Wolverine has first class support for delayed or scheduled message delivery. While I don’t think I’d recommend using Wolverine as a one for one replacement for a Hangfire or Quartz.Net, Wolverine’s functionality is great for:
- Scheduling or delaying message retries on failures where you want the message retried, but definitely want that message out of the way of any subsequent messages in a queue
- Enforcing “timeout” conditions for any kind of long running workflow
- Explicit scheduling from within message handlers
Mechanically, you can publish a message with a delayed message delivery with Wolverine’s main IMessageBus entry point with this extension method:
public async Task schedule_send(IMessageContext context, Guid issueId)
{
var timeout = new WarnIfIssueIsStale
{
IssueId = issueId
};
// Process the issue timeout logic 3 days from now
await context.ScheduleAsync(timeout, 3.Days());
// The code above is short hand for this:
await context.PublishAsync(timeout, new DeliveryOptions
{
ScheduleDelay = 3.Days()
});
}
Or using an absolute time with this overload of the same extension method:
public async Task schedule_send_at_5_tomorrow_afternoon(IMessageContext context, Guid issueId)
{
var timeout = new WarnIfIssueIsStale
{
IssueId = issueId
};
var time = DateTime.Today.AddDays(1).AddHours(17);
// Process the issue timeout at 5PM tomorrow
// Do note that Wolverine quietly converts this
// to universal time in storage
await context.ScheduleAsync(timeout, time);
}
Now, Wolverine tries really hard to enable you to use pure functions for as many message handlers as possible, so there’s of course an option to schedule message delivery while still using cascading messages with the DelayedFor() and ScheduledAt() extension methods shown below:
public static IEnumerable<object> Consume(Incoming incoming)
{
// Delay the message delivery by 10 minutes
yield return new Message1().DelayedFor(10.Minutes());
// Schedule the message delivery for a certain time
yield return new Message2().ScheduledAt(new DateTimeOffset(DateTime.Today.AddDays(2)));
}
Lastly, there’s a special base class called TimeoutMessage that your message types can extend to add scheduling logic directly to the message itself for easy usage as a cascaded message. Here’s an example message type:
// This message will always be scheduled to be delivered after
// a one minute delay
public record OrderTimeout(string Id) : TimeoutMessage(1.Minutes());
Which is used within this sample saga implementation:
// This method would be called when a StartOrder message arrives
// to start a new Order
public static (Order, OrderTimeout) Start(StartOrder order, ILogger<Order> logger)
{
logger.LogInformation("Got a new order with id {Id}", order.OrderId);
// creating a timeout message for the saga
return (new Order{Id = order.OrderId}, new OrderTimeout(order.OrderId));
}
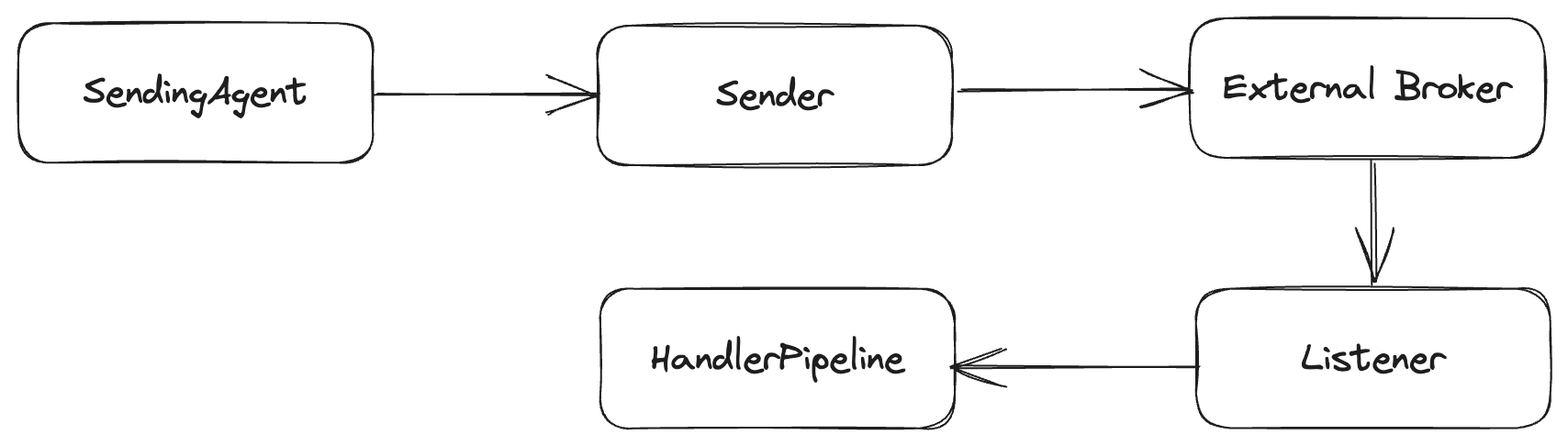
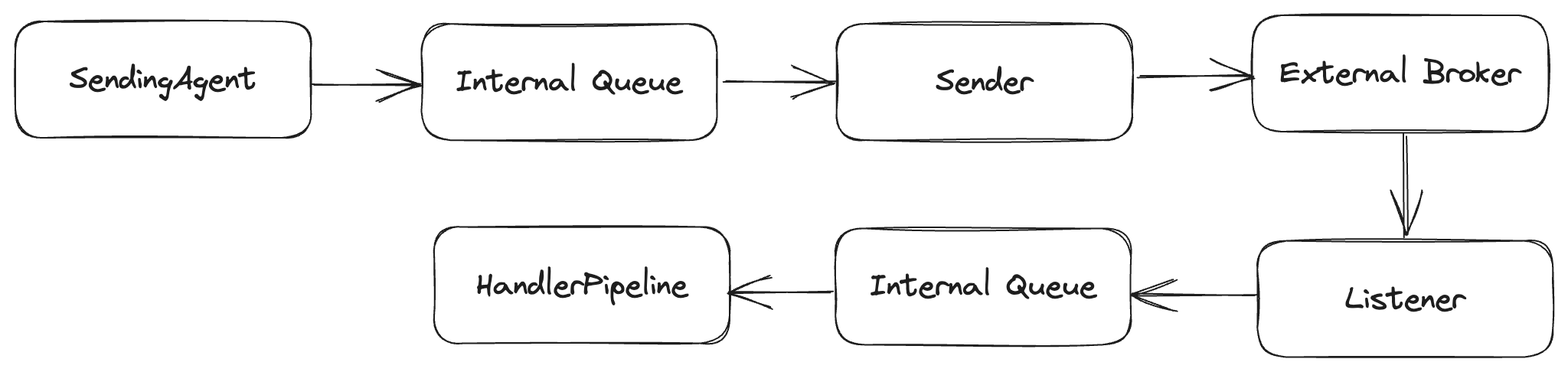
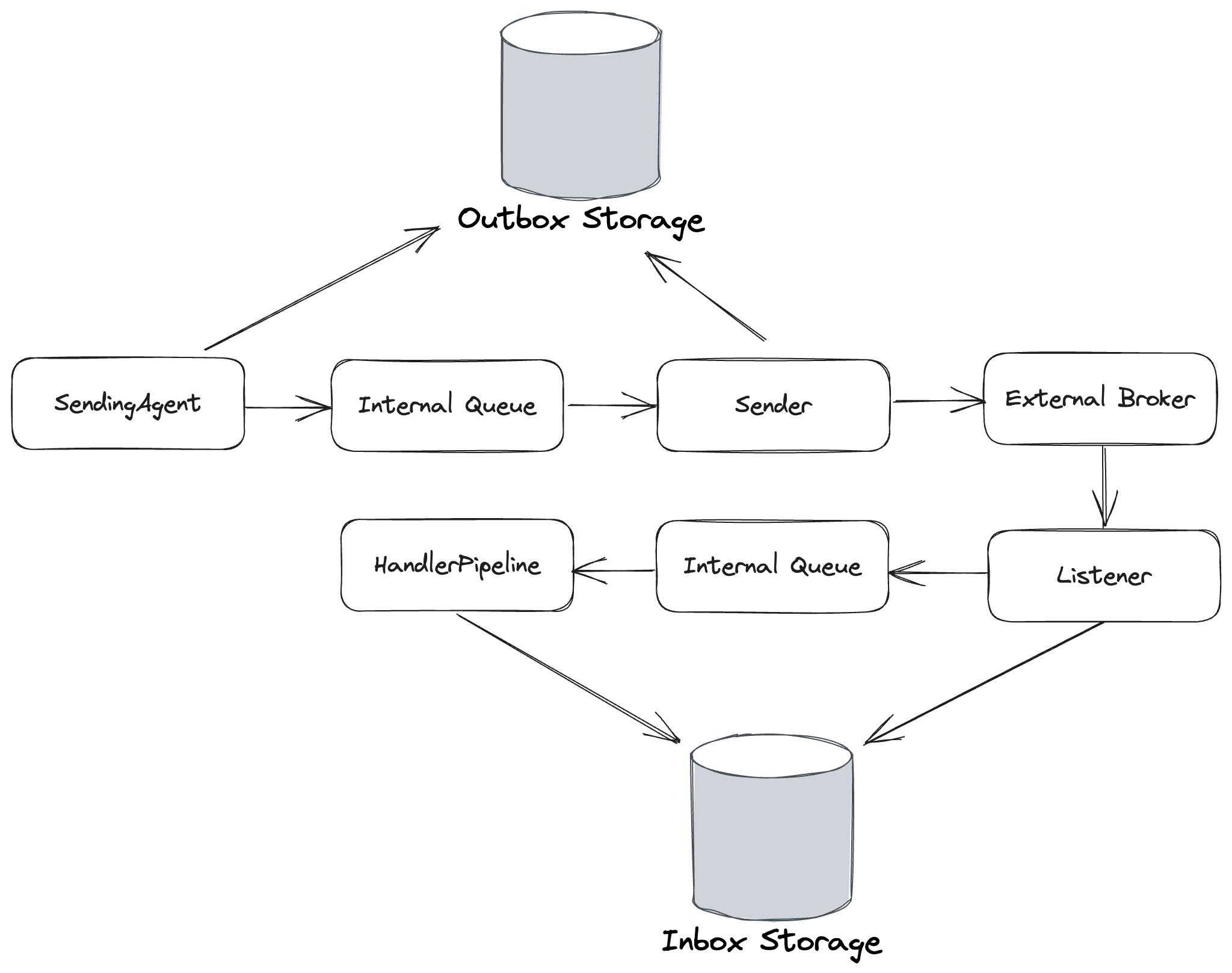
How does it work?
The actual mechanics for how Wolverine is doing the scheduled delivery are determined by the destination endpoint for the message being published. In order of precedence:
- If the destination endpoint has native message delivery capabilities, Wolverine uses that capability. Outbox mechanics still apply to when the outgoing message is released to the external endpoint’s sender. At the time of this post, the only transport with native scheduling support is Wolverine’s Azure Service Bus transport or the recently added Sql Server backed transport.
- If the destination endpoint is durable, meaning that it’s enrolled in Wolverine’s transactional outbox, then Wolverine will store the scheduled messages in the outgoing envelope storage for later execution. In this case, Wolverine is polling for the ready to execute or deliver messages across all running Wolverine nodes. This option is durable in case of process exits.
- In lieu of any other support, Wolverine has an in memory option that can do scheduled delivery or execution