As a follow on to my introductory post on the new OSS Jasper messaging framework, here’s an explanation of what’s different about Jasper’s internal approach compared to existing .Net frameworks as well as an argument to why I think it’s a better way.
This is an admittedly long blog post with a lot of background contextual information first. If you’re only here for the “Jasper does crazy stuff with Roslyn” part of it, just skip to the “Special Sauce” section.
In this post, I’m talking about:
- What makes a tool a framework vs. a library
- A discussion about the runtime architecture of current .Net frameworks
- Design challenges for middleware strategies
- Jasper’s “Special Sauce” approach and why I think it’s a new, better way
What do you mean when you say “Framework?”
First off, Jasper is unmistakably and unapologetically a framework and not just a library. What’s the difference? A library is something your code uses to perform tasks, with the assumption being that your application code is in control and the library code is passive. The Marten persistence tool I work on, logging libraries like NLog or log4net are all examples of library projects. Frameworks on the other hand, follow the Hollywood Principle to handle common workflow events and dealing with technical infrastructure while calling your code just for the actual application logic. Besides Jasper, ASP.Net MVC, NancyFx, or MediatR in the .Net world or Angular.js or Ember.js in the JS world are examples of frameworks (I personally don’t think it’s a clear cut distinction for React on whether or not it’s a framework or a library).
In the case of Jasper, in the process of handling an incoming message it:
- Logs the arrival of the message
- Determines from the raw message byte[] array what .Net message type it represents and what deserialization strategy it should use
- Deserializes the raw data into an actual .Net object that the application code expects
- Calls any configured middleware for that message type, before finally passing the message to all of the known application handlers for that message type
- Dispose any IDisposable objects that were created during the message processing
- Finally, logs the completion, successful or not, and sends out any outgoing messages that “cascaded” from handling the original message if it’s successful
- If a message fails, process error handling policies to either retry the message, put it back on the queue, stick it into the dead letter queue, or retry it after a delay.
Using Jasper as your messaging framework allows you to focus on just the work that’s specific to your application and let Jasper handle the tedious chores.
The State of the Art in .Net
When a messaging framework needs to process an incoming command or an HTTP framework handles an HTTP request, the common steps are something like this:
- Route the incoming data to the proper HTTP route or message type handler
- Translate the incoming data to the form that the application handler needs to consume (a message type or a DTO type passed into an HTTP request handler)
- Build or find the application specific message or HTTP handlers, along with any other related services
- Call the application specific handlers
- After the message or HTTP request is complete, do any necessary clean up by disposing services that were created for the request. Stuff like closing and disposing open connections to the database used in handling the message or request.
For right now, let’s focus on 3.) and 4.) up above. We need some way to both discover message handlers or HTTP controllers in the application code and then to execute those handlers or controllers at runtime. I’ve seen and used two different general mechanisms to tackle these issues. The first is to require framework developers to write all their message handlers with some kind of standard interface like this one below:
public interface IHandler
{
Task Process(T message, Context context);
}
It’s simple to understand, and makes a lot of the underlying mechanics in your framework easier. This strategy is also easy to combine with an IoC container to handle by handler discovery with something like StructureMap’s ConnectImplementationsToTypesClosing type scanning convention. Likewise, using an IoC tool makes object creation, scoping, and cleanup relatively simple. It does have the downside of being a little bit intrusive into application code and it’s not quite as flexible as the next alternative.
The other way to call application code is to use some sort of Reflection to dynamically call handlers. This has the advantage of greater flexibility in how the application specific handlers can be created and possibly reducing coupling from the application specific code to the framework infrastructure. ASP.Net MVC is an example of this approach, as was the earlier FubuMVC project I led earlier. The FubuMVC “hello world” endpoint that would just return text as “string/plain” when the “/” route is called looked like this:
public class HomeEndpoint
{
public string Index()
{
return "Hello, world.";
}
}
The advantage here is that the code can be subjectively “cleaner,” by which I mean to be an absence of framework artifacts like marker interfaces, mandatory base classes, fluent interfaces, or mandatory attributes. This approach by necessity depends on naming conventions that are frequently derided as “magic” by some folks and when used well, praised as “clean” code by people like me. There’s room in the world for both types of folks.
Another significant advantage is being able to be flexible on the method signatures and even use techniques like “method injection” as ASP.Net Core MVC supports with its [FromServices] attribute in this sample below:
public IActionResult About([FromServices] IDateTime dateTime)
{
ViewData["Message"] = "Currently on the server the time is " + dateTime.Now;
return View();
}
From a technical perspective, the challenge is in how you invoke the application handlers if there is no mandatory interface or base class. Traditionally, your options are:
- Just use Reflection. It’s slow, but it’s the simplest to use
- Emit dynamic assemblies with IL at runtime. The early versions of StructureMap used that, and I thought it was excruciating. It’s laborious to code and not very approachable for other contributors to your project. I think you get serious neckbeard points for using this successfully.
- Use .Net Expressions to dynamically generate and compile Lambda’s. StructureMap does this, and I’m guessing that most other .Net IoC tools do as well. AutoMapper does as well. This model is more approachable than IL, but it’s still not something that most .Net developers can — or would want to — use productively. It also creates horrendously awful stack traces in exception messages. If you do use this technique, definitely check out FastExpressionCompiler.
What about middleware?
By this point, any .Net framework worth its salt is going to support what I used to call the Russian Doll Model of nested handlers with something like ASP.Net Core’s (or OWIN’s) concept of middleware. The purpose is to allow developers to move common, cross-cutting concerns like exception handling, validation, or security to middleware and out of each individual message handler or HTTP controller method. Used judiciously, this can make application code simpler and more robust by simply having fewer things for developers to remember to do. Used badly — and trust me, I’ve seen it used horrendously with my very own FubuMVC “behaviors” model — copious usage of middleware will make your application sluggish, potentially hard to understand, and devilishly hard to debug.
One of the common usages of middleware is to manage transactional boundaries between one or more nested handlers like my shop did several years ago in this post with FubuMVC and RavenDb. A sequence diagram of a typical framework’s internal runtime workflow would look something like this:
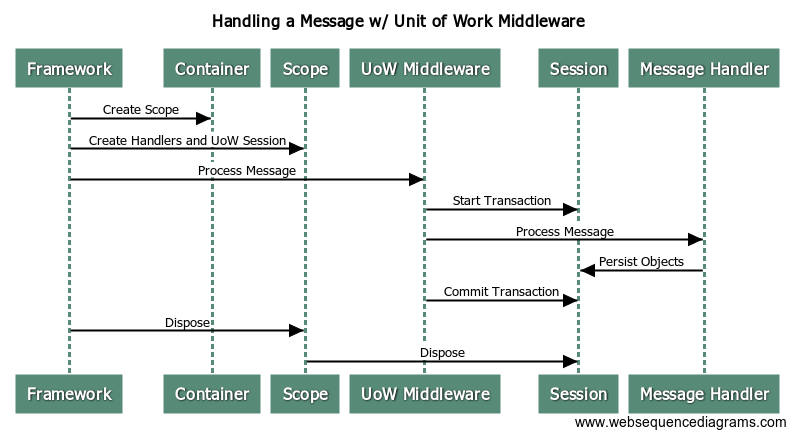
Most .Net frameworks that I’m aware of will use a scope (nested container in StructureMap parlance, IServiceScope in ASP.Net Core, LifetimeScope in Autofac) per message or HTTP request. Using a container scope allows the framework to easily control the scoping of services like a Marten IDocumentSession or an EF DbContext that should be shared by all other services participating in the logical transaction. The container scope usage also allows the framework to clean up resources by calling Dispose() on all the IDisposable objects created during the processing of the message.
As a framework author and as a user of a framework, you’ve got a couple challenges with middleware:
- Understanding what middleware is applicable to each message type or HTTP route. Sooner or later, it’s going to be necessary to visualize the layers of middleware to debug some problem or other
- Properly scoping services that are shared between different middleware or the message handlers. ASP.Net Core does this by sharing the container scope as part of the HttpContext and doing a lot of service location at different places in the runtime. FubuMVC and some versions of NServiceBus build the middleware objects and the handlers wrapped inside of them per HTTP request or message being processed. I can tell you from experience helping folks using StructureMap to write ASP.Net Core middleware that their approach can be problematic. The FubuMVC approach was sluggish and did way too many object allocations in memory.
- The stack traces can be epically bad and noisy, making developer troubleshooting more difficult than it should be
- Hopefully, the container scope and handler object creation isn’t that expensive, but it’s still object allocations that could be potentially eliminated
Jasper’s Special Sauce
Jasper was largely conceived as a next generation replacement for the earlier FubuMVC framework, and takes a lot of lessons and bias — both positive and negative — from our usage of FubuMVC over the past decade. Roughly speaking, we wanted to support a superset of the message handler signatures (and HTTP endpoint signatures too, but that’s a subject for another day), with the addition of support for method injection of dependencies and support for static methods or classes as well for perfectly stateless handlers. We also wanted to keep roughly the same kind of compose-ability with per message type middleware we had with FubuMVC, but this time be able to provide much more visibility to how the middleware was composed at runtime for easier debugging. At the same time, we knew that FubuMVC suffered from performance problems from the sheer number of objects it created and destroyed in its runtime pipeline. For my personal sanity, I knew that we needed to make the exception stack traces coming out of Jasper have a lot less noise.
Very early on, we theorized that we could heavily use the forthcoming runtime code generation and compilation capability in Roslyn to write the tightest possible “glue” code at runtime that handles the intermediation between the Jasper framework, the associated middleware, and the application handlers.
The actual message handlers activated and executed by Jasper’s internal pipeline all inherit from this base class:
public abstract class MessageHandler
{
// Error handling policies for the message type
// and other configuration kind of things that
// the Handle method might need
public HandlerChain Chain { get; set; }
// This method actually processes the incoming Envelope
public abstract Task Handle(IInvocationContext input);
}
Removing the actual middleware noise cleaned up the exception stack traces dramatically. Surfacing the generated code up to users serves as a cheap, but effective visualization of what’s going on internally for developers. Finally, we were sure that this strategy would greatly improve our performance by drastically reducing memory allocations and method delegations in our internals. And wouldn’t you know it, the NServiceBus team who had earlier borrowed FubuMVC’s “Behavior” model, made the same kind of change to using generated code (but with Expression’s) and reported an absurd improvement in their measured performance. Jasper uses a similar approach to NServiceBus 6, but I think we go much farther and that our code generation model will be much more approachable to outsiders than having to deal with Expressions.
In the next section I’ll show what the code generation does, and talk about how to write the fastest possible code with Jasper.
Sample Messaging Scenario
To see the code generation in action, let’s say that we need to handle a CreateItemCommand message, and save a corresponding ItemCreatedEvent document using Marten as our backing store.
The command and event objects look like this:
public class CreateItemCommand
{
public string Name { get; set; }
}
public class ItemCreatedEvent
{
public Item Item { get; set; }
}
In its crudest form, the message handler in Jasper using a traditional class instance that takes all of its dependencies in via constructor injection:
public class CreateItemHandler
{
private readonly IDocumentStore _store;
// store is the Marten IDocumentStore
public CreateItemHandler(IDocumentStore store)
{
_store = store;
}
public async Task Handle(CreateItemCommand command)
{
using (var session = _store.LightweightSession())
{
var item = new Item {Name = command.Name};
session.Store(item);
await session.SaveChangesAsync();
}
}
}
At runtime, Jasper will generate this code for the actual MessageHandler:
public class ShowHandler_CreateItemCommand : Jasper.Bus.Model.MessageHandler
{
private readonly IDocumentStore _documentStore;
public ShowHandler_CreateItemCommand(IDocumentStore documentStore)
{
_documentStore = documentStore;
}
public override Task Handle(Jasper.Bus.Runtime.Invocation.IInvocationContext context)
{
var createItemHandler
= new ShowHandler.CreateItemHandler(_documentStore);
var createItemCommand = (ShowHandler.CreateItemCommand)context.Envelope.Message;
return createItemHandler.Handle(createItemCommand);
}
}
Notice anything missing here from the “typical” framework pipeline I talked about in previous sections? That missing thing is any trace whatsoever of an IoC container at runtime. It turns out that the very fastest IoC container for object resolution is no container. With that in mind, any time that Jasper can figure out from the underlying service registrations how to do all the object construction and disposal per message inside of the generated Handle() method, it will not use the IoC container whatsoever. While there are plenty of cases that Jasper can’t quite handle yet and has to resort to generate code that does service location, we’re working very hard to close those gaps.
There’s a couple other things to note in the code up above:
- The MessageHandler objects are compiled and created at runtime, and they are singleton scoped inside the application
- The IDocumentStore dependency is known to be a singleton in the service registrations, so it is injected into the MessageHandler during its construction so there doesn’t have to be any kind of service lookup for that at runtime
Jasper can also support method injection of service dependencies in the message handler actions, so we could just pull in IDocumentStore as a method argument and simplify the code a little bit. Once you do that though, the ShowHandler class is entirely stateless, so let’s go a little bit farther and just make ShowHandler a static class like so:
public static class CreateItemHandler
{
public static async Task Handle(CreateItemCommand command, IDocumentStore store)
{
using (var session = store.LightweightSession())
{
var item = new Item {Name = command.Name};
session.Store(item);
await session.SaveChangesAsync();
}
}
}
Okay, the “static” keyword is a little bit of noise, but we got rid of the private field for the store and the constructor function, so it’s a little bit tighter. Using that handler above will result in Jasper generating this code:
public class ShowHandler_CreateItemCommand : Jasper.Bus.Model.MessageHandler
{
private readonly IDocumentStore _documentStore;
public ShowHandler_CreateItemCommand(IDocumentStore documentStore)
{
_documentStore = documentStore;
}
public override Task Handle(Jasper.Bus.Runtime.Invocation.IInvocationContext context)
{
var createItemCommand = (ShowHandler.CreateItemCommand)context.Envelope.Message;
return ShowHandler.CreateItemHandler.Handle(createItemCommand, _documentStore);
}
}
The key thing up above being that switching to a static method in our message handler means one less object allocation for the message handler objects.
Finally, the one single bit of middleware that we built to prove out this whole strategy just happens to be some Marten transactional support. There are other ways to apply the middleware, but for right now I’ll just decorate the method with a [MartenTransaction] attribute from the Jasper.Marten library to apply that middleware handling around the handler. For fun, let’s even say that the act of handling the command emits a new event message that will be “cascaded” as an outgoing message when the original message has been completely processed. To do that, just return the event from your handler method. If the middleware is handling the call to IDocumentSession.SaveChangesAsync()/RollbackAsync() for me, I can simplify the message handler code in my application down even further to this now:
public class CreateItemHandler
{
[MartenTransaction]
public static ItemCreatedEvent Handle(
CreateItemCommand command,
IDocumentSession session)
{
var item = new Item {Name = command.Name};
session.Store(item);
return new ItemCreatedEvent{Item = item};
}
}
If you notice, we’re able to use a synchronous method signature here instead of being forced to repetitively all return Task.CompletedTask; every which way because Jasper is smart enough to handle those mechanics for us in its code generation. It’s even smart enough to (imperfectly) switch from a method with an “async Task” signature to a method that can return a Task from the last line of code or “Task.CompletedTask.”
The handler above, with the Marten transaction middleware wrapped in, gives us this compiled code:
public class ShowHandler_CreateItemCommand : Jasper.Bus.Model.MessageHandler
{
private readonly IDocumentStore _documentStore;
public ShowHandler_CreateItemCommand(IDocumentStore documentStore)
{
_documentStore = documentStore;
}
public override async Task Handle(Jasper.Bus.Runtime.Invocation.IInvocationContext context)
{
var createItemCommand = (ShowHandler.CreateItemCommand)context.Envelope.Message;
using (var documentSession = _documentStore.OpenSession())
{
var outgoing1 = ShowHandler.CreateItemHandler.Handle(createItemCommand, documentSession);
context.EnqueueCascading(outgoing1);
await documentSession.SaveChangesAsync();
}
}
}
So, yeah, there’s some magic going on with conventions that some folks absolutely hate, but if it’s easy to get at the generated code internally and you can just read and even debug into that, are conventions really that scary anymore?
Our hope is that the code generation model leads to applications written with Jasper being just as performant as purely bespoke code, but with far less effort on the developer’s part. We think that our runtime codegen model gives Jasper the best of all possible worlds by allowing for very clean, flexible code without sacrificing anything in terms of performance.
It’s a ways away, but I’m well underway in the process of ripping the code generation support out into its own library under the BlueMilk moniker and growing that into a streamlined, performant replacement for StructureMap as well. I’ll blog next week about the vision and maybe the timeline for BlueMilk by itself.



{kind=link}