Hey, JasperFx Software is completely open for business, and ready to help your company make the most of your software development initiatives. While we’d be thrilled to work with our own “critter stack” tooling, we’re also very capable of helping you with software modernization, architectural reviews, and test automation challenges with whatever technical stack you happen to be using. Contact us at any time at sales@jasperfx.net for more information.
The DotNetRocks guys let me come on to talk with them for a show called Minimal Architecture with Jeremy Miller. Along the way, we talked about the latest happenings with the “Critter Stack,” why I’m absolutely doubling down on my criticisms of the Clean Architecture as it is practiced, and a lot about how to craft maintainable codebases with lower ceremony vertical slice architecture approaches — including how Wolverine and Marten absolutely help make that a reality.
Regardless of whether or not you’re taking the plunge into the “Critter Stack” tools or using a completely different technical stack, JasperFx Software is ready to engage with your shop for any help you might want on software architecture, test automation, modernization efforts, or helping your teams be more effective with Test Driven Development. Contact us anytime at sales@jasperfx.net.
In their first joint webinar, Oskar and Jeremy demonstrate how combining Wolverine and Marten can lead to a very low ceremony Event Sourcing and CQRS architecture. More than just that, we demonstrate how this tooling is purposely designed to lead to isolating the business logic for easy testing and good maintainability over time.
Jeremy joins Oskar’s Event Sourcerers Webinar Series to talk Wolverine and Marten
Last week we talked about code organization in a post-hexagonal world, where we decried the explosion of complexity that often comes from prescriptive architectures and “noun-centric” code organization. Let’s say this webinar is a down payment on explaining just how we’d go about doing things differently to sidestep the long term maintainability traps in many popular prescriptive architectures.
An unheralded, but vital foundational piece of the “Critter Stack” is the Weasel family of libraries that both Marten and Wolverine use quite heavily for a range of database development utilities. For the moment, we have Weasel packages with similar functionality for PostgreSQL and Sql Server.
We’re certainly not opposed to adding other database engines like MySQL or even Oracle, but those two databases were the obvious places to start.
I’m just giving a little bit of an overview of some of the functionality in the Weasel libraries.
Extension Methods for Less Painful ADO.Net
The “Back to the Future” aspect of working so heavily with first Marten, then database centric features in Wolverine has been doing a lot of low level ADO.Net development after years of more or less relying on ORMs. At one point in the late 00’s I had a quote in my blog something to the effect of:
If you’re writing ADO.Net code by hand, you’re stealing from your employer
Me
Even when you need to have finer grained control over SQL generation in your codebase, I think you’re maybe a little better off at least using a micro-ORM like Dapper.
ADO.Net has a very tedious API out of the box, so Weasel alleviates that with quite a few extension methods to make your code a little quicker to write and hopefully much easier to read later as well.
Here’s a sample method from the Sql Server-backed node tracking from the Wolverine codebase that shows off several Weasel utility extension methods:
public async Task RemoveAssignmentAsync(Guid nodeId, Uri agentUri, CancellationToken cancellationToken)
{
await using var conn = new SqlConnection(_settings.ConnectionString);
// CreateCommand is an extension method in Weasel
await conn.CreateCommand($"delete from {_assignmentTable} where id = @id and node_id = @node")
.With("id", agentUri.ToString())
.With("node", nodeId)
// Also an extension method in weasel that opens the connection,
// executes the command, and closes the connection in sequence
.ExecuteOnce(cancellationToken);
}
This isn’t particularly very innovative, and I’ve seen several other one off libraries where folks have done something very similar. I still like having these methods though, and I appreciate these utilities not being copy and pasted between Marten, Weasel, and other work.
Batched Commands
I don’t want to oversimplify things too much, but in the world of enterprise software development the one of the most common sources of poor performance is being too chatty between technical layers as network round trips can be very expensive. I did a lot of experimentation very early on in Marten development, and what we found quite clearly was that there was a massive performance benefit in batching up database commands and even queries to the database.
Weasel has a utility called CommandBuilder (there’s one for Sql Server, one for PostgreSQL, and a third flavor that targets the generic DbCommand abstractions) that we use quite heavily for building batched database queries. Here’s a usage from the PostgreSQL backed node management code in Wolverine:
await using var conn = new NpgsqlConnection(_settings.ConnectionString);
await conn.OpenAsync(cancellationToken);
var builder = new CommandBuilder();
var nodeParameter = builder.AddNamedParameter("node", nodeId, NpgsqlDbType.Uuid);
foreach (var agent in agents)
{
var parameter = builder.AddParameter(agent.ToString());
builder.Append(
$"insert into {_assignmentTable} (id, node_id) values (:{parameter.ParameterName}, :{nodeParameter.ParameterName}) on conflict (id) do update set node_id = :{nodeParameter.ParameterName};");
}
await builder.ExecuteNonQueryAsync(conn, cancellationToken);
await conn.CloseAsync();
Behind the scenes, CommandBuilder is using a StringBuilder to more efficiently append strings for what eventually becomes the data for a DbCommand.CommandText. It’s also helping to build as many database parameters as you need with the pattern “p0, p1, p#” as well as letting you use shared, named parameters.
Database Schema Management
A crucial feature in both Marten and Wolverine is the ability to quietly put your backing database into the proper, configured state that your application requires. This part of Weasel is a little more involved than I have ambition to adequately demonstrate here, but here’s a taste. In Wolverine’s new Sql Server messaging transport, there’s a separate table for each named queue to track scheduled messages that’s configured in code like this:
using Weasel.Core;
using Weasel.SqlServer.Tables;
using Wolverine.RDBMS;
namespace Wolverine.SqlServer.Transport;
internal class ScheduledMessageTable : Table
{
public ScheduledMessageTable(DatabaseSettings settings, string tableName) : base(
new DbObjectName(settings.SchemaName, tableName))
{
AddColumn<Guid>(DatabaseConstants.Id).AsPrimaryKey();
AddColumn(DatabaseConstants.Body, "varbinary(max)").NotNull();
AddColumn(DatabaseConstants.MessageType, "varchar(250)").NotNull();
AddColumn<DateTimeOffset>(DatabaseConstants.ExecutionTime).NotNull();
AddColumn<DateTimeOffset>(DatabaseConstants.KeepUntil);
AddColumn<DateTimeOffset>("timestamp").DefaultValueByExpression("SYSDATETIMEOFFSET()");
// Definitely want to index the execution time. Far more reads than writes. We think.
Indexes.Add(new IndexDefinition($"idx_{tableName}_execution_time")
{
Columns = new string[]{DatabaseConstants.ExecutionTime}
});
}
}
What you see above is the support for database tables in Sql Server. This model helps the critter stack tools be able to make database migrations on the fly, including:
Building missing tables
Creating missing database schemas
Adding additional columns that are part of the configured table model, but not present in the database (Marten uses this quite heavily, and this all originally came out of early Marten)
Removing columns that are in the existing database table, but don’t exist in the configuration
Adding, removing, or modifying indexes to make the database reflect the configured table model (this has been a permutation hell undertaking and a frequent source of bugs over time with Weasel)
The schema management and migration subsystem of Weasel also supports change management of functions, stored procedures, and PostgreSQL sequences or extensions. This model also underpins all of Marten’s database command line management in the Marten.CommandLine package (but all of it is completely available in Weasel.CommandLine as well to support Wolverine).
The command line support adds command line options to your .NET application to:
Generate database schema creation scripts
Create database migration files including rollback scripts by comparing the existing database to the configured database schema objects in your system
Wolverine 1.6.0 came out today, and one of the main themes was a series of improvements to the Azure Service Bus integration with Wolverine. In addition to the basic support Wolverine already had support for messaging with Azure Service Bus queues, topics, and subscriptions, you can now use native scheduled delivery, session identifiers for FIFO delivery, and expanded options for conventional routing topology.
First though, to get started with Azure Service Bus and Wolverine, install the WolverineFx.AzureServiceBus with the Nuget mechanism of your choice:
dotnet add package WolverineFx.AzureServiceBus
Next, you’ll add just a little bit to your Wolverine bootstrapping like this:
using var host = await Host.CreateDefaultBuilder()
.UseWolverine((context, opts) =>
{
// One way or another, you're probably pulling the Azure Service Bus
// connection string out of configuration
var azureServiceBusConnectionString = context
.Configuration
.GetConnectionString("azure-service-bus");
// Connect to the broker in the simplest possible way
opts.UseAzureServiceBus(azureServiceBusConnectionString)
.AutoProvision()
.UseConventionalRouting();
}).StartAsync();
Native Message Scheduling
You can now use native Azure Service Bus scheduled delivery within Wolverine without any explicit configuration beyond what you already do to connect to Azure Service Bus. Putting that into perspective, if you have a message type name ValidateInvoiceIsNotLate that is routed to an Azure Service Bus queue or subscription, you can use this feature:
public async Task SendScheduledMessage(IMessageContext bus, Guid invoiceId)
{
var message = new public async Task SendScheduledMessage(IMessageContext bus, Guid invoiceId)
{
var message = new ValidateInvoiceIsNotLate
{
InvoiceId = invoiceId
};
// Schedule the message to be processed in a certain amount
// of time
await bus.ScheduleAsync(message, 30.Days());
// Schedule the message to be processed at a certain time
await bus.ScheduleAsync(message, DateTimeOffset.Now.AddDays(30));
}
{
InvoiceId = invoiceId
};
// Schedule the message to be processed in a certain amount
// of time
await bus.ScheduleAsync(message, 30.Days());
// Schedule the message to be processed at a certain time
await bus.ScheduleAsync(message, DateTimeOffset.Now.AddDays(30));
}
That would also apply to scheduled retry error handling if the endpoint is also Inline:
using var host = Host.CreateDefaultBuilder()
.UseWolverine(opts =>
{
opts.Policies.OnException<TimeoutException>()
// Just retry the message again on the
// first failure
.RetryOnce()
// On the 2nd failure, put the message back into the
// incoming queue to be retried later
.Then.Requeue()
// On the 3rd failure, retry the message again after a configurable
// cool-off period. This schedules the message
.Then.ScheduleRetry(15.Seconds())
// On the next failure, move the message to the dead letter queue
.Then.MoveToErrorQueue();
}).StartAsync();
Topic & Subscription Conventions
The original conventional routing with Azure Service Bus just sent and listened to queues named after the message type within the application. Wolverine 1.6 adds an additional routing convention to publish outgoing messages to topics and listen for known handled messages with topics and subscriptions. In all cases, you can customize the convention naming and any element of the Wolverine listening, sending, or any of the effected Azure Service Bus topics or subscriptions.
The syntax for this option is shown below:
opts.UseAzureServiceBusTesting()
.UseTopicAndSubscriptionConventionalRouting(convention =>
{
// Optionally control every aspect of the convention and
// its applicability to types
// as well as overriding any listener, sender, topic, or subscription
// options
})
.AutoProvision()
.AutoPurgeOnStartup();
Session Identifiers and FIFO Delivery
You can now take advantage of sessions and first-in, first out queues in Azure Service Bus with Wolverine. To tell Wolverine that an Azure Service Bus queue or subscription should require sessions, you have this syntax shown in an internal test:
_host = await Host.CreateDefaultBuilder()
.UseWolverine(opts =>
{
opts.UseAzureServiceBusTesting()
.AutoProvision().AutoPurgeOnStartup();
opts.ListenToAzureServiceBusQueue("send_and_receive");
opts.PublishMessage<AsbMessage1>().ToAzureServiceBusQueue("send_and_receive");
opts.ListenToAzureServiceBusQueue("fifo1")
// Require session identifiers with this queue
.RequireSessions()
// This controls the Wolverine handling to force it to process
// messages sequentially
.Sequential();
opts.PublishMessage<AsbMessage2>()
.ToAzureServiceBusQueue("fifo1");
opts.PublishMessage<AsbMessage3>().ToAzureServiceBusTopic("asb3");
opts.ListenToAzureServiceBusSubscription("asb3")
.FromTopic("asb3")
// Require sessions on this subscription
.RequireSessions(1)
.ProcessInline();
}).StartAsync();
Wolverine is using the “group-id” nomenclature from the AMPQ standard, but for Azure Service Bus, this is directly mapped to the SessionId property on the Azure Service Bus client internally.
To publish messages to Azure Service Bus with a session id, you will need to of course supply the session id:
// bus is an IMessageBus
await bus.SendAsync(new AsbMessage3("Red"), new DeliveryOptions { GroupId = "2" });
await bus.SendAsync(new AsbMessage3("Green"), new DeliveryOptions { GroupId = "2" });
await bus.SendAsync(new AsbMessage3("Refactor"), new DeliveryOptions { GroupId = "2" });
You can also send messages with session identifiers through cascading messages as shown in a fake message handler below:
public static IEnumerable<object> Handle(IncomingMessage message)
{
yield return new Message1().WithGroupId("one");
yield return new Message2().WithGroupId("one");
yield return new Message3().ScheduleToGroup("one", 5.Minutes());
// Long hand
yield return new Message4().WithDeliveryOptions(new DeliveryOptions
{
GroupId = "one"
});
}
Let’s say your system is already using Sql Server for persistence, you need some durable, asynchronous messaging, and wouldn’t it be nice to not have to introduce any new infrastructure into the mix? Assuming you’ve decided to also use Wolverine, you can get started with this approach by adding the WolverineFx.SqlServer Nuget to your application:
dotnet add package WolverineFx.SqlServer
Here’s a sample application bootstrapping that shows the inclusion and configuration of Sql Server-backed queueing:
using var host = await Host.CreateDefaultBuilder()
.UseWolverine((context, opts) =>
{
var connectionString = context
.Configuration
.GetConnectionString("sqlserver");
// This adds both Sql Server backed
// transactional inbox/outbox support
// and the messaging transport support
opts
.UseSqlServerPersistenceAndTransport(connectionString, "myapp")
// Tell Wolverine to build out all necessary queue or scheduled message
// tables on demand as needed
.AutoProvision()
// Option that may be helpful in testing, but probably bad
// in production!
.AutoPurgeOnStartup();
// Use this extension method to create subscriber rules
opts.PublishAllMessages()
.ToSqlServerQueue("outbound");
// Use this to set up queue listeners
opts.ListenToSqlServerQueue("inbound")
// Optional circuit breaker usage
.CircuitBreaker(cb =>
{
// fine tune the circuit breaker
// policies here
})
// Optionally specify how many messages to
// fetch into the listener at any one time
.MaximumMessagesToReceive(50);
}).StartAsync();
The Sql Server transport is pretty simple, it basically just supports named queues right now. Here’s a couple useful properties of the transport that will hopefully make it more useful to you:
Scheduled message delivery is absolutely supported with the Sql Server Transport, and some care was taken to optimize the database load and throughput when using this feature
Sql Server backed queues can be either “buffered in memory” (Wolverine’s message batching) or be “durable” meaning that the queues are integrated into both the transactional inbox and outbox for durable systems
Wolverine can build database tables as necessary for the queue much like it does today for the transactional inbox and outbox. Moreover, the configured queue tables are also part of the stateful resource model in the Critter Stack world that provide quite a bit of command line management directly into your application.
This feature is something that folks have asked about in the past, but I’ve always been reticent to try because databases don’t make for great, 1st class queueing mechanisms. That being said, I’m working with a JasperFx Software client who wanted a more robust local queueing mechanism that could handle much more throughput for scheduled messaging, and thus, the new Sql Server Transport was born.
There will be a full fledged PostgreSQL backed queue at some point, and it might be a little more robust even based on some preliminary work from a Wolverine contributor, but that’s probably not an immediate priority.
JasperFx Software is up and running, and we’d love to work with you to help make your software development efforts more successful.
I’m one of a number of folks who are actively questioning the conventional wisdom of Hexagonal Architecture approaches. If you’re interested in all the things I think are wrong with the way that enterprise software is built today, you can check out my talk from NDC Oslo this summer (as I suffer through an Austin summer and blissfully remember the feeling of actually wanting a jacket on outside):
That talk was admittedly heavy on all the things I don’t like about long running systems built by aficionados of prescriptive Clean/Onion/Ports & Adapters/iDesign Architecture approaches, and maybe lighter than it should be on “well, what would you do instead?”
To be honest, it’s much easier to be against something and figuring out what exactly I’m for is a work in progress. Before I get into any specifics, I want to say that the only consistent way to arrive at high quality, well performing code that’s easy to maintain is iteration and adaptation. I’m not saying that upfront planning or design can’t help, but it can also be very wrong in the absence of true feedback. Dating back to my old writings in the now defunct CodeBetter website, I thought long ago that there were a couple of “first causes” for successful software development, of which the only two I remember now are:
The paramount importance of rapid and effective feedback mechanisms. That mostly means testing of all sorts, but also having your assumptions about system usage, business logic behavior, and performance qualities confirmed or blown up by feedback from users or real life deployments.
Reversibility. Granted, hardly anybody uses this term and you won’t find much about it, but let’s call it roughly your ability to change technical directions on a software project. Some choices are hard to reverse and have to be made early, and other decisions, not so much.
Back to the idea that iteration and adaptation over time being the most effective way to arrive at good technical results. Your ability to safely iterate is largely tied to the quality and quantity of your feedback cycles. Your ability to actually adapt as you learn more about how your system should behave or to adapt to emergent patterns in the codebase that weren’t obvious at first can be enabled by high reversibility in your system, or hindered by low reversibility.
To break this apart a bit, let’s say we’re all sitting around talking about how to organize and create a codebase that is easy to maintain, pleasant to work in, and generally successful over time. If I were Conan the Barbarian, and you asked me “Conan, what is best in life?”, I would answer with these overarching themes that mostly connect back to the earlier pillars of feedback and reversibility:
Keeping closely related code together – this is really simple in theory, but harder in practice. Reusable code might play by different rules, but by and large, I want closely related code for a single feature or use case to live closely together in the file system. Maybe even in the same file. Code that has to change together or be understood together, should live together. Hexagonal architectures encourage folks to organize code by technical stereotypes and think in terms of horizontal layers. That leads to closely related code being scattered around the codebase. The fallacy of any kind of layered architecture to me is that I very rarely need to reason about a whole technical layer of the system at one time, but very frequently need to reason about all the code. All the chatter the last couple years about Vertical Slice Architecture – is in my opinion – a course correction to the previous decade’s focus on layered architectures.
Effective test automation coverage – I think this should be almost self-explanatory. If my code coverage is good, meaning that it’s relatively comprehensive, runs quickly (enough, and that’s subjective), and reliably tells us whether the system is in a shape where it can be safely shipped, then most technical problems that arise can be solved with our testing safety net. Describing what is and is not a desirable test automation strategy is a long discussion by itself, but let’s oversimplify that to “basically not the typical over-reliance on slow, buggy, brittle Selenium tests.” And no, even though Playwright or Cypress may be better tools in the end, it’s the focus on black box end to end testing through the user interface that I think its the problem more than anything wrong with Selenium itself.
Low ceremony code – If iteration and adaptation is really as valuable as I’m claiming, then it really behooves us to have relatively low code ceremony approaches so we can easily break features apart or introduce new features or even just understand the code we’ve already written without it being obfuscated by lots of boilerplate code. High code ceremony means having a lot of repetitive or manual coding steps that discourage you from changing code after the fact. As a first example, a document database approach like Marten‘s requires a lot less ceremony to introduce new persistent entities or change the structure of existing entities compared to an Object Relational Mapper approach.
Modularity between features – The cruel betrayal of hexagonal architectures is that their promise of making infrastructure easy to upgrade through layering is actually a trap. By organizing code primarily by layer first, you can easily arrive at a place where an entire layer may be tightly coupled to a particular set of tooling or approach — and it’s often just too damn expensive to change an entire layer of a large system at one time. Whether you ultimately choose some sort of micro-service architecture or modular monolith, it’s valuable to have loose coupling between features so that you could upgrade the technology in a system one vertical feature at a time. That’s much more feasible than trying to swap out the entire database at one time. In practice, I would describe this as the “vertical slice architecture”, but also trying to minimize shared infrastructure code and shared abstractions between features as that tends to impede modernization efforts in my experience.
Keeping infrastructure out of business or workflow logic – I think that at least the .NET community I live within (but I suspect in the Java & TypeScript worlds as well) that folks assume that decoupling the business logic decoupled from infrastructure means cutting “mockable” abstractions between the business logic and its calls into infrastructure. Instead, I’d push developers to concentrate on isolating business and workflow logic completely away from any calls infrastructure. That’s a long conversation all by itself, but my recent post on the A-Frame Architecture with Wolverine hopefully explains some of what I mean here.
Technologies that are friendly with integration testing – Hey, some technologies are simply easier to work with for developers than others. Given a choice between technology “A” and technology “B”, I’m going to lean toward whichever is easiest to run locally and whichever is easiest to utilize within integration test harnesses — which generally means, how easy or hard is it really to get the infrastructure into the exact right state for the next test? Corey Kaylor and I’s journey with Marten originally came about because of our strong opinions that document databases had much less friction for local development or integration testing than using a relational database and ORM combination — and 8 years later I feel even more strongly about that advantage.
Optimized “Time to Login Screen” – Consider this, a new developer just started with your team, or maybe you’re picking up work on a codebase that you haven’t worked with in quite awhile. How long does it take from you to go from cloning a fresh copy of the code to successfully running all the tests and the system itself on your local development box? This is also a much longer conversation, but this optimization absolutely impacts how I choose technical infrastructure on projects. It also leads to me prioritizing project automation to improve the development experience because I think that project friction in development and testing absolutely impacts how successful software projects can be.
And now let’s leave the arena of technical choices and dip our toes into just a little bit of mushy people-oriented stuff.
Learning Environment
This has purposely been written from a technical first point of view, but company culture inevitably plays a large part as well. I won’t budge off the idea that adaptation and iteration are crucial, but that’s often impossible if development teams are too tightly micromanaged by product owners, management, or the nebulous “the business.”
For the sake of this post, let’s all pretend that we’re all empowered within our workplaces and we can collectively assert ourselves to improve the technical health of our codebases and basically exert some ownership over our world.
Given my previous point, we should all just work on the assumption that you can and will learn new things after a system is started or even mature that can be later used in that system. Moreover, encourage constant learning through your teams and even encourage folks to challenge the current technical direction or development processes. Don’t assume that the way things are at this moment is the way things have to be in perpetuity.
Like I said before, I’m obviously discussing this outside the context of how empowered or how micro-managed the development team is in real life, so let’s also throw in that a team that is empowered with real ownership over their system will outperform a team that is closely micro-managed inside a rigid management structure of some sort.
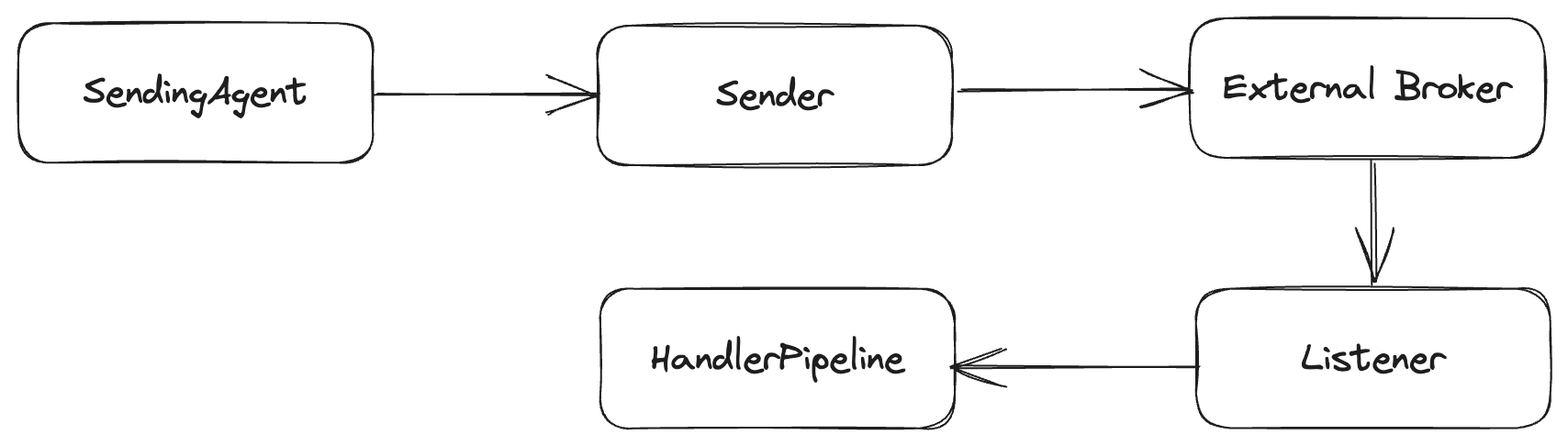
In Wolverine terminology, an “Endpoint” is the configuration time model for any location or mechanism where Wolverine sends or receives messages, including local Wolverine queues within your application. Think of external resource like a Rabbit MQ exchange or an Amazon SQS queue. The Async API specification refers to this as a channel, and Wolverine may very well change its nomenclature in the future to be consistent with Async API. While there are somewhat different configuration options for a Rabbit MQ exchange versus an Azure Service Bus queue, there are some common elements. For the sake of this post (which is mostly ripped out of the Wolverine documentation), endpoints in Wolverine are processed on one of three modes:
Inline – messages are sent immediately, and processed sequentially. While you can parallelize the listeners for better throughput, this is your most likely choice if message delivery order matters to you
Choosing between these three modes is a matter of balancing throughput and delivery guarantees. With that, here’s a deeper dive into the three modes. Do note though, that not every transport type can support all three modes
Inline Endpoints
Wolverine endpoints come in three basic flavors, with the first being Inline endpoints:
// Configuring a Wolverine application to listen to
// an Azure Service Bus queue with the "Inline" mode
opts.ListenToAzureServiceBusQueue(queueName, q => q.Options.AutoDeleteOnIdle = 5.Minutes()).ProcessInline();
With inline endpoints, as the name implies, calling IMessageBus.SendAsync() immediately sends the message to the external message broker. Likewise, messages received from an external message queue are processed inline before Wolverine acknowledges to the message broker that the message is received.
In the absence of a durable inbox/outbox, using inline endpoints is “safer” in terms of guaranteed delivery. As you might think, using inline agents can bottle neck the message processing, but that can be alleviated by opting into parallel listeners.
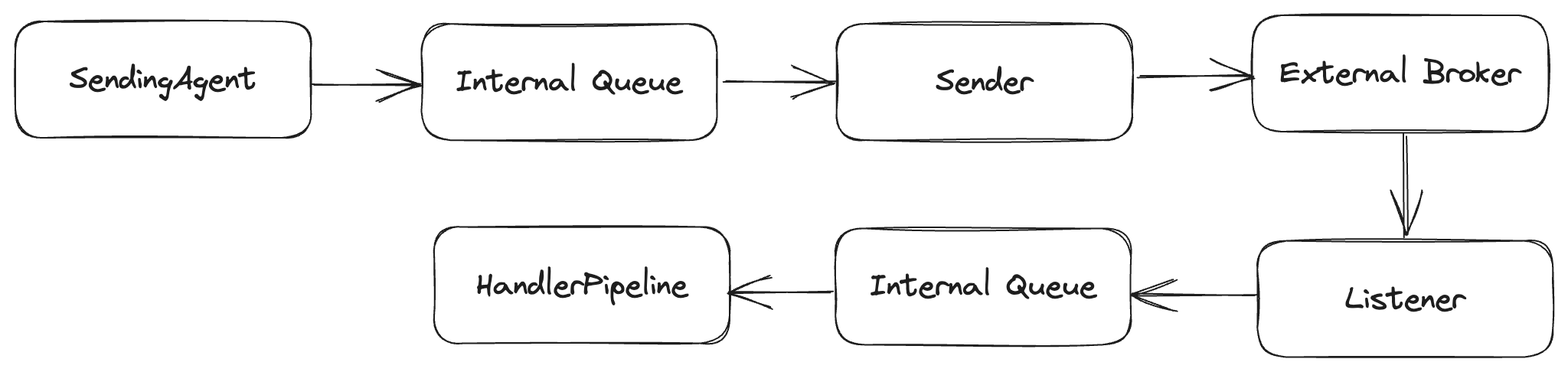
Buffered Endpoints
In the second Buffered option, messages are queued locally between the actual external broker and the Wolverine handlers or senders.
To opt into buffering, you use this syntax:
// I overrode the buffering limits just to show
// that they exist for "back pressure"
opts.ListenToAzureServiceBusQueue("incoming")
.BufferedInMemory(new BufferingLimits(1000, 200));
At runtime, you have a local TPL Dataflow queue between the Wolverine callers and the broker:
On the listening side, buffered endpoints do support back pressure (of sorts) where Wolverine will stop the actual message listener if too many messages are queued in memory to avoid chewing up your application memory. In transports like Amazon SQS that only support batched message sending or receiving, Buffered is the default mode as that facilitates message batching.
Buffered message sending and receiving can lead to higher throughput, and should be considered for cases where messages are ephemeral or expire and throughput is more important than delivery guarantees. The downside is that messages in the in memory queues can be lost in the case of the application shutting down unexpectedly — but Wolverine tries to “drain” the in memory queues on normal application shutdown.
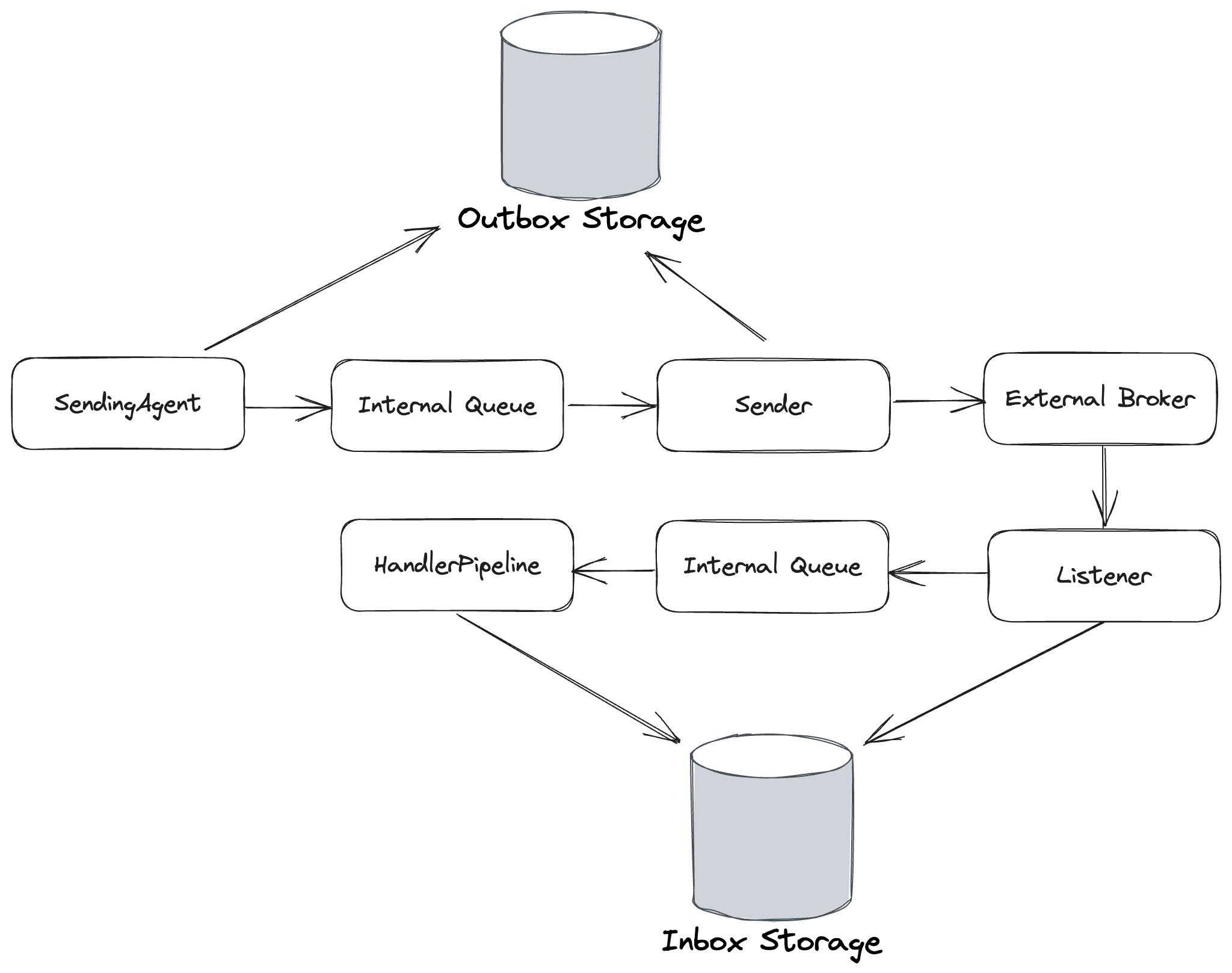
Durable Endpoints
Durable endpoints behave like buffered endpoints, but also use the durable inbox/outbox message storage to create much stronger guarantees about message delivery and processing. You will need to use Durable endpoints in order to truly take advantage of the persistent outbox mechanism in Wolverine. To opt into making an endpoint durable, use this syntax:
// I overrode the buffering limits just to show
// that they exist for "back pressure"
opts.ListenToAzureServiceBusQueue("incoming")
.UseDurableInbox(new BufferingLimits(1000, 200));
opts.PublishAllMessages().ToAzureServiceBusQueue("outgoing")
.UseDurableOutbox();
Or use policies to do this in one fell swoop (which may not be what you actually want, but you could do this!):
As shown below, the Durable endpoint option adds an extra step to the Buffered behavior to add database storage of the incoming and outgoing messages:
Outgoing messages are deleted in the durable outbox upon successful sending acknowledgements from the external broker. Likewise, incoming messages are also deleted from the durable inbox upon successful message execution.
The Durable endpoint option makes Wolverine’s local queueing robust enough to use for cases where you need guaranteed processing of messages, but don’t want to use an external broker.
TL;DR: Wolverine message handler signatures can lead to easier unit testing code than comparable “IHandler of T” frameworks.
Most of the time I think you can just allow Wolverine to handle message routing for you with some simple configured rules or conventions. However, once in awhile you’ll need to override those rules and tell Wolverine exactly where those messages should go.
I’ve been working (playing) with Midjourney quite a bit lately trying to make images for the JasperFx Software website. You can try it out to generate images for free, but the image generation gets a lower priority than their paying customers. Using that as an example, let’s say that we were using Wolverine to build our own Midjourney clone. At some point, there’s maybe an asynchronous message handler like this one that takes a request to generate a new image based on the user’s prompt, but routes the actual work to either a higher or lower priority queue based on whether the user is a premium customer:
public record GenerateImage(string Prompt, Guid ImageId);
public record ImageRequest(string Prompt, string CustomerId);
public record ImageGenerated(Guid Id, byte[] Image);
public class Customer
{
public string Id { get; set; }
public bool PremiumMembership { get; set; }
}
public class ImageSaga : Saga
{
public Guid Id { get; set; }
public string CustomerId { get; set; }
public Task Handle(ImageGenerated generated)
{
// look up the customer, figure out how to send the
// image to their client.
throw new NotImplementedException("Not done yet:)");
MarkCompleted();
}
}
public static class GenerateImageHandler
{
// I'm assuming the usage of Marten middleware here
// to handle transactions and the outbox mechanics
public static async Task HandleAsync(
ImageRequest request,
IDocumentSession session,
IMessageBus messageBus,
CancellationToken cancellationToken)
{
var customer = await session
.LoadAsync<Customer>(request.CustomerId, cancellationToken);
// I'm starting a new saga to track the state of the
// image when we get the callback from the downstream
// image generation service
var imageSaga = new ImageSaga();
session.Insert(imageSaga);
var outgoing = new GenerateImage(request.Prompt, imageSaga.Id);
if (customer.PremiumMembership)
{
// Send the message to a named endpoint we've configured for the faster
// processing
await messageBus.EndpointFor("premium-processing")
.SendAsync(outgoing);
}
else
{
// Send the message to a named endpoint we've configured for slower
// processing
await messageBus.EndpointFor("basic-processing")
.SendAsync(outgoing);
}
}
}
A couple notes on the code above:
I’m assuming the usage of Marten for persistence (of course), with the auto transactional middleware policy applied
I’ve configured a PostgreSQL backed outbox for Wolverine
It’s likely a slow process, so I’m assuming there’s going to be an asynchronous callback from the actual image generator later. I’m leveraging Wolverine’s stateful saga support to track the customer of the original image for processing later
Wolverine V1.3 dropped today with a little improvement for exactly this scenario (based on some usage by a JasperFx client) so you can use cascading messages instead of having to deal directly with the IMessageBus service. Let’s rewrite the explicit code up above, but this time try to turn the actual routing logic into a pure function that could be easy to unit test:
public static class GenerateImageHandler
{
// Using Wolverine's compound handlers to remove all the asynchronous
// junk from the main Handle() method
public static Task<Customer> LoadAsync(
ImageRequest request,
IDocumentSession session,
CancellationToken cancellationToken)
{
return session.LoadAsync<Customer>(request.CustomerId, cancellationToken);
}
public static (RoutedToEndpointMessage<GenerateImage>, ImageSaga) Handle(
ImageRequest request,
Customer customer)
{
// I'm starting a new saga to track the state of the
// image when we get the callback from the downstream
// image generation service
var imageSaga = new ImageSaga
{
// I need to assign the image id in memory
// to make this all work
Id = CombGuidIdGeneration.NewGuid()
};
var outgoing = new GenerateImage(request.Prompt, imageSaga.Id);
var destination = customer.PremiumMembership ? "premium-processing" : "basic-processing";
return (outgoing.ToEndpoint(destination), imageSaga);
}
}
The handler above is the equivalent in functionality to the earlier version. It’s not really that much less code, but I think it’s a bit more declarative. What’s most important to me is the potential for unit testing the decision about where the customer requests go as shown in this fake test:
[Fact]
public void should_send_the_request_to_premium_processing_for_premium_customers()
{
var request = new ImageRequest("a wolverine ice skating in the country side", "alice");
var customer = new Customer
{
Id = "alice",
PremiumMembership = true
};
var (command, image) = GenerateImageHandler.Handle(request, customer);
command.EndpointName.ShouldBe("premium-processing");
command.Message.Prompt.ShouldBe(request.Prompt);
command.Message.ImageId.ShouldBe(image.Id);
image.CustomerId.ShouldBe(request.CustomerId);
}
What I’m hoping you take away from that code sample is that testing the logic part of the ImageRequest message processing turns into a simple state-based test — meaning that you’re just pushing in the known inputs and measuring the values returned by the method. You’d still need to pair this unit test with a full integration test, but at least you’d know that the routing logic is correct before you wrestle with potential integration issues.
As I’d first announced almost *gulp* two months ago, JasperFx Software LLC is officially open for business. In collaboration with the other core Marten team members (Oskar & Babu), we are planning to productize and provide professional services around the “Critter Stack” tools (Marten and Wolverine) that provide a high level of productivity and robustness for server side .NET applications. We’ll soon be able to offer formal support contract agreements for Marten and Wolverine, and we’re already working with early customers on improving these tools.
We’re also happy to help you as consultants for your own software initiatives on whatever technical stack you happen to be using. Maybe you have a legacy system that could use some modernization love, wish your automated testing infrastructure was more successful, want to adopt Test Driven Development but don’t know where to start, or you’re starting a new system and just want help getting it right. If any of that describes where you’re at, JasperFx can help.
I’m weaseling into making a second blog post about a code sample that I mostly stole from just to meet my unofficial goal of 2-3 posts a week promoting the Critter Stack.
using DailyAvailability = System.Collections.Generic.IReadOnlyList<Booking.RoomReservations.GettingRoomTypeAvailability.DailyRoomTypeAvailability>;
namespace Booking.RoomReservations.ReservingRoom;
public record ReserveRoomRequest(
RoomType RoomType,
DateOnly From,
DateOnly To,
string GuestId,
int NumberOfPeople
);
public static class ReserveRoomEndpoint
{
// More on this in a second...
public static async Task<DailyAvailability> LoadAsync(
ReserveRoomRequest request,
IDocumentSession session)
{
// Look up the availability of this room type during the requested period
return (await session.QueryAsync(new GetRoomTypeAvailabilityForPeriod(request))).ToList();
}
[WolverinePost("/api/reservations")]
public static (CreationResponse, StartStream<RoomReservation>) Post(
ReserveRoomRequest command,
DailyAvailability dailyAvailability)
{
// Make sure there is availability for every day
if (dailyAvailability.Any(x => x.AvailableRooms == 0))
{
throw new InvalidOperationException("Not enough available rooms!");
}
var reservationId = CombGuidIdGeneration.NewGuid().ToString();
// I copied this, but I'd probably eliminate the record usage in favor
// of init only properties so you can make the potentially error prone
// mapping easier to troubleshoot in the future
// That folks is the voice of experience talking
var reserved = new RoomReserved(
reservationId,
null,
command.RoomType,
command.From,
command.To,
command.GuestId,
command.NumberOfPeople,
ReservationSource.Api,
DateTimeOffset.UtcNow
);
return (
// This would be the response body, and this also helps Wolverine
// to create OpenAPI metadata for the endpoint
new CreationResponse($"/api/reservations/{reservationId}"),
// This return value is recognized by Wolverine as a "side effect"
// that will be processed as part of a Marten transaction
new StartStream<RoomReservation>(reservationId, reserved)
);
}
}
The original intent of that code sample was to show off how the full “critter stack” (Marten & Wolverine together) enables relatively low ceremony code that also promotes a high degree of testability. And does all of that without requiring developers to invest a lot of time in complicated , prescriptive architectures like a typical Clean Architecture structure.
Specifically today though, I want to zoom in on “testability” and talk about how Wolverine explicitly encourages code that exhibits what Jim Shore famously called the “A Frame Architecture” in its message handlers, but does so with functional decomposition rather than oodles of abstractions and layers.
Using the “A-Frame Architecture”, you roughly want to divide your code into three sets of functionality:
The domain logic for your system, which I would say includes “deciding” what actions to take next.
Infrastructural service providers
Conductor or mediator code that invokes both the infrastructure and domain logic code to decouple the domain logic from infrastructure code
In the message handler above for the `ReserveRoomRequest` command, Wolverine itself is acting as the “glue” around the methods of the HTTP handler code above that keeps the domain logic (the ReserveRoomEndpoint.Post() method that “decides” what event should be captured) and the raw Marten infrastructure to load existing data and persist changes back to the database.
To illustrate that in action, here’s the full generated code that Wolverine compiles to actually handle the full HTTP request (with some explanatory annotations I made by hand):
public class POST_api_reservations : Wolverine.Http.HttpHandler
{
private readonly Wolverine.Http.WolverineHttpOptions _wolverineHttpOptions;
private readonly Marten.ISessionFactory _sessionFactory;
public POST_api_reservations(Wolverine.Http.WolverineHttpOptions wolverineHttpOptions, Marten.ISessionFactory sessionFactory) : base(wolverineHttpOptions)
{
_wolverineHttpOptions = wolverineHttpOptions;
_sessionFactory = sessionFactory;
}
public override async System.Threading.Tasks.Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
await using var documentSession = _sessionFactory.OpenSession();
var (command, jsonContinue) = await ReadJsonAsync<Booking.RoomReservations.ReservingRoom.ReserveRoomRequest>(httpContext);
if (jsonContinue == Wolverine.HandlerContinuation.Stop) return;
// Wolverine has a convention to call methods named
// "LoadAsync()" before the main endpoint method, and
// to pipe data returned from this "Before" method
// to the parameter inputs of the main method
// as that actually makes sense
var dailyRoomTypeAvailabilityIReadOnlyList = await Booking.RoomReservations.ReservingRoom.ReserveRoomEndpoint.LoadAsync(command, documentSession).ConfigureAwait(false);
// Call the "real" HTTP handler method.
// The first value is the HTTP response body
// The second value is a "side effect" that
// will be part of the transaction around this
(var creationResponse, var startStream) = Booking.RoomReservations.ReservingRoom.ReserveRoomEndpoint.Post(command, dailyRoomTypeAvailabilityIReadOnlyList);
// Placed by Wolverine's ISideEffect policy
startStream.Execute(documentSession);
// This little ugly code helps get the correct
// status code for creation for those of you
// who can't be satisfied by using 200 for everything ((Wolverine.Http.IHttpAware)creationResponse).Apply(httpContext);
// Commit any outstanding Marten changes
await documentSession.SaveChangesAsync(httpContext.RequestAborted).ConfigureAwait(false);
// Write the response body as JSON
await WriteJsonAsync(httpContext, creationResponse);
}
}
Wolverine by itself as acting as the mediator between the infrastructure concerns (loading & persisting data) and the business logic function which in Wolverine world becomes a pure function that are typically much easier to unit test than code that has direct coupling to infrastructure concerns — even if that coupling is through abstractions.
Testing wise, if I were actually building a real endpoint like that shown above, I would choose to:
Unit test the Post() method itself by “pushing” inputs to it through the room availability and command data, then assert the expected outcome on the event published through the StartStream<Reservation> value returned by that method. That’s pure state-based testing for the easiest possible unit testing. As an aside, I would claim that this method is an example of the Decider pattern for testable event sourcing business logic code.
I don’t think I’d bother testing the LoadAsync() method by itself, but instead I’d opt to use something like Alba to write an end to end test at the HTTP layer to prove out the entire workflow, but only after the unit tests for the Post() method are all passing.
Responsibility Driven Design
While the “A-Frame Architecture” metaphor is a relatively recent influence upon my design thinking, I’ve long been a proponent of Responsibility Driven Design (RDD) as explained by Rebecca Wirfs-Brock’s excellent A Brief Tour of Responsibility Driven Design. Don’t dismiss that paper because of its age, because the basic concepts and strategies for identifying different responsibilities in your system as a prerequisite for designing or structuring code put forth in that paper are absolutely useful even today.
Applying Responsibility Driven Development to the sample HTTP endpoint code above, I would say that:
The Marten IDocumentSession is a “service provider”
The Wolverine generated code acts as a “coordinator”
The Post() method is responsible for “deciding” what events should be emitted and persisted. One of the most helpful pieces of advice in RDD is to sometimes treat “deciding” to do an action as a separate responsibility from actually carrying out the action. That can lead to better isolating the decision making logic away from infrastructural concerns for easier testing