A couple years ago I wrote a long post title My Thoughts on Choosing and Using Persistence Tools about my personal decision tree on how I choose database and persistence tooling if left to my own devices.
This has been a common topic at work lately as our teams need to select persistence or database tooling for various projects in our new “microservice” strategy (i.e., don’t build more stuff into our already too large systems from here on out). As a lazy way of creating blog content, I thought I’d share the “guidance” that my team published a couple months back — even though it’s already been superseded a bit by the facts on the ground.
We’ve since decided to scale back our usage of Postgresql in new projects (for the record, this isn’t because of any purely technical reasons with Postgresql or Marten), but I think we’ve finally got some consensus to at least move away from a single centralized database in favor of application databases and improve our database build and test automation, so that’s a win. As for my recommendations on tooling selection, it looks like I’m having to relent on Entity Framework in our ecosystem due to developer preferences and familiarity.
Databases and Persistence
Most services will need to have some sort of persistent state, and that’s usually going to be in the form of a database. Even before considering which database engine or persistence approach you should take in your microservice, the first piece of advice is to favor application specific databases that are completely owned and only accessed by your microservice.
The pattern of data access between services and databases is reflected by this diagram:
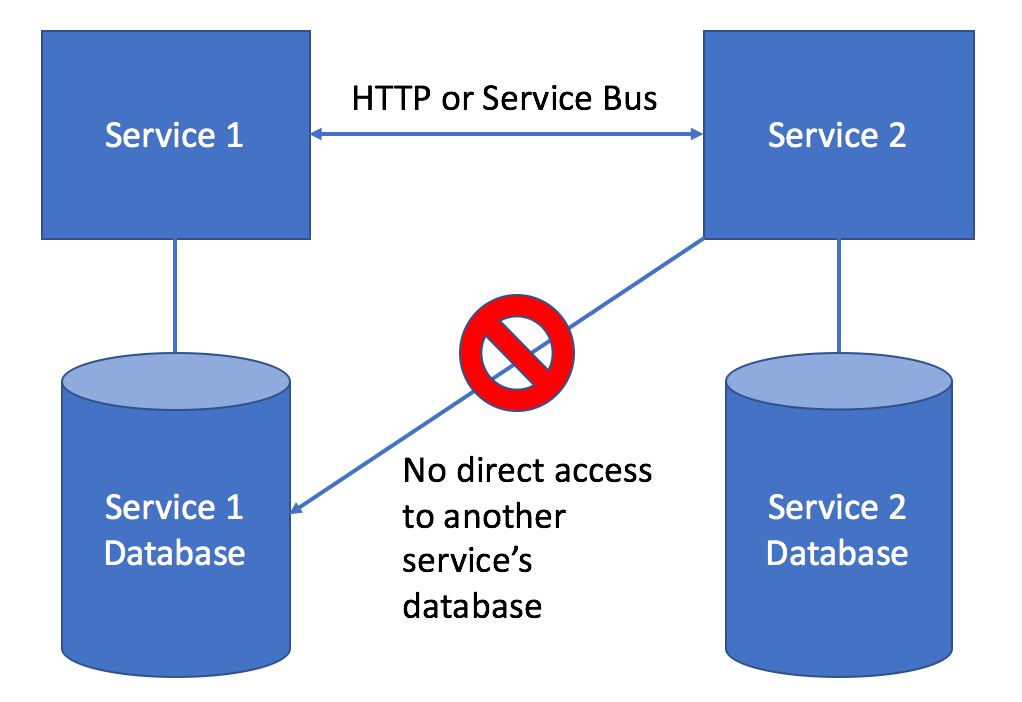
As much as possible, we want to avoid ever sharing a database between applications because of the implicit, tight coupling that creates between two or more services. If your service needs to query information that is owned by another service, favor using either exposing HTTP services from the upstream service or using the request/reply feature of our service bus tools.
Ideally, the application database for a microservice should be:
- An integrated part of the microservice’s continuous integration and deployment pipeline. The microservice database should be built out by the normal build script for your microservice so that brand new developers can quickly be running the service from a fresh clone of the codebase.
- Versioned together with any application code in the same source control repository to establish a strong link between the application code and database schema structure
- Quick to tear down and rebuild from scratch or through incremental migrations
Database and Persistence Tooling Options
The following might be a lie. Like any bigger shop that’s been around for awhile, we’ve got some of everything (NHibernate, raw ADO.net, sproc’s, a forked copy of PetaPoco, etc.)
The two most common approaches in our applications is either:
- Using Dapper as a micro-ORM to access Sql Server
- Using Marten to treat Postgresql as a document database – slowly, but surely replacing our historical usages of RavenDb.
Use Marten if your service data is complex or naturally hierarchical. If any of these things are true about your service’s persisted domain model, we recommend reaching for Marten:
- Your domain model is hierarchical and a single logical entity used within the system would have to be stored across multiple tables in a relational database. Marten effectively bypasses the need to map a domain model to a relational database
- There’s any opportunity to stream JSON data directly from the database to HTTP response streams to avoid the performance hit of using serializers, AutoMapper like tools, or ORM mapping layers
- You expect your domain model to change rapidly in the future
- You opt to use event sourcing to persist some kind of long running workflow
Choose Dapper + Sql Server if:
- Your domain model is going to closely match the underlying database table structure, with simple CRUD-intensive systems being a good example.
- Definitely use a more relational database approach if the application involves reporting functionality – but you can also do that with Marten/Postgresql
- Your service will involve set-based logic that is more easily handled by relational database operations
If it feels like your service doesn’t fit into the decision tree above, opt for Sql Server as that has been our traditional standard.
Other choices may be appropriate on a case by case basis. Raw ADO.Net usage is not recommended from a productivity standpoint. Heavy, full featured ORM’s like Entity Framework or NHibernate are also not recommended by the architecture team. If you feel like EF would be advantageous for your domain model, then Marten might be an alternative with less friction.
The architecture team strongly discourages the usage of stored procedures in most circumstances.
For additional resources and conversation,

Hi Jeremy,
Can you expand a little on why your architecture team advises against full ORMs but for Dapper?
I’ve looked into Dapper (as opposed to EF) a little, but the idea of having inline is a bit scary..
Besides you can use EF “Dapper style” with SqlQuery and .AsNoTracking() while still retaining the full ORM experience for scenarios where manualy tweaking the SQL is not needed (maybe kind of what Marten does in the SQL vs NoSQL).
Best,
Razvan
Just see the links to older blog posts. I’ve talked about that quite a bit in the past.
Sorry, could not find anything concrete. I generally don’t ask for stuff that I can read myself 🙂
All I could find are general statements like : “Dapper if we can, EF if we absolutely have to”, “…I don’t actually have any issue with the current versions of EF… “, “… I have the exact same “meh” attitude toward micro-ORM’s…”
Again : what i wanted to know more was about your preference for Dapper against EF not against all other persistence methods.
Anyway, I understand if you cannot get / want to get into more specifics than that.
Best,
Razvan
It’s just that I think that Dapper is simpler to use in cases where the domain model pretty well reflects the database model. If it’s close to a one to one match, why bother with EF or NH? That’s all.
For NH I can understand – i’ve used it a while back and config is way too verbose even with FluentConfigurations (i think it was called).
Same for EF DB First (not used this one either in quite some time).
But for EF Code First (which is the main “flavor” I use nowadays) i don’t see where the big overhead over Dapper is. Main difference i see is having to always write the SQL in Dapper – but maybe I am missing something from not using it
Anyway, I should just bite the bullet and use Dapper in one project and see what comes out and how it fits me.
You should think about the SQL Server version of the Marten very seriously. You want to be a part of the .NET family which means essentially the Windows family and you don’t want or have an SQL Server support.
@Saeid,
As I’ve told many people many, many times, Marten will support Sql Server when Sql Server catches up on it JSON support. At this point, Sql Server is missing quite a bit of the functionality that Marten utilizes in Postgresql today. It would also help if the .Net community were far more open to non-Microsoft tooling and if you hadn’t noticed, .Net is cross platform now anyway.
Hi Jeremy,
Thanks for the post. Good read.
Could you please elaborate a little on this?
“We’ve since decided to scale back our usage of Postgresql in new projects”.
In order to recommend using Marten within your organization, doesn’t that mean you also recommending Postgresql? Seems like this conflicts with the decision to scale back Postgresql use.
Also, Is your team just more comfortable with SQL Server?
Thanks,
-Douglas
“Is your team just more comfortable with SQL Server?” — exactly that, but I’d say it’s really just the preferences of our centralized database team. Our development teams have been perfectly fine with Postgres. I think we’ve softened that line a little bit even since I wrote this. We’ll probably be much more able to use Postgresql at work when we finally start moving systems to Azure or AWS hosting (knock on wood, hopefully early next year).