
My colleague Mike Schenk had quite a bit of input and contributions to this work. This continues a series of blog posts just trying to build up to the integration of durable messaging with ASP.Net Core:
- Jasper’s Configuration Story
- Jasper’s Extension Model
- Integrating Marten into Jasper Applications
- Durable Messaging in Jasper (this one)
- Integrating Jasper into ASP.Net Core Applications
- Jasper’s HTTP Transport
- Jasper’s “Outbox” Support within ASP.Net Core Applications
Right now (0.5.0), Jasper offers two built in message transports using either raw TCP socket connections or HTTP with custom ASP.Net Core middleware. Either transport can be used in one of two ways:
- “Fire and Forget” — Fast, but not backed by any kind of durable message storage, so there’s no guaranteed delivery.
- “Store and Forward” — Slower, but make damn sure that any message sent is successfully received by the downstream service even in the face of system failures.
Somewhere down the line we’ll support more transport options like RabbitMQ or Azure Service Bus, but for right now, one of the primary design goals of Jasper is to be able to effectively do reliable messaging with the infrastructure you already have. In this case, the “store” part of durable messaging is going to be the primary, backing database of the application. Our proposed architecture at work would then look something like this:
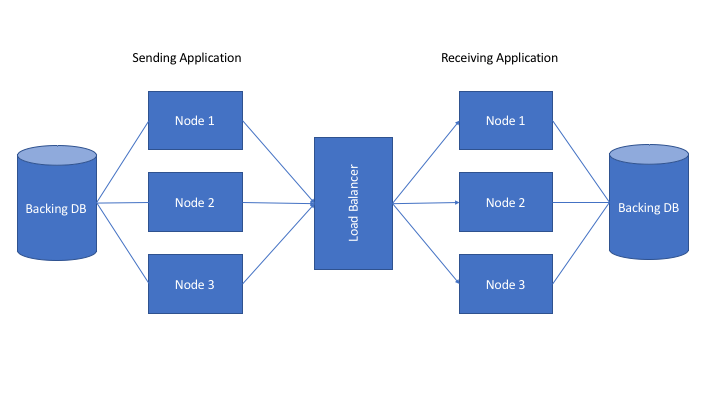
So potentially, we have multiple running instances (“nodes”) of each service behind some kind of load balancer (F5 in our shop), with each service having its own dedicated database.
For the moment, we’ve been concentrating on using Postgresql through Marten to prove out the durable messaging concept inside of Jasper, with Sql Server backing to follow shortly. To opt into that persistence, add the MartenBackedExtension extension from the Jasper.Marten library like this:
public class PostgresBackedApp : JasperRegistry
{
publicPostgresBackedApp()
{
Settings.ConfigureMarten(_ =>
{
_.Connection("some connection string");
});
// Listen for messages durably at port 2301
Transports.DurableListenerAt(2301);
// This opts into Marten/Postgresql backed
// message persistence with the retry and
// message recovery agents
Include<MartenBackedPersistence>();
}
}
What this does is add some new database tables to your Marten configuration and directs Jasper to use Marten to persist incoming and outgoing messages before they are successfully processed or sent. If you end up looking through the code, it uses custom storage operations in Marten for better performance than the out of the box Marten document storage.
Before talking about all the ways that Jasper tries to make the durable messaging as reliable as possible by backstopping error conditions, let’s talk about what actually happens when you publish a message.
What Happens when You Send a Message?
When you send a message through the IServiceBus interface or through cascading messages, Jasper doesn’t just stop and send the actual message. If you’re publishing a message that is routed by a durable channel, calling this code:
public async Task SendPing(IServiceBus bus)
{
// Publish a message
await bus.Send(new PingMessage());
}
will result in an internal workflow shown in this somewhat simplified sequence diagram of the internals:

The very first thing that happens is that each outgoing copy of the message is persisted to the durable storage, which is Postgresql in this post. Next, Jasper batches outgoing messages in a similar way to the debounce operator in Rx by outgoing Uri. If you’re using either the built in TCP or HTTP transports, the next step is to send a batch of messages to the receiving application. The receiving application in turn first persists the incoming messages in its persistence, and sends back an acknowledgement to the original sending application. Once the acknowledgement is received, the sending application will delete the outgoing messages just sent successfully from its message persistence and go on its merry way.
That’s the “store and forward” happy path. Now let’s talk about all the myriad ways things could go wrong and what Jasper tries to do to ensure that your messages get to where they are supposed to go.
Network Hiccups
How’s that for a scientific term? Sending message batches will occasionally fail due to the normal litany of temporary network issues. If an outgoing message batch fails, all the messages get their “sent attempts” count incremented in storage and they are added back into the local, outgoing sending agent queue to be tried again.
Circuit Breaker
Jasper’s sending agents implement a form of the Circuit Breaker pattern where a certain number of consecutive failures (it’s configurable) to send a message batch to any destination will cause Jasper to latch that sending agent. When the sending agent is latched, Jasper will not make any attempts to send messages to that destination. Instead, all outgoing messages to that destination will simply be persisted to the backing message persistence without any node ownership. The key point here is that Jasper won’t keep trying to send messages just to get runtime exceptions and it won’t allow the memory usage of your system to blow up from all the backed up, outgoing messages being in an in memory sending queue.
When the destination is known to be in a failure condition, Jasper will continue to poll the destination with a lightweight ping message just to ascertain if the destination is back up yet. When a successful ping is acknowledged by the destination, Jasper will unlatch the sending agent and begin sending outgoing messages.
Resiliency and Node Failover
If you are using the Marten/Postgresql backed message persistence, your application has a constantly running message persistence agent (it’s actually called SchedulingAgent) that is polling for persisted messages that are either owned by no specific node or persisted messages that are owned by an inactive node.
To detect whether a node is active, we rely on each node holding a session level advisory lock in the underlying Postgresql database as long as it’s really active. Periodically, Jasper will run a query to move any messages owned by an inactive node to “any node” ownership where any running node can recover both the outgoing and incoming messages. This query detects inactive nodes simply by the absence of an active advisory lock for the node identity in the database.
The message persistence agent also polls for the existence of any persisted incoming or outgoing messages that are not owned by any node. If it detects either, it will assign some of these messages to itself and pull outgoing messages into its local sending queues and incoming messages into its local worker queues to be processed. The message polling and fetching was designed to try to enable the recovery work to be spread across the running nodes. This process also uses Postgresql advisory locks as a distributed lock to prevent multiple running nodes from double dipping into the same persisted messages.
The end result of all that verbiage is:
- If the receiving application is completely down, Jasper will be able to recover the outgoing messages and send them later when the receiving application is back up
- If a node fails before it can send or process all the messages in flight, another node will be able to recover those persisted messages and process them
- If your entire application goes down or is shut down, it will pick up the outstanding, persisted work of incoming and outgoing messages when any node is restarted
- By using the advisory locks in the backing database, we got around having to have any kind of distributed lock mechanism (we were considering Consul) or leader election for the message recovery process, making our architecture here a lot simpler than it could have been otherwise.
More Work for the Future
The single biggest thing Jasper needs is early adopters and usage in real applications to know how what it already has for resiliency is working out. Beyond that though, I know we want at least a little more work in the built in transports for:
- Backpressure — We might need some kind of mechanism to allow the receiving applications let the senders know, “hey, I’m super busy here, could you stop sending me so many messages for a little bit” and slow down the sending.
- Work Stealing — We might say that its easier to implement back pressure between the listening agent and worker queues within the receiving application. In that case, if the listener sees there are too many outstanding messages waiting to be processed in the local worker queues, it would just persist the incoming messages for any other node to pick up when it can. We think this might be a cheap way to implement some form of work stealing.
- Diagnostics — We actually do have a working diagnostic package that adds a small website application to expose information about the running application. It could definitely use some additional work to expose metrics on the active message persistence.
- Sql Server backed message persistence — probably the next thing we need with Jasper at work
Other Related Stuff I Didn’t Get Into
- We do have a dead letter queue mechanism where messages that just can’t be processed are shoved over to the side in the message persistence. All configurable of course
- All the message recovery and batching thresholds are configurable. If you’re an advanced Jasper user, you could use those knobs to fine tune batch sizes and failure thresholds
- It is possible to tell Jasper that a message expires at a certain time to prevent sending messages that are just too old

5 thoughts on “Durable Messaging in Jasper”