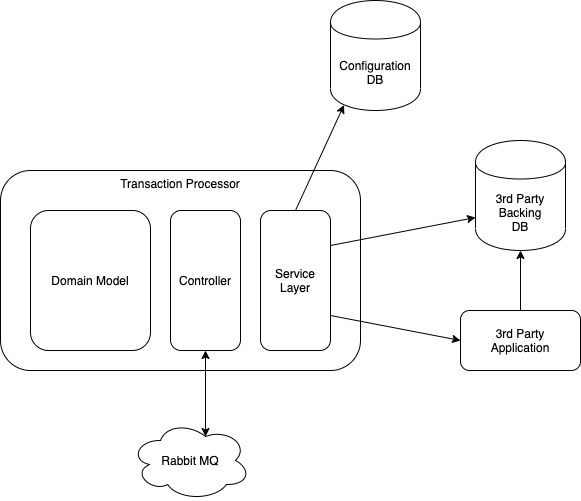
I’ve been helping a JasperFx Software client with their test automation strategy on a new web application and surrounding suite of services. That makes this a perfectly good time to reevaluate how I think teams can succeed with automated testing as an update to what I thought a decade ago. I think you can justifiably describe this post as a stream of consciousness brain dump with just a modicum of editing.
Psych, it took me about four months to actually finish this post, but they’re doing fine as is!
First off, let’s talk about the desirable qualities of a successful test automation strategy.
- The backing automated test suite gives you enough confidence to know when your code can be shipped. Mind you, this isn’t about 100% test coverage because that’s rarely practical or cost effective. Instead, this is feeling that there is an acceptably low risk of problems when we deploy if the automated tests are all currently passing. And sorry, I don’t have a hard and fast number to put on that “feeling,” but hopefully you could do so over time by tracking the actual rate of defects from releases.
- It’s mechanically easy enough to write the automated tests for your system that the effort in doing so pays off. To some degree you can improve this equation by purposely choosing development tools that lend themselves to automated testing (like Marten and PostgreSQL!). Otherwise, you can also improve the value of the automated tests through some judicious usage of custom testing harnesses or possibly using BDD tools (like Gherkin, but I’ve also had success from time to time with old FIT/FitNesse style testing or even just some one off internal DSL tools) that might make the tests be more declarative.
- The automated tests run fast enough to give us an effective feedback cycle — but that’s admittedly 100% subjective. If the tests are too slow, folks won’t run them often enough for the tests to be perfectly helpful and the tests will tend to drift apart from the code. In an ideal world, the tests are running often enough that regression test failures are caught at nearly the same time as the code change that introduced the regression so your teams have an easier time diagnosing the regression problems.
- The automated tests are reliable, just meaning that there’s little to no flakiness and you can generally trust the test results as really being a success or failure. User interface testing or any testing involving asynchronous processes are notoriously hard to do reliably, and the flakiness can be a very real problem. Given a choice between having technically more test coverage of a system and the existing test suites being more reliable, I will purposely choose to delete flaky tests as a compromise if it’s not feasible to improve or rewrite the flaky tests first.
Now let’s talk about how to get to the qualities above by covering both some squishy people oriented process stuff and hard technical approaches that I think help lead to better results.
The test automation engineers should ideally be just part of the development team. It takes a lot of close collaboration between developers and test automation engineers to make a test automation strategy actually work. Most of the, let’s nicely say, less successful test automation efforts I’ve seen over time have been at least partially caused by insufficient collaboration between developers and test automation engineers.
There’s always been a sizable backlash and general weariness in regards to Agile Software methods (and was from the very beginning as I recall), but one thing early Agile methods like Extreme Programming got absolutely right was an emphasis on self-contained teams where everybody’s goal is to ship software rather than being narrow specialists on separate teams who only worried about writing code or testing or designing. Or as the Lean Development folks told us, look to optimize the whole process of shipping software rather than any one intermediate deliverable or artifact.
In practice, this “optimize the whole” probably means that developers are full participants in the automated testing, whether that’s simply adjusting the system to make testing easier (especially if your shop is going to make any investment into automating tests through the user interface) or getting their hands dirty helping write “socialable” integration tests. “Optimize the whole” to means that it’s absolutely worth developer’s time to help with test automation efforts and to even purposely make changes in the system architecture to facilitate easier testing if that extra work still results in shipping software faster through quicker testing.
Use the fastest feedback cycle that adequately tests whatever it is you’re trying to test. I’m sure many of you have seen some form of the test automation pyramid:

We could have a debate about exactly what mix of “solitary” unit tests to “sociable” integration tests to end to end, or truly black box end to end tests is ideal in any given situation, but I think the guiding rule is what I referred to years ago as Jeremy’s Only Rule of Testing:
Test with the finest grained mechanism that tells you something important
Let’s make this rule more concrete by considering a few cases and how we might go about automating testing.
First, let’s say that we have a business rule that says that attempting to create an overdraft of a banking account where an account isn’t allowed to do that should reject the requested transactions. That’s absolutely worth an integration test of some sort too, but I’d absolutely vote first for pretty isolated unit tests against just the business logic that doesn’t involve any kind of database or user interface.
On the other hand, one of my clients is utilizing GraphQL between their front end React.js components and the backend. In that case where you won’t really know for sure that the GraphQL sent from the TypeScript client works correctly with the .NET backend without some end to end tests — which is what they are doing with Playwright. All the same though, we did come up with a recipe for testing out the GraphQL endpoints in isolation from the HTTP request level down to the database as a way of testing the database wiring. I’d say that these two types of testing are highly complementary, as it also is to test business logic elements within their GraphQL mutations without the database. One point I recommended to these clients is to move toward, or at least add, more granular tests of some sort anytime the end to end tests are being hard to debug in the case of test failures. In more simpler terms, excessive trouble debugging problems is probably an indication that you might need more fine-grained tests.
Before I get out of this section, let’s just pick on Selenium overuse here as the absolute scourge of successful test automation in the wild (my client is going with Playwright for browser testing instead which would have been my recommendation anyway). End to end tests using Selenium to drive a web browser are naturally much slower and often more work to write than more focused white box integration tests or isolated unit tests would be — not to mention frequently much less reliable. For that reason, I’m personally a big fan of using white box integration tests much more than end to end, black box tests. Living in server side .NET, that to me means testing a lot more at the message handler level, or at the HTTP endpoint level (which is what Alba does for JasperFx clients and Wolverine.HTTP itself).
The test automation code should be in the same repository as the application code.
I’m not sure why this would be even remotely controversial, but I’ve frequently seen it both together with the system code and in completely separate repositories.
As a default approach, the test automation code should be written in the same language as the application code — with a preference for the server side language. I think this would be the first place I’d compromise though because there are so many testing tools that are coupled to the JavaScript world, so maybe never mind this one:)
It’s very advantageous for any automated integration tests to be easily executed locally by developers on demand. What I mean by this is that developers can easily take their current development branch, and run any part of the automated test suite on demand against their current code. There’s a couple major advantages when you can do this:
- When tests are broken, and they will be, being able to run the tests locally is a much faster feedback cycle for investigating why the tests are broken that it would be to only be able to run the tests by deploying to a build or test server
- It’s very helpful to be able to use automated tests to jump right into debugger session against the code
- Developers will be much more likely to help keep the tests up to date with the system code if they at least occasionally run the tests themselves
- It’s helpful to use the big end to end tests as a safety net for bigger restructuring work
I’ve seen multiple shops where the end to end tests were written by test automation engineers in a black box manner where the test suites could basically only be executed on centralized test servers and sometimes even only through CI (Continuous Integration) servers. That situation doesn’t seem to ever lead to successful test automation efforts.
Automated tests should be what old colleagues and I called “self-contained” tests. All I mean by this is that I want automated tests to be responsible for setting up the system state for the test within the expression of the test. You want to do this in my opinion for two reasons:
- It will make the tests be much more reliable because you can count on the system being in the exact right state for the test
- Having the system state set up by the test itself hopefully makes it easier to reason about the test itself and how the system state, action, and assertions all relate to each other
As an alternative, think about tests that depend on some kind of external script setting up a database through a shared data set. From experience, I can tell you that’s often very hard to reason about a failing test when you can’t easily see the test inputs.
No shared databases if you can help it. Again, this isn’t something I think should be controversial in the year 2024. You can easily get some horrendous false positives or false negatives from trying to execute automated tests against a shared database. Given even remotely a choice, I want an isolated database for each developer, tester, or formal testing environment to have isolated test data setup. This does put some onus on teams to have effective database scripting automation — but you want that anyway.
My preference these days is to rely hard on technologies that are friendly to being part of integration tests, which usually means some combination of being easy for developers to run locally and being relatively easy to configure or setup expected state in code within test harnesses. One of the reasons Marten exists in the first place was to have a NoSQL type workflow in development while being able to very easily spin up new databases and to quickly tear down database state between automated test runs.
Give a choice — and you won’t always have that choice, so don’t get too excited here — I strongly prefer to use technologies that have a great local development and testing story over “Cloud only” technologies. If you do need to utilize Cloud only technology (Azure Service Bus being a common example of that in my recent experience), you can ameliorate the problems that causes for testing by somehow letting each developer or testing environment get their own namespace or some other kind of resource isolation like prefixed resource names per environment. The point here is that automated testing always goes better when you have predictable system inputs that you can expect to lead to expected outcomes in tests. Using any kind of shared resource can sometimes lead to untrustworthy test results.
Older Writings
I’ve written a lot about automated testing over the years, and this post admittedly overlaps with a lot of previous writing — but it’s also kind of fun to see what has or hasn’t evolved in my own thinking:
- Integration Testing: IHost Lifecycle with NUnit (2021)
- Integration Testing: IHost Lifecycle with xUnit.Net (2021)
- A Brain Dump on Automated Testing (2021)
- Testing effectively — with or without mocks or stubs (2021)
- Using Alba to Test ASP.Net Services (2021)
- Fast Build, Slow Build, and the Testing Pyramid (2020)
- A Small Case Study in Test Automation (and other things) (2020)
- Automated Test Pyramid in our Typical Development Stack (2017)
- Using Mocks or Stubs, Revisited (2016)
- Succeeding with Automated Integration Tests (2015)
- My Opinions on Data Setup for Functional Tests (2013)
- Jeremy’s Only Rule of Testing (2012)
And quite a bit of older stuff I didn’t quite manage to rescue off of Codebetter.com before it went off air:(