
Yesterday I started a new series of blog posts about Wolverine capabilities with:
To review, I was describing a project I worked on years ago that involved some interactions with a very unreliable 3rd party web service system to handle payments originating from a flat file:
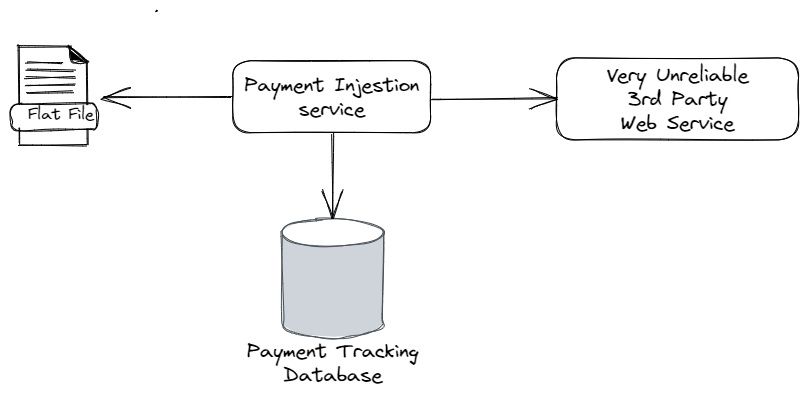
Just based on that diagram above, and admittedly some bad experiences in the shake down cruise of the historical system that diagram was based on, here’s some of the things that can go wrong:
- The system blows up and dies while the payments from a particular file are only half way processed
- Transient errors from database connectivity. Network hiccups
- File IO errors from reading the flat files (I tend to treat direct file system access a lot like a poisonous snake due to very bad experiences early in my career)
- HTTP errors from timeouts calling the web service
- The 3rd party system is under distress and performing very poorly, such that a high percentage of requests are timing out
- The 3rd party system can be misconfigured after code migrations on its system so that it’s technically “up” and responsive, but nothing actually works
- The 3rd party system is completely down
Man, it’s a scary world sometimes!
Let’s say right now that our goal is as much as possible to have a system that is:
- Able to recover from errors without losing any ongoing work
- Doesn’t allow the system to permanently get into an inconsistent state — i.e. a file is marked as completely read, but somehow some of the payments from that file got lost along the way
- Rarely needs manual intervention from production support to recover work or restart work
- Heavens forbid, when something does happen that the system can’t recover from, it notifies production support
Now let’s go onto how to utilize Wolverine features to satisfy those goals in the face of all the potential problems I identified.
What if the system dies halfway through a file?
If you read through the last post, I used the local queueing mechanism in Wolverine to effectively create a producer/consumer workflow. Great! But what if the current process manages to die before all the ongoing work is completed? That’s where the durable inbox support in Wolverine comes in.
Pulling Marten in as our persistence strategy (but EF Core with either Postgresql or Sql Server is fully supported for this use case as well), I’m going to set up the application to opt into durable inbox mechanics for all locally queued messages like so (after adding the WolverineFx.Marten Nuget):
using Marten;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Oakton;
using Wolverine;
using Wolverine.Marten;
using WolverineIngestionService;
return await Host.CreateDefaultBuilder()
.UseWolverine((context, opts) =>
{
// There'd obviously be a LOT more set up and service registrations
// to be a real application
var connectionString = context.Configuration.GetConnectionString("marten");
opts.Services
.AddMarten(connectionString)
.IntegrateWithWolverine();
// I want all local queues in the application to be durable
opts.Policies.UseDurableLocalQueues();
opts.LocalQueueFor<PaymentValidated>().Sequential();
opts.LocalQueueFor<PostPaymentSchedule>().Sequential();
}).RunOaktonCommands(args);
And with those changes, all in flight messages in the local queues are also stored durably in the backing database. If the application process happens to fail in flight, the persisted messages will fail over to either another running node or be picked up by restarting the system process.
So far, so good? Onward…
Getting Over transient hiccups
Sometimes database interactions will fail with transient errors and will very well succeed if retried later. This is especially common when the database is under stress. Wolverine’s error handling policies easily accommodate that, and in this case I’m going to add some retry capabilities for basic database exceptions like so:
// Retry on basic database exceptions with some cooldown time in
// between retries
opts
.Policies
.OnException<NpgsqlException>()
.Or<MartenCommandException>()
.RetryWithCooldown(100.Milliseconds(), 250.Milliseconds(), 500.Milliseconds());
opts
.OnException<TimeoutException>()
.RetryWithCooldown(250.Milliseconds(), 500.Milliseconds());
Notice how I’ve specified some “cooldown” times for subsequent failures. This is more or less an example of exponential back off error handling that’s meant to effectively throttle a distressed subsystem to allow it to catch up and recover.
Now though, not every exception implies that the message may magically succeed at a later time, so in that case…
Walk away from bad apples
Over time we can recognize exceptions that pretty well mean that the message can never succeed. In that case we should just throw out the message instead of allowing it to suck down resources by being retried multiple times. Wolverine happily supports that as well. Let’s say that payment messages can never work if it refers to an account that cannot be found, so let’s do this:
// Just get out of there if the account referenced by a message
// does not exist!
opts
.OnException<UnknownAccountException>()
.Discard();
I should also note that Wolverine is writing to your application log when this happens.
Circuit Breakers to give the 3rd party system a timeout
As I’ve repeatedly said in this blog series so far, the “very unreliable 3rd party system” was somewhat less than reliable. What we found in practice was that the service would fail in bunches when it fell behind, but could recover over time. However, what would happen — even with the exponential back off policy — was that when the system was distressed it still couldn’t recover in time and continuing to pound it with retries just led to everything ending up in dead letter queues where it eventually required manual intervention to recover. That was exhausting and led to much teeth gnashing (and fingers pointed at me in angry meetings). In response to that, Wolverine comes with circuit breaker support as shown below:
// These are the queues that handle calls to the 3rd party web service
opts.LocalQueueFor<PaymentValidated>()
.Sequential()
// Add the circuit breaker
.CircuitBreaker(cb =>
{
// If the conditions are met to stop processing messages,
// Wolverine will attempt to restart in 5 minutes
cb.PauseTime = 5.Minutes();
// Stop listening if there are more than 20% failures
// over the tracking period
cb.FailurePercentageThreshold = 20;
// Consider the failures over the past minute
cb.TrackingPeriod = 1.Minutes();
// Get specific about what exceptions should
// be considered as part of the circuit breaker
// criteria
cb.Include<TimeoutException>();
// This is our fault, so don't shut off the listener
// when this happens
cb.Exclude<InvalidRequestException>();
});
opts.LocalQueueFor<PostPaymentSchedule>()
.Sequential()
// Or the defaults might be just fine
.CircuitBreaker();
With the set up above, if Wolverine detects too high a rate of message failures in a given time, it will completely stop message processing for that particular local queue. Since we’ve isolated the message processing for the two types of calls to the 3rd party web service, we’re allowing everything else to continue when the circuit breaker stops message processing. Do note that the circuit breaker functionality will try to restart message processing later after the designated pause time. Hopefully the pause time allows for the 3rd party system to recover — or for production support to make it recover. All of this without making all the backed up messages continuously fail and end up landing in the dead letter queues where it will take manual intervention to recover the work in progress.
Hold the line, the 3rd party system is broken!
On top of every thing else, the “very unreliable 3rd party system” was easily misconfigured at the drop of a hat such that it would become completely nonfunctional even though it appeared to be responsive. When this happened, every single message to that service would fail. So again, instead of letting all our pending work end up in the dead letter queue, let’s instead completely pause all message handling on the current local queue (wherever the error happened) if we can tell from the exception that the 3rd party system is nonfunctional like so:
// If we encounter this specific exception with this particular error code,
// it means that the 3rd party system is 100% nonfunctional even though it appears
// to be up, so let's pause all processing for 10 minutes
opts.OnException<ThirdPartyOperationException>(e => e.ErrorCode == 235)
.Requeue().AndPauseProcessing(10.Minutes());
Summary and next time!
It’s helpful to assign work within message handlers in such a way to maximize your error handling. Think hard about what actions in your system are prone to failure and may deserve to be their own individual message handler and messaging endpoint to allow for exact error handling policies like the way I used a circuit breaker on the queues that handled calls to the unreliable 3rd party service.
For my next post in this series, I think I want to make a diversion into integration testing using a stand in stub for the 3rd party service using the application setup with Lamar.




