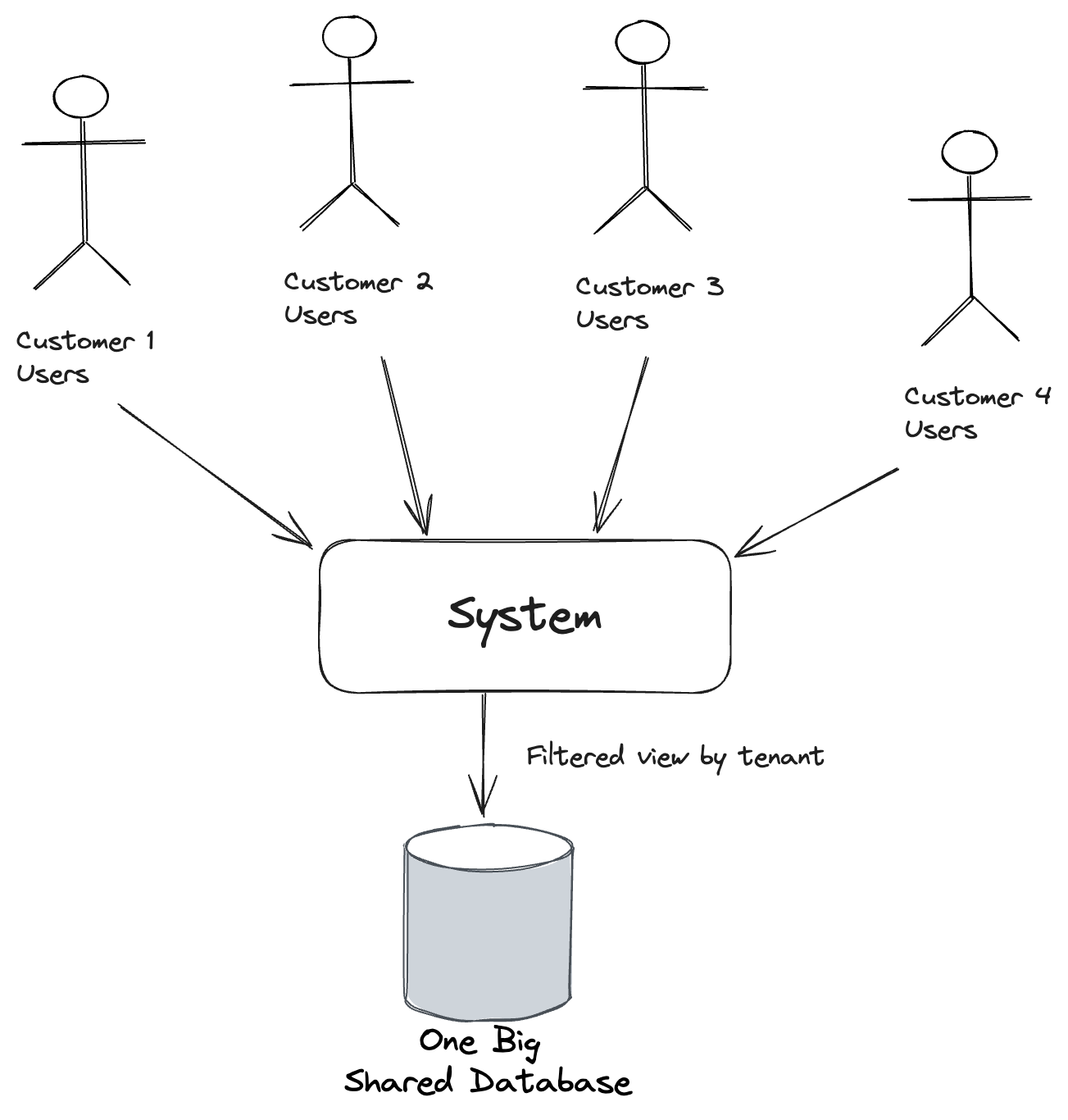
Let’s say that you definitely have the need for multi-tenanted storage in your system, but don’t expect enough data to justify splitting the tenant data over multiple databases, or maybe you just really don’t want to mess with all the extra overhead of multiple databases.
“Conjoined” is a term I personally coined for Marten years ago and isn’t anything that’s an “official” term in the industry. I’m not aware of any widely used pattern name for this strategy, but there surely is somewhere since this is so common.
This is where Marten’s “Conjoined” multi-tenancy model comes into play. Let’s say that we have a little document in our system named User just to store information about our users:
public class User
{
public User()
{
Id = Guid.NewGuid();
}
public List<Friend> Friends { get; set; }
public string[] Roles { get; set; }
public Guid Id { get; set; }
public string UserName { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string? Nickname { get; set; }
public bool Internal { get; set; }
public string Department { get; set; } = "";
public string FullName => $"{FirstName} {LastName}";
public int Age { get; set; }
public DateTimeOffset ModifiedAt { get; set; }
public void From(User user)
{
Id = user.Id;
}
public override string ToString()
{
return $"{nameof(FirstName)}: {FirstName}, {nameof(LastName)}: {LastName}";
}
}
Now, the User document certainly needs to be tracked within a single logical tenant, so I’m going to tell Marten to do exactly that:
// This is the same syntax to configuring Marten
// by IServiceCollection.AddMarten()
using var store = DocumentStore.For(opts =>
{
// other configuration
// Make *only* the User document be stored by tenant
opts.Schema.For<User>().MultiTenanted();
});
In the case above, I am only telling Marten to make the User document be multi-tenanted as it’s frequently valuable — and certainly possible — for some reference documents to be common for all tenants. If instead we just wanted to say “all documents and the event store should be multi-tenanted,” we can do this:
using var store = DocumentStore.For(opts =>
{
// other configuration
opts.Policies.AllDocumentsAreMultiTenanted();
opts.Events.TenancyStyle = TenancyStyle.Conjoined;
});
Either way, if we’ve established that User should be multi-tenanted, Marten will add a tenant_id column to the storage table for the User document like this:
DROP TABLE IF EXISTS public.mt_doc_user CASCADE;
CREATE TABLE public.mt_doc_user (
tenant_id varchar NOT NULL DEFAULT '*DEFAULT*',
id uuid NOT NULL,
data jsonb NOT NULL,
mt_last_modified timestamp with time zone NULL DEFAULT (transaction_timestamp()),
mt_version uuid NOT NULL DEFAULT (md5(random()::text || clock_timestamp()::text)::uuid),
mt_dotnet_type varchar NULL,
CONSTRAINT pkey_mt_doc_user_tenant_id_id PRIMARY KEY (tenant_id, id)
);
As of Marten 7, Marten also places the tenant_id first in the primary key for more efficient index usage when querying large data tables.
You might also notice that Marten adds tenant_id to the primary key for the table. Marten will happily allow you to use the same identity for documents in different tenants. And even though that’s unlikely with a Guid as the identity, it’s very certainly possible with other identity strategies and early Marten users hit that occasionally.
Let’s see the conjoined tenancy in action:
// I'm creating a session specifically for a tenant id of
// "tenant1"
using var session1 = store.LightweightSession("tenant1");
// My youngest & I just saw the Phantom Menace in the theater
var user = new User { FirstName = "Padme", LastName = "Amidala" };
// Marten itself assigns the identity at this point
// if the document doesn't already have one
session1.Store(user);
await session1.SaveChangesAsync();
// Let's open a session to a completely different tenant
using var session2 = store.LightweightSession("tenant2");
// Try to find the same user we just persisted in the other tenant...
var user2 = await session2.LoadAsync<User>(user.Id);
// And it shouldn't exist!
user2.ShouldBeNull();
In the very last call to Marten to try to load the same User, but from the “tenant2” tenant used this SQL:
select d.id, d.data from public.mt_doc_user as d where id = $1 and d.tenant_id = $2
: f746f237-ed4f-4aaa-b805-ad05f7ae2cd3
: tenant2
If you squint really hard, you can see that Marten automatically stuck in a second WHERE filter for the current tenant id. Moreover, if we switch to LINQ and try to query that way like so:
var user3 = await session2.Query<User>().SingleOrDefaultAsync(x => x.Id == user.Id);
user3.ShouldBeNull();
Marten is still quietly sticking in that tenant_id == [tenant id] filter for us with this SQL:
select d.id, d.data from public.mt_doc_user as d where (d.tenant_id = $1 and d.id = $2) LIMIT $3;
$1: tenant2
$2: bfc53828-d56b-4fea-8d93-e8a22fe2db40
$3: 2
If you really, really need to do this, you can query across tenants with some special Marten LINQ helpers:
var all = await session2
.Query<User>()
// Notice AnyTenant()
.Where(x => x.AnyTenant())
.ToListAsync();
all.ShouldContain(x => x.Id == user.Id);
Or for specific tenants:
var all = await session2
.Query<User>()
// Notice the Where()
.Where(x => x.TenantIsOneOf("tenant1", "tenant2", "tenant3"))
.ToListAsync();
all.ShouldContain(x => x.Id == user.Id);
Summary
While I don’t think folks should willy nilly build out the “Conjoined” model from scratch without some caution, Marten’s model is pretty robust after 8-9 years of constant use from a large, unfortunately for me the maintainer, creative user base.
I didn’t discuss the Event Sourcing functionality in this post, but do note that Marten’s conjoined tenancy model also applies to Marten’s event store and the projected documents built by Marten as well.
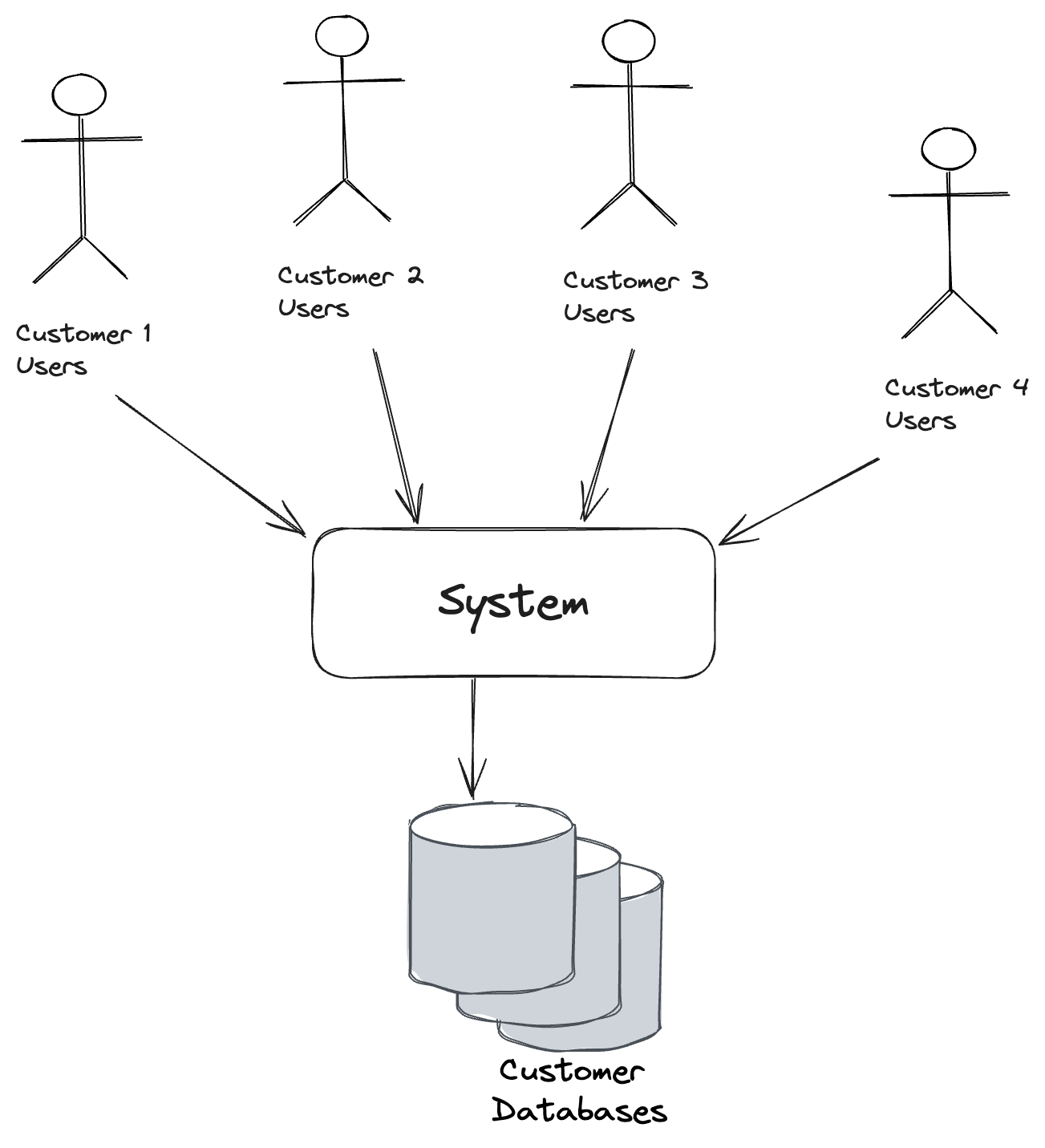
In the next post, we’ll branch out to using different databases for different tenants.