
JasperFx Software works with our customers to help wring the absolute best results out of our customer’s usage of the “Critter Stack.” We build several improvements in collaboration with our customers last year to both Marten and Wolverine specifically to improve scalability of large systems using Event Sourcing. If you’re concerned about whether or not your approach to Event Sourcing will actually scale, definitely look at the Critter Stack, and give JasperFx a shout for help making it all work.
Alright, you’re using Event Sourcing with the whole Critter Stack, and you want to get the best scalability possible in the face of an expected onslaught of incoming events. There’s some “opt in” features in Marten especially that you can take advantage of to get your system going a little bit faster and handle bigger databases.
Using the near ubiquitous “Incident Service” example originally built by Oskar Dudycz, the “Critter Stack” community is building out a new version in the Wolverine codebase that when (and if) finished, will hopefully show off an end to end example of using an event sourced workflow.
In this application we’ll need to track common events for the workflow of a customer reported Incident like when it’s logged, categorised, collects notes, and hopefully gets closed. Coming into this, we think it’s going to get very heavy usage so we expect to have tons of events streaming into the database. We’ve also been told by our business partners that we only need to retain closed incidents in the active views of the user interface for a certain amount of time — but we never want to lose data permanently.
All that being said, let’s look at a few options we can enable in Marten right off the bat:
builder.Services.AddMarten(opts =>
{
var connectionString = builder.Configuration.GetConnectionString("Marten");
opts.Connection(connectionString);
opts.DatabaseSchemaName = "incidents";
// We're going to refer to this one soon
opts.Projections.Snapshot<Incident>(SnapshotLifecycle.Inline);
// Use PostgreSQL partitioning for hot/cold event storage
opts.Events.UseArchivedStreamPartitioning = true;
// Recent optimization that will specifically make command processing
// with the Wolverine "aggregate handler workflow" a bit more efficient
opts.Projections.UseIdentityMapForAggregates = true;
// This is big, use this by default with all new development
// Long story
opts.Events.AppendMode = EventAppendMode.Quick;
})
// Another performance optimization if you're starting from
// scratch
.UseLightweightSessions()
// Run projections in the background
.AddAsyncDaemon(DaemonMode.HotCold)
// This adds configuration with Wolverine's transactional outbox and
// Marten middleware support to Wolverine
.IntegrateWithWolverine();
There are three options here I want to bring to your attention:
UseLightweightSessions()directs Marten to useIDocumentSessionsessions by default (what’s injected by your DI container) to avoid any performance overhead from identity map tracking in the session. Don’t use this of course if you really do want or need the identity map tracking.opts.Events.UseArchivedStreamPartitioning = truesets us up for Marten’s “hot/cold” event storage scheme using PostgreSQL native partitioning. More on this in the section on stream archiving below. Read more about this feature in the Marten documentation.- Setting
UseIdentityMapForAggregates = trueopts into some recent performance optimizations for updatingInlineaggregates through Marten’s FetchForWriting API. More detail on this here. Long story short, this makes Marten and Wolverine do less work and make fewer database round trips to support the aggregate handler workflow I’m going to demonstrate below. Events.AppendMode = EventAppendMode.Quickmakes the event appending operations upon saving a Marten session a lot faster, like 50% faster in our testing. It also makes Marten’s “async daemon” feature work smoothly. The downside is that you lose access to some event metadata duringInlineprojections — which most people won’t care about, but again, we try not to break existing users.
The “Aggregate Handler Workflow”
I have typically described this as Wolverine’s version of the Decider Pattern, but no, I’m now saying that this is a significantly different approach that I believe will lead to better results in larger systems than the “Decider” in that it manages complexity better and handles several technical details that the “Decider” pattern does not. Plus you won’t end up with the humongous switch statements with the Wolverine “Aggregate Handler Workflow” that a Decider function can easily become with any level of domain complexity.
Using Wolverine’s aggregate handler workflow, a command handler that may result in a new event being appended to Marten will look like this one for categorizing an incident:
public static class CategoriseIncidentEndpoint
{
// This is Wolverine's form of "Railway Programming"
// Wolverine will execute this before the main endpoint,
// and stop all processing if the ProblemDetails is *not*
// "NoProblems"
public static ProblemDetails Validate(Incident incident)
{
return incident.Status == IncidentStatus.Closed
? new ProblemDetails { Detail = "Incident is already closed" }
// All good, keep going!
: WolverineContinue.NoProblems;
}
// This tells Wolverine that the first "return value" is NOT the response
// body
[EmptyResponse]
[WolverinePost("/api/incidents/{incidentId:guid}/category")]
public static IncidentCategorised Post(
// the actual command
CategoriseIncident command,
// Wolverine is generating code to look up the Incident aggregate
// data for the event stream with this id
[Aggregate("incidentId")] Incident incident)
{
// This is a simple case where we're just appending a single event to
// the stream.
return new IncidentCategorised(incident.Id, command.Category, command.CategorisedBy);
}
}
The UseIdentityMapForAggregates = true flag optimizes the code above by allowing Marten to use the exact same Incident aggregate object that was originally passed into the Post() method above as the starting basis for updating the Incident data stored in the database. The application of the Inline projection to update the Incident will start with our originally fetched value, apply any new events on top of that, and update the Incident in the same transaction as the events being captured. Without that flag, Marten would have to fetch the Incident starting data from the database all over again when it applies the projection updates while committing the Marten unit of work containing the events.
There’s plenty of rocket science and sophisticated techniques to improving performance, but one simple thing that almost always works out is not repetitively fetching the exact same data from the database if you don’t have to — and that’s the point of the UseIdentityMapForAggregates optimization.
Hot/Cold Storage
Here’s an exciting, relatively new feature in Marten that was planned for years before JasperFx was able to build this for a client late last year. The UseArchivedStreamPartitioning flag sets up your Marten database for “hot / code storage”:
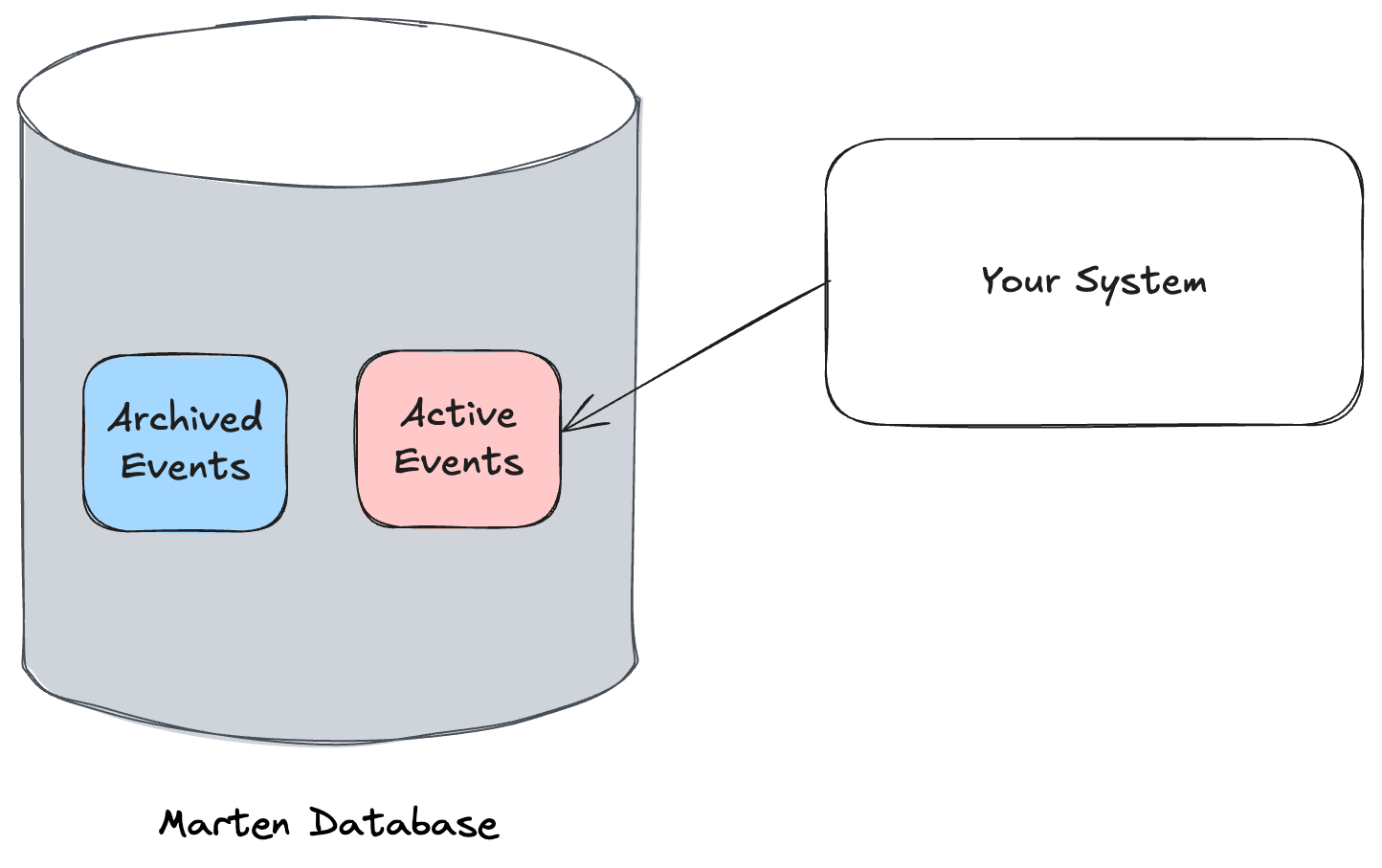
Again, it might require some brain surgery to really improve performance sometimes, but an absolute no-brainer that’s frequently helpful is to just keep your transactional database tables as small and sprightly as possible over time by moving out obsolete or archived data — and that’s exactly what we’re going to do here.
When an Incident event stream is closed, we want to keep that Incident data shown in the user interface for 3 days, then we’d like all the data for that Incident to get archived. Here’s the sample command handler for the CloseIncident command:
public record CloseIncident(
Guid ClosedBy,
int Version
);
public static class CloseIncidentEndpoint
{
[WolverinePost("/api/incidents/close/{id}")]
public static (UpdatedAggregate, Events, OutgoingMessages) Handle(
CloseIncident command,
[Aggregate]
Incident incident)
{
/* More logic for later
if (current.Status is not IncidentStatus.ResolutionAcknowledgedByCustomer)
throw new InvalidOperationException("Only incident with acknowledged resolution can be closed");
if (current.HasOutstandingResponseToCustomer)
throw new InvalidOperationException("Cannot close incident that has outstanding responses to customer");
*/
if (incident.Status == IncidentStatus.Closed)
{
return (new UpdatedAggregate(), [], []);
}
return (
// Returning the latest view of
// the Incident as the actual response body
new UpdatedAggregate(),
// New event to be appended to the Incident stream
[new IncidentClosed(command.ClosedBy)],
// Getting fancy here, telling Wolverine to schedule a
// command message for three days from now
[new ArchiveIncident(incident.Id).DelayedFor(3.Days())]);
}
}
The ArchiveIncident message is being published by this handler using Wolverine’s scheduled message capability so that it will be executed in exactly 3 days time from the current time (you could get fancier and set an exact time to end of business on that day if you wanted).
Note that even when doing the message scheduling, we can still use Wolverine’s cascading message feature. The point of doing this is to keep our handler a pure function that doesn’t have to invoke services, create side effects, or do anything that would force us into asynchronous methods and all of the inherent complexity and noise that inevitably causes.
The ArchiveIncident command handler might just be this:
public record ArchiveIncident(Guid IncidentId);
public static class ArchiveIncidentHandler
{
// Just going to code this one pretty crudely
// I'm assuming that we have "auto-transactions"
// turned on in Wolverine so we don't have to much
// with the asynchronous IDocumentSession.SaveChangesAsync()
public static void Handle(ArchiveIncident command, IDocumentSession session)
{
session.Events.Append(command.IncidentId, new Archived("It'd done baby!"));
session.Delete<Incident>(command.IncidentId);
}
}
When that command executes in three days time, it will delete the projected Incident document from the database and mark the event stream as archived, which will cause PostgreSQL to move that data into the “cold” archived storage.
To close the loop, all normal database operations in Marten specifically filter out archived data with a SQL filter so that they will always be querying directly against the much smaller “active” partition table.
To sum this up, if you use the event archival partitioning and are able to be aggressive about archiving event streams, you can hugely improve the performance of your event sourced application even after you’ve captured a huge number of events because the actual table that Marten is reading and writing from will be relatively stable in side.
As the late, great Stuart Scott would have told us, that’s cooler than the other side of the pillow!
Why aren’t these all defaults?!?
It’s an imperfect world. Every one of the three flags I showed here either subtly change underlying behavior or force additive changes to your application database. The UseIdentityMapForAggregates flag has to be an “opt in” because using that will absolutely give unexpected results for Marten users who mutate the projected aggregate inside of their command handlers (basically anyone doing any type of AggregateRoot base class approach).
Likewise, Marten was originally built using a session with the somewhat more expensive identity map mechanics built in to mimic the commercial tool we were originally trying to replace. I’ve always regretted this decision, but once this has escaped into real systems, changing the underlying behavior absolutely breaks some existing code.
Lastly, introducing the hot/cold partitioning of the event & stream tables to an existing database will cause an expensive database migration, and we certainly don’t want to be inflicting that on unsuspecting users doing an upgrade.
It’s a lot of overhead and compromise, but we’ve chosen to maintain backward compatibility for existing users over enabling out of the box performance improvements.
But wait, there’s more!
Marten has been able to grow quite a bit in capability after I started JasperFx Software as a company to support it. Doing that has allowed us to partner with shops pushing the limits on Marten and Wolverine, and the feedback, collaboration, and yes, compensation has allowed us to push the Critter Stack’s capabilities a lot in the last 18 months.
Sometime in the current quarter, we’re also going to be building and releasing a new “Stream Compacting” feature as another way to deal with archiving data from very long event streams. And yes, a lot of the Event Sourcing community will lecture you about how you should “keep your streams” short, and while there may be some truth to that, that advice is partially around using less capable technical event sourcing solutions. We strive to make Marten & Wolverine more robust so you don’t have to be omniscient and perfect in your upfront modeling.







