The feature set shown in this post was built earlier this year at the behest of a JasperFx Software client who has some unusually high data throughput and wanted to have some significant ability to scale up Marten and Wolverine‘s ability to handle a huge number of incoming events. We originally put this into what was meant to be a paid add on product, but after consultation with the rest of the Critter Stack core team and other big users, we’ve decided that it would be best for this functionality to be in the OSS core of Wolverine.
JasperFx Software is currently working with a client who has a system with around 75 million events in their database and the expectation that that database could double soon. At the same time, they need to be running around 15-20 different event projections continuously running asynchronously to build read side views. To put it mildly, they’re going to want some serious ability for Marten (with a possible helping hand from Wolverine) to handle that data in a performant manner.
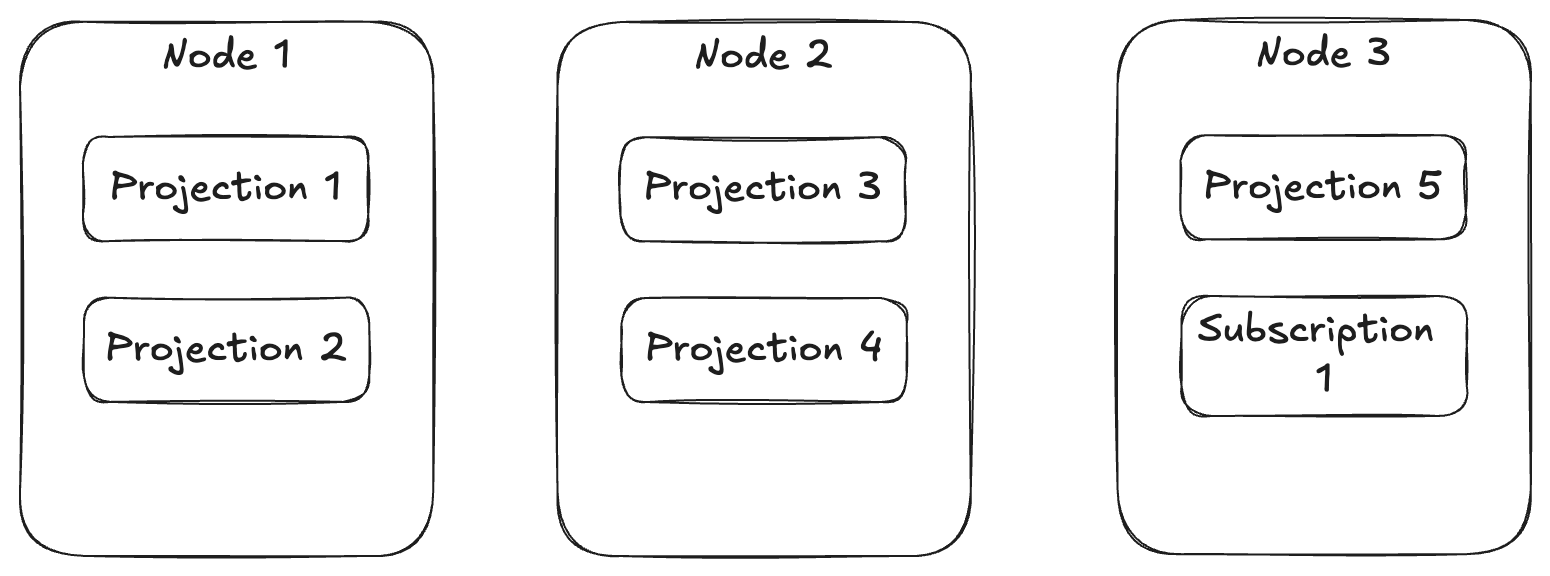
Before Marten 7.0, Marten could only run projections with a “hot/cold” ownership mode that resulted in every possible projection running on a single application node within the cluster. So, not that awesome for scalability to say the least. With 7.0, Marten can do some load distribution of different projections, but it’s not terribly predictable and has no guarantee of spreading the load out.
opts.Services.AddMarten(m =>
{
m.DisableNpgsqlLogging = true;
m.Connection(Servers.PostgresConnectionString);
m.DatabaseSchemaName = "csp";
// This was taken from Wolverine test code
// Imagine there being far more projections and
// subscriptions
m.Projections.Add<TripProjection>(ProjectionLifecycle.Async);
m.Projections.Add<DayProjection>(ProjectionLifecycle.Async);
m.Projections.Add<DistanceProjection>(ProjectionLifecycle.Async);
})
.IntegrateWithWolverine(m =>
{
// This makes Wolverine distribute the registered projections
// and event subscriptions evenly across a running application
// cluster
m.UseWolverineManagedEventSubscriptionDistribution = true;
});
Using the UseWolverineManagedEventSubscriptionDistribution() option in place of Marten’s own async daemon management will give you a load distribution more like this:
Using this model, Wolverine can spread the asynchronous load to more running nodes so you can hopefully get a lot more throughput in your asynchronous projections without overloading any one node.
With this option, Wolverine is going to ensure that every single known asynchronous event projection and every event subscription is running on exactly one running node within your application cluster. Moreover, Wolverine will purposely stop and restart projections or subscriptions to purposely spread the running load across your entire cluster of running nodes.
In the case of using multi-tenancy through separate databases per tenant with Marten, this Wolverine “agent distribution” will assign the work by tenant databases, meaning that all the running projections and subscriptions for a single tenant database will always be running on a single application node. This was done with the theory that this affinity would hopefully reduce the number of used database connections over all.
If a node is taken offline, Wolverine will detect that the node is no longer accessible and try to move start the missing projection/subscription agents on another active node.
If you run your application on only a single server, Wolverine will of course run all projections and subscriptions on just that one server.
Some other facts about this integration:
Wolverine’s agent distribution does indeed work with per-tenant database multi-tenancy
Wolverine does automatic health checking at the running node level so that it can fail over assigned agents
Wolverine can detect when new nodes come online and redistribute work
Wolverine is able to support blue/green deployment and only run projections or subscriptions on active nodes where a capability is present. This just means that you can add all new projections or subscriptions, or even just new versions of a projection or subscription on some application nodes in order to do try “blue/green deployment.”
This capability does depend on Wolverine’s built-in leadership election — which fortunately got a lot better in Wolverine 3.0
Future Plans
While this functionality will be in the OSS core of Wolverine 3.0, we plan to add quite a bit of support to further monitor and control this feature with the planned “Critter Watch” management console tool we (JasperFx) are building. We’re planning to allow users to:
Visualize and monitor which projections and/or subscriptions are running on which application node
See a correlation to performance metrics being emitted to the Open Telemetry tool of your choice — with Prometheus PromQL compatible tools being supported first
Be able to create affinity groups between projections or subscriptions that might be using the same event data as a possible optimization
Allow individual projections or subscriptions to be paused or restarted
Trigger manual projection rebuilds at runtime
Trigger “rewinds” of subscriptions at runtime
We’re also early in planning to port the Marten event sourcing support to additional database engines. The above functionality will be available for those other database engines when we get there.
This functionality was originally conceived of something like 5-6 years ago, and it’s personally very exciting to me to finally see it out in the wild!
I’ve been helping a JasperFx Software client with their test automation strategy on a new web application and surrounding suite of services. That makes this a perfectly good time to reevaluate how I think teams can succeed with automated testing as an update to what I thought a decade ago. I think you can justifiably describe this post as a stream of consciousness brain dump with just a modicum of editing.
Psych, it took me about four months to actually finish this post, but they’re doing fine as is!
First off, let’s talk about the desirable qualities of a successful test automation strategy.
The backing automated test suite gives you enough confidence to know when your code can be shipped. Mind you, this isn’t about 100% test coverage because that’s rarely practical or cost effective. Instead, this is feeling that there is an acceptably low risk of problems when we deploy if the automated tests are all currently passing. And sorry, I don’t have a hard and fast number to put on that “feeling,” but hopefully you could do so over time by tracking the actual rate of defects from releases.
It’s mechanically easy enough to write the automated tests for your system that the effort in doing so pays off. To some degree you can improve this equation by purposely choosing development tools that lend themselves to automated testing (like Marten and PostgreSQL!). Otherwise, you can also improve the value of the automated tests through some judicious usage of custom testing harnesses or possibly using BDD tools (like Gherkin, but I’ve also had success from time to time with old FIT/FitNesse style testing or even just some one off internal DSL tools) that might make the tests be more declarative.
The automated tests run fast enough to give us an effective feedback cycle — but that’s admittedly 100% subjective. If the tests are too slow, folks won’t run them often enough for the tests to be perfectly helpful and the tests will tend to drift apart from the code. In an ideal world, the tests are running often enough that regression test failures are caught at nearly the same time as the code change that introduced the regression so your teams have an easier time diagnosing the regression problems.
The automated tests are reliable, just meaning that there’s little to no flakiness and you can generally trust the test results as really being a success or failure. User interface testing or any testing involving asynchronous processes are notoriously hard to do reliably, and the flakiness can be a very real problem. Given a choice between having technically more test coverage of a system and the existing test suites being more reliable, I will purposely choose to delete flaky tests as a compromise if it’s not feasible to improve or rewrite the flaky tests first.
Now let’s talk about how to get to the qualities above by covering both some squishy people oriented process stuff and hard technical approaches that I think help lead to better results.
The test automation engineers should ideally be just part of the development team. It takes a lot of close collaboration between developers and test automation engineers to make a test automation strategy actually work. Most of the, let’s nicely say, less successful test automation efforts I’ve seen over time have been at least partially caused by insufficient collaboration between developers and test automation engineers.
There’s always been a sizable backlash and general weariness in regards to Agile Software methods (and was from the very beginning as I recall), but one thing early Agile methods like Extreme Programming got absolutely right was an emphasis on self-contained teams where everybody’s goal is to ship software rather than being narrow specialists on separate teams who only worried about writing code or testing or designing. Or as the Lean Development folks told us, look to optimize the whole process of shipping software rather than any one intermediate deliverable or artifact.
In practice, this “optimize the whole” probably means that developers are full participants in the automated testing, whether that’s simply adjusting the system to make testing easier (especially if your shop is going to make any investment into automating tests through the user interface) or getting their hands dirty helping write “socialable” integration tests. “Optimize the whole” to means that it’s absolutely worth developer’s time to help with test automation efforts and to even purposely make changes in the system architecture to facilitate easier testing if that extra work still results in shipping software faster through quicker testing.
Use the fastest feedback cycle that adequately tests whatever it is you’re trying to test. I’m sure many of you have seen some form of the test automation pyramid:
We could have a debate about exactly what mix of “solitary” unit tests to “sociable” integration tests to end to end, or truly black box end to end tests is ideal in any given situation, but I think the guiding rule is what I referred to years ago as Jeremy’s Only Rule of Testing:
Test with the finest grained mechanism that tells you something important
Let’s make this rule more concrete by considering a few cases and how we might go about automating testing.
First, let’s say that we have a business rule that says that attempting to create an overdraft of a banking account where an account isn’t allowed to do that should reject the requested transactions. That’s absolutely worth an integration test of some sort too, but I’d absolutely vote first for pretty isolated unit tests against just the business logic that doesn’t involve any kind of database or user interface.
On the other hand, one of my clients is utilizing GraphQL between their front end React.js components and the backend. In that case where you won’t really know for sure that the GraphQL sent from the TypeScript client works correctly with the .NET backend without some end to end tests — which is what they are doing with Playwright. All the same though, we did come up with a recipe for testing out the GraphQL endpoints in isolation from the HTTP request level down to the database as a way of testing the database wiring. I’d say that these two types of testing are highly complementary, as it also is to test business logic elements within their GraphQL mutations without the database. One point I recommended to these clients is to move toward, or at least add, more granular tests of some sort anytime the end to end tests are being hard to debug in the case of test failures. In more simpler terms, excessive trouble debugging problems is probably an indication that you might need more fine-grained tests.
Before I get out of this section, let’s just pick on Selenium overuse here as the absolute scourge of successful test automation in the wild (my client is going with Playwright for browser testing instead which would have been my recommendation anyway). End to end tests using Selenium to drive a web browser are naturally much slower and often more work to write than more focused white box integration tests or isolated unit tests would be — not to mention frequently much less reliable. For that reason, I’m personally a big fan of using white box integration tests much more than end to end, black box tests. Living in server side .NET, that to me means testing a lot more at the message handler level, or at the HTTP endpoint level (which is what Alba does for JasperFx clients and Wolverine.HTTP itself).
The test automation code should be in the same repository as the application code.
I’m not sure why this would be even remotely controversial, but I’ve frequently seen it both together with the system code and in completely separate repositories.
As a default approach, the test automation code should be written in the same language as the application code — with a preference for the server side language. I think this would be the first place I’d compromise though because there are so many testing tools that are coupled to the JavaScript world, so maybe never mind this one:)
It’s very advantageous for any automated integration tests to be easily executed locally by developers on demand. What I mean by this is that developers can easily take their current development branch, and run any part of the automated test suite on demand against their current code. There’s a couple major advantages when you can do this:
When tests are broken, and they will be, being able to run the tests locally is a much faster feedback cycle for investigating why the tests are broken that it would be to only be able to run the tests by deploying to a build or test server
It’s very helpful to be able to use automated tests to jump right into debugger session against the code
Developers will be much more likely to help keep the tests up to date with the system code if they at least occasionally run the tests themselves
It’s helpful to use the big end to end tests as a safety net for bigger restructuring work
I’ve seen multiple shops where the end to end tests were written by test automation engineers in a black box manner where the test suites could basically only be executed on centralized test servers and sometimes even only through CI (Continuous Integration) servers. That situation doesn’t seem to ever lead to successful test automation efforts.
Automated tests should be what old colleagues and I called “self-contained” tests. All I mean by this is that I want automated tests to be responsible for setting up the system state for the test within the expression of the test. You want to do this in my opinion for two reasons:
It will make the tests be much more reliable because you can count on the system being in the exact right state for the test
Having the system state set up by the test itself hopefully makes it easier to reason about the test itself and how the system state, action, and assertions all relate to each other
As an alternative, think about tests that depend on some kind of external script setting up a database through a shared data set. From experience, I can tell you that’s often very hard to reason about a failing test when you can’t easily see the test inputs.
No shared databases if you can help it. Again, this isn’t something I think should be controversial in the year 2024. You can easily get some horrendous false positives or false negatives from trying to execute automated tests against a shared database. Given even remotely a choice, I want an isolated database for each developer, tester, or formal testing environment to have isolated test data setup. This does put some onus on teams to have effective database scripting automation — but you want that anyway.
My preference these days is to rely hard on technologies that are friendly to being part of integration tests, which usually means some combination of being easy for developers to run locally and being relatively easy to configure or setup expected state in code within test harnesses. One of the reasons Marten exists in the first place was to have a NoSQL type workflow in development while being able to very easily spin up new databases and to quickly tear down database state between automated test runs.
Give a choice — and you won’t always have that choice, so don’t get too excited here — I strongly prefer to use technologies that have a great local development and testing story over “Cloud only” technologies. If you do need to utilize Cloud only technology (Azure Service Bus being a common example of that in my recent experience), you can ameliorate the problems that causes for testing by somehow letting each developer or testing environment get their own namespace or some other kind of resource isolation like prefixed resource names per environment. The point here is that automated testing always goes better when you have predictable system inputs that you can expect to lead to expected outcomes in tests. Using any kind of shared resource can sometimes lead to untrustworthy test results.
Older Writings
I’ve written a lot about automated testing over the years, and this post admittedly overlaps with a lot of previous writing — but it’s also kind of fun to see what has or hasn’t evolved in my own thinking:
I realize the title sounds a little too similar to somebody else’s 2025 platform proposals, but let’s please just overlook that
This is a “vision board” document I wrote up and shared with our core team (Anne, JT, Babu, and Jeffry) as well as some friendly users and JasperFx Software customers. I dearly want to step foot into January 2025 with the “Critter Stack” as a very compelling choice for any shop about to embark on any kind of Event Driven Architecture — especially with the usage of Event Sourcing as part of a system’s persistence strategy. Moreover, I want to arrive at a point where the “Critter Stack” actually convinces organizations to choose .NET just to take advantage of our tooling.I’d be grateful for any feedback.
As of now, the forthcoming Wolverine 3.0 release is almost to the finish line, Marten 7 is probably just about done growing, and work on “Critter Watch” (JasperFx Software’s envisioned management console tooling for the “Critter Stack”) is ramping up. Now is a good time to detail a technical vision for the “Critter Stack” moving into 2025.
The big goals are:
Simplify the “getting started” story for using the “Critter Stack”. Not just in getting a new codebase up, but going all the way to how a Critter Stack app could be deployed and opting into all the best practices. My concern is that there are getting to be way too many knobs and switches scattered around that have to be addressed to really make performance and deployment robust.
Deliver a usable “Critter Watch” MVP
Expand the “Critter Stack” to more database options, with Sql Server and maybe CosmosDb being the leading contenders and DynamoDb or CockroachDb being later possibilities
Streamline the dependency tree. Find a way to reduce the number of GitHub repositories and Nugets if possible. Both for our maintenance overhead and also to try to simplify user setup
“Critter Watch” and CritterStackPro.Projections (actually scratch the second part, that’s going to roll into the Wolverine OSS core, coming soon)
Ermine 1.0 – the Sql Server port of the Marten event store functionality
Out of the box project templates for Wolverine/Marten/Ermine usages – following the work done already by Jeffry Gonzalez
Future CosmosDb backed event store and Wolverine integration — but I’m getting a lot of mixed feedback about whether Sql Server or CosmosDb should be a higher priority
Opportunities to grow the Critter Stack user base:
Folks who are concerned about DevOps issues. “Critter Watch” and maybe more templates that show how to apply monitoring, deployment steps, and Open Telemetry to existing Critter Stack systems. The key point here is a whole lot of focus on maintainability and sustainability of the event sourcing and messaging infrastructure
Get more interest from mainstream .NET developers. Improve the integration of Wolverine and maybe Marten/Ermine as well with EF Core. This could include reaching parity with Marten for middleware support, side effects, and multi-tenancy models using EF Core. Also, maybe, hear me out, take a heavy drink, there could be an official Marten/Ermine projection integration to write projection data to EF Core? I know of at least one Critter Stack user who would use that. At this point, I’m leaning heavily toward getting Wolverine 3.0 out and mostly tackle this in the Wolverine 4.0 timeframe this fall
Expand to Sql Server for more “pure” Microsoft shops. Adding databases to the general Wolverine / Event Sourcing support (the assumption here is that the document database support in Marten would be too much work to move)
Introduce Marten and Wolverine to more people, period. Moar “DevRel” type activity! More learning videos. I’ll keep trying to do more conferences and podcasts. More sample applications. Some ideas for new samples might be a sample application with variations using each transport, using Wolverine inside of a modular monolith with multiple Marten stores and/or EF DbContexts, HTTP services, background processing. Maybe actually invest in some SEO for the websites.
Ecosystem Realignment
With major releases coming up with both Marten 8.0 and Wolverine 4.0 and the forthcoming Ermine, there’s an “opportunity” to change the organization of the code to streamline the number of GitHub repositories and Nugets floating around while also centralizing more code. There’s also an opportunity to centralize a lot of infrastructure code that could help the Ermine effort go much faster. Lastly, there are some options like code generation settings and application assembly determination that are today independently configured for Marten and Wolverine which repeatedly trips up our users (and flat out annoys me when I build sample apps).
We’re actively working to streamline the configuration code, but in the meantime, the current thinking about some of this is in the GitHub issue for JasperFx Ecosystem Dependency Reorganization. The other half of that is the content in the next section.
Projection Model Reboot
This refers to the “Reboot Projection Model API” in the Marten GitHub issue list. The short tag line is to move toward enabling easier usage of folks just writing explicit code. I also want us to tackle the absurdly confusing API for “multi-stream projections” as well. This projection model will be shared across Marten, Ermine (Sql Server-backed event store), and any future CosmosDb/DynamoDb/CockroachDb event stores.
Wrapping up Marten 7.0
Marten 7 introduced a crazy amount of new functionality on top of the LINQ rewrite, the connection management rewrite, and introduction of Polly into the core. Besides some (important) ongoing work for JasperFx clients, the remainder of Marten 7 is hopefully just:
Mark all synchronous APIs that invoke database access as [Obsolete]
Make a pass over the projection model and see how close to the projection reboot you could get. Make anything that doesn’t conform to the new ideal be [Obsolete] with nudges
Introduce the new standard code generation / application assembly configuration in JasperFx.CodeGeneration today. Mark Marten’s version of that as [Obsolete] with a pointer to using the new standard – which is hopefully very close minus namespaces to where it will be in the end
Wrapping up Wolverine 3.0
Introduce the new standard code generation / application assembly configuration in JasperFx.CodeGeneration today. Mark Marten’s version of that as [Obsolete] with a pointer to using the new standard – which is hopefully very close minus namespaces to where it will be in the end
Put a little more error handling in for code generation problems just to make it easier to fix issues later
Maybe, reexamine what work could be done to make modular monoliths easier with Wolverine and/or Marten
Maybe, consider adding back into scope improvements for EF Core with Wolverine – but I’m personally tempted to let that slide to the Wolverine 4 work
Summary
The Critter Stack core & I plus the JasperFx Software folks have a pretty audaciously ambitious plan for next year. I’m excited for it, and I’ll be talking about it in public as much as y’all will let me get away with it!
I know, command line parsing libraries are about the least exciting tooling in the entire software universe, and there are dozens of perfectly competent ones out there. Oakton though, is heavily used throughout the entire “Critter Stack” (Marten, Weasel, and Wolverine plus other tools) to provide command line utilities directly to any old .NET Core application that happens to be bootstrapped with one of the many ways to arrive at an IHost. Oakton’s key advantage over other command line parsing tools is its ability to easily add extension commands to a .NET application in external assemblies. And of course, as part of the entire JasperFx / Critter Stack philosophy of developer tooling, Oakton’s very concept was originally created to enhance the testability of custom command line tooling. Unlike some other tools *cough* System.CommandLine *cough*.
Oakton also has some direct framework-ish elements for environment checks and the stateful resource model used very heavily all the way through Marten and Wolverine to provide the very best development time experience possible when using our tools.
Today the extended JasperFx / Critter Stack community released Oakton 6.2 with some new, hopefully important use cases. First off, the stateful resource model that we use to setup, teardown, or just check “configured stateful resources” in our system like database schemas or message broker queues just got the concept of dependencies between resources such that you can control which resources are setup first.
Next, Oakton finally got a couple easy to use recipes for utilizing IoC services in Oakton commands (it was possible, just maybe a little higher ceremony that some folks prefer). The first way, assuming that you’re running Oakton from one of the many flavors of IHostBuilder or IHost like so:
// This would be the last line in your Program.Main() method
// "app" in this case is a WebApplication object, but there
// are other extension methods for headless services
return await app.RunOaktonCommands(args);
You can build an Oakton command class that uses “setter injection” to get IoC services like so:
public class MyDbCommand : OaktonAsyncCommand<MyInput>
{
// Just assume maybe that this is an EF Core DbContext
[InjectService]
public MyDbContext DbContext { get; set; }
public override Task<bool> Execute(MyInput input)
{
// do stuff with DbContext from up above
return Task.FromResult(true);
}
}
Just know that when you do this and execute a command that has decorated properties for services, Oakton is:
Building your system’s IHost
Creating a new IServiceScope from your application’s DI container, or in other words, a scoped container
Building your command object and setting all the dependencies on your command object by resolving each dependency from the scoped container created in the previous step
Executing the command as normal
Disposing the scoped container and the IHost, effectively in a try/finally so that Oakton is always cleaning up after the application
In other words, Oakton is largely taking care of annoying issues like object disposal cleanup, scoping, and actually building the IHost if necessary.
Oakton’s Future
The Critter Stack Core team & I are charting a course for our entire ecosystem I’m calling “Critter Stack 2025” that’s hoping to greatly reduce the technical challenges in adopting our tool set. As part of that, what’s now Oakton is likely to move into a new shared library (I think it’s just going to be called “JasperFx”) between the various critters (and hopefully new critters for 2025!). Oakton itself will probably get a temporary life as a shim to the new location as a way to ease the transition for existing users. There’s a balance between actively improving your toolset for potential new users and not disturbing existing users too much. We’re still working on whatever that balance ends up being.
Building and maintaining a large, hosted system that requires multi-tenancy comes with a fair number of technical challenges. JasperFx Software has helped several of our clients achieve better results with their particular multi-tenancy challenges with Marten and Wolverine, and we’re available to do the same for your shop! Drop us a message on our Discord server or email us at sales@jasperfx.net to start a conversation.
This is continuing a series about multi-tenancy with Marten, Wolverine, and ASP.Net Core:
Using Partitioning for Better Performance with Multi-Tenancy and Marten (future)
Multi-Tenancy in Wolverine with EF Core & Sql Server (future, and honestly, future functionality as part of Wolverine 4.0)
Dynamic Tenant Creation and Retirement in Marten and Wolverine (definitely in the future)
Let’s say that you’re using the Marten + PostgreSQL combination for your system’s persistence needs in a web service application. Let’s also say that you want to keep the customer data within your system in completely different databases per customer company (or whatever makes sense in your system). Lastly, let’s say that you’re using Wolverine for asynchronous messaging and as a local “mediator” tool. Fortunately, Wolverine by itself has some important built in support for multi-tenancy with Marten that’s going to make your system a lot easier to build.
Let’s get started by just showing a way to opt into multi-tenancy with separate databases using Marten and its integration with Wolverine for middleware, saga support, and the all important transactional outbox support:
// Adding Marten for persistence
builder.Services.AddMarten(m =>
{
// With multi-tenancy through a database per tenant
m.MultiTenantedDatabases(tenancy =>
{
// You would probably be pulling the connection strings out of configuration,
// but it's late in the afternoon and I'm being lazy building out this sample!
tenancy.AddSingleTenantDatabase("Host=localhost;Port=5433;Database=tenant1;Username=postgres;password=postgres", "tenant1");
tenancy.AddSingleTenantDatabase("Host=localhost;Port=5433;Database=tenant2;Username=postgres;password=postgres", "tenant2");
tenancy.AddSingleTenantDatabase("Host=localhost;Port=5433;Database=tenant3;Username=postgres;password=postgres", "tenant3");
});
m.DatabaseSchemaName = "mttodo";
})
.IntegrateWithWolverine(masterDatabaseConnectionString:connectionString);
Just for the sake of completion, here’s some sample Wolverine configuration that pairs up with the above:
// Wolverine usage is required for WolverineFx.Http
builder.Host.UseWolverine(opts =>
{
// This middleware will apply to the HTTP
// endpoints as well
opts.Policies.AutoApplyTransactions();
// Setting up the outbox on all locally handled
// background tasks
opts.Policies.UseDurableLocalQueues();
});
Now that we’ve got that basic setup for Marten and Wolverine, let’s move on to the first issue, how the heck does Wolverine “know” which tenant should be used? In a later post I’ll show how Wolverine.HTTP has built in tenant id detection, but for now, let’s pretend that you’re already taking care of tenant id detection from incoming HTTP requests some how within your ASP.Net Core pipeline and you just need to pass that into a Wolverine message handler that is being executed from within an MVC Core controller (“Wolverine as Mediator”):
[HttpDelete("/todoitems/{tenant}/longhand")]
public async Task Delete(
string tenant,
DeleteTodo command,
IMessageBus bus)
{
// Invoke inline for the specified tenant
await bus.InvokeForTenantAsync(tenant, command);
}
By using the IMessageBus.InvokeForTenantAsync() method, we’re invoking a command inline, but telling Wolverine what the tenant id is. The command handler might look something like this:
// Keep in mind that we set up the automatic
// transactional middleware usage with Marten & Wolverine
// up above, so there's just not much to do here
public static class DeleteTodoHandler
{
public static void Handle(DeleteTodo command, IDocumentSession session)
{
session.Delete<Todo>(command.Id);
}
}
Not much going on there in our code, but Wolverine is helping us out here by:
Seeing the tenant id value that we passed in before that Wolverine is tracking in its own Envelope structure (Wolverine’s version of Envelope Wrapper from the venerable EIP book)
Creates the Marten IDocumentSession for that tenant id value, which will be reading and writing to the correct tenant database underneath Marten
Now, let’s make this a little more complex by also publishing an event message in that message handler for the DeleteTodo message:
public static class TodoCreatedHandler
{
public static TodoDeleted Handle(DeleteTodo command, IDocumentSession session)
{
session.Delete<Todo>(command.Id);
// This
return new TodoDeleted(command.Id);
}
}
public record TodoDeleted(int TodoId);
Assuming that the TodoDeleted message is being published to a “durable” endpoint, Wolverine is using its transactional outbox integration with Marten to persist the outgoing message in the same tenant database and same transaction as the deletion we’re doing in that command handler. In other words, Wolverine is able to use the tenant databases for its outbox support with no other configuration necessary than what we did up above in the calls to AddMarten() and UseWolverine().
Moreover, Wolverine is even able to use its “durability agent” against all the tenant databases to ensure that any work that is somehow stranded by crashed processes.
Lastly, the TodoDeleted event message cascaded above from our message handler would be tracked throughout Wolverine with the tenant id of the original DeleteToDo command message so that you can do multi-part workflows through Wolverine while tracks the tenant id and utilizes the correct tenant database through Marten all along the way.
Summary
Building solutions with multi-tenancy can be complicated, but the Wolverine + Marten combination can make it a lot easier.
Hey, did you know that JasperFx Software offers both consulting services and support plans for the “Critter Stack” tools? Or for architectural or test automation help with any old server side .NET application. One of the other things we do is to build out custom features that our customers need in the “Critter Stack” — like the Marten-managed table partitioning for improved scaling and performance in this release!
A fairly sizable Marten 7.28 release just went live — or will at least be available on Nuget by the time you read this with a mix of new features and usability improvements. The biggest new feature is “Marten-Managed Table Partitioning by Tenant.” Lots of words! Consider this scenario:
You have a system with a huge number of events
You also need to use Marten’s support for multi-tenancy
For historical reasons and for the easy of deployment and management, you are using Marten’s “conjoined” multi-tenancy model and keeping all of your tenant data in the same database (this might have some very large cloud hosting cost saving benefits as well)
You want to be able to scale the database performance for all the normal reasons
PostgreSQL table partitioning to the rescue! In recent Marten releases, we’ve added support to take advantage of postgres table sharding as a way to improve performance in many operations — with one of the obvious first usages using table sharding per tenant id for Marten’s “conjoined” tenancy model. Great! Just tell Marten exactly what the tenant ids are and the matching partition configuration and go!
But wait, what if you have a very large number of tenants and might need to even add new tenants at runtime and without incurring any kind of system downtime? Marten now has a partitioning feature for multi-tenancy that can dynamically create per-tenant shards at runtime and manage the list of tenants in its own database storage like so:
var builder = Host.CreateApplicationBuilder();
builder.Services.AddMarten(opts =>
{
opts.Connection(builder.Configuration.GetConnectionString("marten"));
// Make all document types use "conjoined" multi-tenancy -- unless explicitly marked with
// [SingleTenanted] or explicitly configured via the fluent interfce
// to be single-tenanted
opts.Policies.AllDocumentsAreMultiTenanted();
// It's required to explicitly tell Marten which database schema to put
// the mt_tenant_partitions table
opts.Policies.PartitionMultiTenantedDocumentsUsingMartenManagement("tenants");
});
With some management helpers of course:
await theStore
.Advanced
// This is ensuring that there are tenant id partitions for all multi-tenanted documents
// with the named tenant ids
.AddMartenManagedTenantsAsync(CancellationToken.None,"a1", "a2", "a3");
If you’re familiar with the pg_partman tool, this was absolutely meant to fulfill a similar role within Marten for per-tenant table partitioning.
Aggregation Projections with Explicit Code
This is probably long overdue, but the other highlight that’s probably much more globally applicable is the ability to write more Marten event aggregation projections with strictly explicit code for folks who don’t care for the Marten conventional method approaches — or just want a more complicated workflow than what the conventional approaches can do.
You still need to use the CustomProjection<TDoc, TId> base class for your logic, but now there are simpler methods that can be overloaded to express explicit “left fold over events to create an aggregated document” logic as shown below:
public class ExplicitCounter: CustomProjection<SimpleAggregate, Guid>
{
public override SimpleAggregate Apply(SimpleAggregate snapshot, IReadOnlyList<IEvent> events)
{
snapshot ??= new SimpleAggregate();
foreach (var e in events.Select(x => x.Data))
{
if (e is AEvent) snapshot.ACount++;
if (e is BEvent) snapshot.BCount++;
if (e is CEvent) snapshot.CCount++;
if (e is DEvent) snapshot.DCount++;
}
// You have to explicitly return the new value
// of the aggregated document no matter what!
return snapshot;
}
}
The explicitly coded projections can also be used for live aggregations (AggregateStreamAsync()) and within FetchForWriting() as well. This has been a longstanding request, and will receive even stronger support in Marten 8.
LINQ Improvements
Supporting a LINQ provider is the gift that never stops giving. There’s some small improvements this time around for some minor things:
// string.Trim()
session.Query<SomeDoc>().Where(x => x.Description.Trim() = "something");
// Select to TimeSpan out of a document
session.Query<SomeDoc>().Select(x => x.Duration).ToListAsync();
// Query the raw event data by event types
var raw = await theSession.Events.QueryAllRawEvents()
.Where(x => x.EventTypesAre(typeof(CEvent), typeof(DEvent)))
.ToListAsync();
Hey, did you know that JasperFx Software offers both consulting services and support plans for the “Critter Stack” tools? Or for architectural or test automation help with any old server side .NET application. One of the other things we do is to build out custom features that our customers need in the “Critter Stack” — like the RavenDb integration from this post!
Wolverine will depend on having RavenDb integrated with your application’s DI container, so make sure you’re also using RavenDB.DependencyInjection. With those two dependencies, the code set up is just this:
var builder = Host.CreateApplicationBuilder();
// You'll need a reference to RavenDB.DependencyInjection
// for this one
builder.Services.AddRavenDbDocStore(raven =>
{
// configure your RavenDb connection here
});
builder.UseWolverine(opts =>
{
// That's it, nothing more to see here
opts.UseRavenDbPersistence();
// The RavenDb integration supports basic transactional
// middleware just fine
opts.Policies.AutoApplyTransactions();
});
// continue with your bootstrapping...
And that’s it. Adding that line of UseRavenDbPersistence() to the Wolverine set up adds in support for Wolverine to use RavenDb as:
This also includes a RavenDb-specific set of Wolverine “side effects” you can use to build synchronous, pure function handlers using RavenDb like so:
public record RecordTeam(string Team, int Year);
public static class RecordTeamHandler
{
public static IRavenDbOp Handle(RecordTeam command)
{
return RavenOps.Store(new Team { Id = command.Team, YearFounded = command.Year });
}
}
This code is of course in early stages and will surely be adapted after some load testing and intended production usage by our client, but the RavenDb integration with Wolverine is now “officially” supported.
I can’t speak to any kind of timing, but there will be more options for database integration with Wolverine in the somewhat near future as well. This effort helped us break off some reusable “compliance” tests that should help speed up the development of future database integrations with Wolverine.
Hey, did you know that JasperFx Software offers both consulting services and support plans for the “Critter Stack” tools? One of the common areas where we’ve helped our clients is in using Marten or Wolverine when the usage involves quite a bit of potential concerns about concurrency. As I write this, I’m currently working with a JasperFx client to implement the FetchForWriting API shown in this post as a way of improving their system’s resiliency to concurrency problems.
You’ve decided to use event sourcing as your persistence strategy, so that your persisted state of record are the actual business events segregated by streams that represent changes in state to some kind of logical business entity (an invoice? an order? an incident? a project?). Of course there will have to be some way of resolving or “projecting” the raw events into a usable view of the system state, but we’ll get to that.
You’ve also decided to organize your system around a CQRS architectural style (Command Query Responsibility Segregation). With a CQRS approach, the backend code is mostly organized around the “verbs” of your system, meaning the “command” messages (this could be HTTP services, and I’m not implying that there automatically has to be any asynchronous messaging) that are handled to capture changes to the system (events in our case), and “query” endpoints or APIs that strictly serve up information about your system.
While it’s certainly possible to do either Event Sourcing or CQRS without the other, the two things do go together as Forrest Gump would say, like peas and carrots.Marten is certainly valuable as part of a CQRS with Event Sourcing approach within a range of .NET messaging or web frameworks, but there is quite a bit of synergy between Marten and its “Critter Stack” stable mate Wolverine (see the details about the integration here).
And lastly of course, you’ve quite logically decided to use Marten as the persistence mechanism for the events. Marten is also a strong fit because it comes with some important functionality that we’ll need for CQRS command handlers:
Marten’s event projection support can give us a representation of the current state of the raw event data in a usable way that we’ll need within our command handlers to both validate requested actions and to “decide” what additional events should be persisted to our system
The FetchForWriting API in Marten will not only give us access to the projected event data, but it provides an easy mechanism for both optimistic and pessimistic concurrency protections in our system
Marten allows for a couple different options of projection lifecycle that can be valuable for performance optimization with differing system needs
As a sample application problem domain, I got to be part of a successful effort during the worst of the pandemic to stand up a new “telehealth” web portal using event sourcing. One of the concepts in that system that we needed to track in that system was the activity of a health care provider (nurse, doctor, nurse practitioner) with events for when they were available and what they were doing at any particular time during the day for later decision making:
public record ProviderAssigned(Guid AppointmentId);
public record ProviderJoined(Guid BoardId, Guid ProviderId);
public record ProviderReady;
public record ProviderPaused;
public record ProviderSignedOff;
// "Charting" is basically just whatever
// paperwork they need to do after
// an appointment, and it was important
// for us to track that time as part
// of their availability and future
// planning
public record ChartingFinished;
public record ChartingStarted;
public enum ProviderStatus
{
Ready,
Assigned,
Charting,
Paused
}
But of course, at several points, you do actually need to know what the actual state of the provider’s current shift is to be able to make decisions within the command handlers, so we had a “write” model something like this:
// I'm sticking the Marten "projection" logic for updating
// state from the events directly into this "write" model,
// but you could separate that into a different class if you
// prefer
public class ProviderShift
{
public Guid Id { get; set; }
// This is important, this would be set by Marten to the
// current event number or revision of the ProviderShift
// aggregate. This is going to be important later for
// concurrency protections
public int Version { get; set; }
public Guid BoardId { get; private set; }
public Guid ProviderId { get; init; }
public ProviderStatus Status { get; private set; }
public string Name { get; init; }
public Guid? AppointmentId { get; set; }
// The Create & Apply methods are conventional targets
// for Marten's "projection" capabilities
// But don't worry, you would never *have* to take a reference
// to Marten itself like I did below jsut out of laziness
public static ProviderShift Create(
ProviderJoined joined)
{
return new ProviderShift
{
Status = ProviderStatus.Ready,
ProviderId = joined.ProviderId,
BoardId = joined.BoardId
};
}
public void Apply(ProviderReady ready)
{
AppointmentId = null;
Status = ProviderStatus.Ready;
}
public void Apply(ProviderAssigned assigned)
{
Status = ProviderStatus.Assigned;
AppointmentId = assigned.AppointmentId;
}
public void Apply(ProviderPaused paused)
{
Status = ProviderStatus.Paused;
AppointmentId = null;
}
// This is kind of a catch all for any paperwork the
// provider has to do after an appointment has ended
// for the just concluded appointment
public void Apply(ChartingStarted charting)
{
Status = ProviderStatus.Charting;
}
}
The whole purpose of the ProviderShift type above is to be a “write” model that contains enough information for the command handlers to “decide” what should be done — as opposed to a “read” model that might have richer information like the provider’s name that would be more suitable or usable for using within a user interface. “Write” or “read” in this case is just a role within the system, and at different times it might be valuable to have separate models for different consumers of the information and in other times be able to happily get by with a single model.
Alright, so let’s finally look at a very simple command handler related to providers that tries to mark the provider as being finished charting:
// Since we're focusing on Marten, I'm using an MVC Core
// controller just because it's commonly used and understood
public class CompleteChartingController : ControllerBase
{
[HttpPost("/provider/charting/complete")]
public async Task Post(
[FromBody] CompleteCharting charting,
[FromServices] IDocumentSession session)
{
// We're looking up the current state of the ProviderShift aggregate
// for the designated provider
var stream = await session
.Events
.FetchForWriting<ProviderShift>(charting.ProviderShiftId, HttpContext.RequestAborted);
// The current state
var shift = stream.Aggregate;
if (shift.Status != ProviderStatus.Charting)
{
// Obviously do something smarter in your app, but you
// get the point
throw new Exception("The shift is not currently charting");
}
// Append a single new event just to say
// "charting is finished". I'm relying on
// Marten's automatic metadata to capture
// the timestamp of this event for me
stream.AppendOne(new ChartingFinished());
// Commit the transaction
await session.SaveChangesAsync();
}
}
I’m using the Marten FetchForWriting() API to get at the current state of the event stream for the designated provider shift (a provider’s activity during a single day). I’m also using this API to capture a new event marking the provider as being finished with charting. FetchForWriting() is doing two important things for us:
Executes or finds the projected data for ProviderShift from the raw events. More on this a little later
Provides a little bit of optimistic concurrency protection for our provider shift stream
Building on the theme of concurrency first, the command above will “remember” the current state of the ProviderShift at the point that FetchForWriting() is called. Upon SaveChangesAsync(), Marten will reject the transaction and throw a ConcurrencyException if some how, some way, some other request magically came through and completed against that same ProviderShift stream between the call to FetchForWriting() and SaveChangesAsync().
That level of concurrency is baked in, but we can do a little bit better. Remember that the ProviderShift has this property:
// This is important, this would be set by Marten to the
// current event number or revision of the ProviderShift
// aggregate. This is going to be important later for
// concurrency protections
public int Version { get; set; }
The projection capability of Marten makes it easy for us to “know” and track the current version of the ProviderShift stream so that we can feed it back to command handlers later. Here’s the full definition of the CompleteCharting command:
public record CompleteCharting(
Guid ProviderShiftId,
// This version is meant to mean "I was issued
// assuming that the ProviderShift is currently
// at this version in the server, and if the version
// has shifted since, then this command is now invalid"
int Version
);
Let’s tighten up the optimistic concurrency protection such that Marten will shut down the command handling faster before we waste system resources doing unnecessary work by passing the command version right into this overload of FetchForWriting():
// Since we're focusing on Marten, I'm using an MVC Core
// controller just because it's commonly used and understood
public class CompleteChartingController : ControllerBase
{
[HttpPost("/provider/charting/complete")]
public async Task Post(
[FromBody] CompleteCharting charting,
[FromServices] IDocumentSession session)
{
// We're looking up the current state of the ProviderShift aggregate
// for the designated provider
var stream = await session
.Events
.FetchForWriting<ProviderShift>(
charting.ProviderShiftId,
// Passing the expected, starting version of ProviderShift
// into Marten
charting.Version,
HttpContext.RequestAborted);
// And the rest of the controller stays the same as
// before....
}
}
In the usage above, Marten will do a version check both at the point of FetchForWriting() using the version we passed in, and again during the call to SaveChangesAsync() to reject any changes made if there was a concurrent update to that same stream.
Lastly, Marten gives you the ability to opt into heavier, exclusive access to the ProviderShift with this option:
// We're looking up the current state of the ProviderShift aggregate
// for the designated provider
var stream = await session
.Events
.FetchForExclusiveWriting<ProviderShift>(
charting.ProviderShiftId,
HttpContext.RequestAborted);
In that last usage, we’re relying on the underlying PostgreSQL database to get us an exclusive row lock on the ProviderShift event stream such that only our current operation is allowed to write to that event stream while we have the lock. This is heavier and comes with some risk of database locking problems, but solves the concurrency issue.
So that’s concurrency protection in FetchForWriting(), but I mostly skipped over when and how that API will execute the projection logic to go from the raw events like ProviderJoined, ProviderReady, or ChartingStarted to the projected ProviderShift.
Any projection in Marten can be calculated or executed with three different “projection lifecycles”:
Live — in this case, a projection is calculated on the fly by loading the raw events in memory and calculating the current state right then and there. In the absence of any other configuration, this is the default lifecycle for the ProviderShift per stream aggregation.
Inline — a projection is updated at the time any events are appended by Marten and persisted by Marten as a document in the PostgreSQL database.
Async — a projection is updated in a background process as events are captured by Marten across the system. The projected state is persisted as a Marten document to the underlying PostgreSQL database
The first two options give you strong consistency models where the projection will always reflect the current state of the events captured to the database. Live is probably a little more optimal in the case where you have many writes, but few reads, and you want to optimize the “write” side. Inline is optimal for cases where you have few writes, but many reads, and you want to optimize the “read” side (or need to query against the projected data rather than just load by id). The Async model gives you the ability to take the work of projecting events into the aggregated state out of both the “write” and “read” side of things. This might easily be advantageous for performance and very frequently necessary for ordering or concurrency concerns.
In the case of the FetchForWriting() API, you will always have a strongly consistent view of the raw events because that API is happily wallpapering over the lifecycle for you. Live aggregation works as you’d expect, Inline aggregation works by just loading the expected document directly from the database, and Async aggregation is a hybrid model that starts from the last known persisted value for the aggregate and applies any missing events right on top of that (the async behavior was a big feature added in Marten 7).
By hiding the actual lifecycle behavior behind the FetchForWriting() signature, teams are able to experiment with different approaches to optimize their application without breaking existing code.
Summary
FetchForWriting() was built specifically to ease the usage of Marten within CQRS command handlers after seeing how much boilerplate code teams were having to use before with Marten. At this point, this is our strongly recommended approach for command handlers. Also note that this API is utilized within the Wolverine + Marten “aggregate handler workflow” usage that does even more to remove code ceremony from CQRS command handler code. To some degree, what is now Wolverine was purposely rebooted and saved from the scrap heap specifically because of that combination with Marten and the FetchForWriting API.
Personally, I’m opposed to any kind of IAggregateRepository or approach where the “write” model itself tracks the events that are applied or uncommitted. I’m trying hard to discourage folks using Marten away from this still somewhat popular old approach in favor of a more Functional Programming-ish approach.
FetchForWriting could be used as part of a homegrown “Decider” pattern usage if that’s something you prefer (I think the “decider” pattern in real life usage ends up devolving into brute force procedural code through massive switch statements personally).
The “telehealth” system I mentioned before was built in real life with a hand-rolled Node.js event sourcing implementation, but that experience has had plenty of influence over later Marten work including a feature that just went into Marten over the weekend for a JasperFx client to be able to emit “side effect” actions and messages during projection updates.
I was deeply unimpressed with the existing Node.js tooling for event sourcing at that time (~2020), but I would hope it’s much better now. Marten has absolutely grown in capability in the past couple years.
Hey, did you know that JasperFx Software offers both consulting services and support plans for the “Critter Stack” tools? The new feature shown in this post was done at the behest of a JasperFx support customer. And of course, we’re also more than happy to help you with any kind of .NET backend development:)
Wolverine‘s new 3.0.0-beta-1 release adds a long requested feature set for batching up message handling. What does that mean? Well, sometimes you might want to process a stream of incoming messages in batches rather than one at a time. This might be for performance reasons, or maybe there’s some kind of business logic that makes more sense to calculate for batches, or maybe you want a logical “debounce” in how your system responds to the incoming messages so you don’t update some resource on every single message received by your system.
And for whatever reason, we need to process these messages in batches. To do that, we first need to have a message handler for an array of Item like so:
public static class ItemHandler
{
public static void Handle(Item[] items)
{
// Handle this just like a normal message handler,
// just that the message type is Item[]
}
}
And yes, before you ask, so far Wolverine only understands an array of the batched message type as the input message for the batch handler.
With that in our system, now we need to tell Wolverine to group Item messages, and we do that with the following syntax:
theHost = await Host.CreateDefaultBuilder()
.UseWolverine(opts =>
{
opts.BatchMessagesOf<Item>(batching =>
{
// Really the maximum batch size
batching.BatchSize = 500;
// You can alternatively override the local queue
// for the batch publishing.
batching.LocalExecutionQueueName = "items";
// We can tell Wolverine to wait longer for incoming
// messages before kicking out a batch if there
// are fewer waiting messages than the maximum
// batch size
batching.TriggerTime = 1.Seconds();
})
// The object returned here is the local queue configuration that
// will handle the batched messages. This may be useful for fine
// tuning the behavior of the batch processing
.Sequential();
}).StartAsync();
A particularly lazy and hopefully effective technique in OSS project documentation is to take code snippets directly out of test code, and that’s what you see above. Two birds with one stone. Sometimes that works out well.
[Fact]
public async Task send_end_to_end_with_batch()
{
// Items to publish
var item1 = new Item("one");
var item2 = new Item("two");
var item3 = new Item("three");
var item4 = new Item("four");
Func<IMessageContext, Task> publish = async c =>
{
// I'm publishing the 4 items in sequence
await c.PublishAsync(item1);
await c.PublishAsync(item2);
await c.PublishAsync(item3);
await c.PublishAsync(item4);
};
// This is the "act" part of the test
var session = await theHost.TrackActivity()
// Wolverine testing helper to "wait" until
// the tracking receives a message of Item[]
.WaitForMessageToBeReceivedAt<Item[]>(theHost)
.ExecuteAndWaitAsync(publish);
// The four Item messages should be processed as a single
// batch message
var items = session.Executed.SingleMessage<Item[]>();
items.Length.ShouldBe(4);
items.ShouldContain(item1);
items.ShouldContain(item2);
items.ShouldContain(item3);
items.ShouldContain(item4);
}
Alright, with all that being said, here’s a few more facts about the batch messaging support:
There is absolutely no need to create a specific message handler for the Item message, and in fact, you should not do so
The message batching is able to group the message batches by tenant id if your Wolverine system uses multi-tenancy
If you are using a durable inbox in your system, Wolverine is not marking the incoming envelopes as handled until the messages are successfully handled inside a batch message
Likewise, if a batch message fails to the point where it triggers a move to the dead letter queue, each individual message that was part of that original batch is moved to the dead letter queue separately
Summary
Hey, that’s actually all I had to say about that! Wolverine 3.0 will hopefully go RC later this week or next, with the official release *knock on wood* happening before I leave for Swetugg and a visit in Copenhagen with a JasperFx client in a couple weeks.
This conceptual idea is apparently known to philosophers as “Eternal return” or “eternal recurrence.” Funny story for me, I worked with a business analyst one time who was a former philosopher. To purposely antagonize him, I gave a super amateurish explanation of Descartes writings and how I thought they applied to engineering in principle where I knew he could hear just to torture him while I butchered the subject. Coincidentally, this project had a bi-weekly mandatory team morale meeting. Go figure.
I can’t find the source of this quote today, but I’ve frequently heard and repeatedly used the following phrase to other folks (maybe from here?):
Software is never finished, only abandoned
I predominantly work with long lived codebases for software tools used by other developers. A very common source of frustration for me is making a bug fix release to burn down the open issue list, only to have all new issues get raised in the next couple hours. To some degree, any complicated software project is naturally going to feel like a Sisyphean task if you think of time as a straight line to being “finished” with the project for good.
Maybe this is a special problem for development tools (and I’ve worked on enough long lived business systems to say that nope, this is a pretty common issue for any long lived codebase), but no matter how hard I and the rest of the Critter Stack community try, folks will continuously come out of the wood work to:
Report previously unknown bugs
Stumble on unanticipated usages that aren’t well supported
Hit performance or concurrency problems that haven’t come up before
Simply make compelling suggestions about some new kind of use case for the tooling
Need to integrate your tool with some different sort of infrastructure or even a different runtime
Point out gaps in the documentation
Describe content in the documentation that isn’t clear enough, or flat out misstated
Express frustration about information they want to find in the documentation, but cannot — even if it is there, but just not in a way that made sense for the user to find
It’s admittedly exhausting sometimes trying to be “done” with long lived projects. I think my advice — not that I always live this myself — is to think of these projects as more of a cycle and a continuous process of slow, steady improvement rather than any kind of concrete project to be completed. For me especially, I need to constantly remind myself that technical documentation has to constantly pruned and improved in the face of user feedback.
My other scattered pieces of advice for dealing with the ownership of long lived codebases is to:
Grant yourself some grace and not let it weigh on you just because there are some open bug reports or open questions at the moment
Give yourself permission to unplug from message boards, chat rooms, or social media when you just need some mental rest when off work or even when you just need to focus during a work day. I sometimes have to completely switch off Discord some days when I’m at my limit of incoming questions or problems
Have reasonable expectations for how fast you should be dealing with user issues, bugs, and feature requests — with the caveat for me that it’s a very different thing when those come in from paying clients or maybe even just from other contributors
And lastly, if nothing else, unplug immediately and walk away if you find yourself either being or wanting to be snappish or brusk or sarcastic or rude to people asking for help online. Again, be better than I am at this one:)
I’ve worked over the past year with a couple clients who were building greenfield systems with “Critter Stack” tools, and let me tell you, that’s been a blessing for my mental health. Whenever you get to do greenfield work, appreciate that time.