Long story short, several of my colleagues and I are building a new framework for managing asynchronous messaging between .Net services with the codename “Jasper” as a modernized replacement for our existing FubuMVC based messaging infrastructure. Once I get a good couple weeks of downtime during the holidays, I’ll be making the first big public alpha nuget of Jasper and start blogging up a storm about the project, but for right now, here’s this post about Jasper’s intended dynamic subscription model.
As part of our larger effort at work to move toward a microservices architecture, some of us did a big internal presentation last week about the progress so far in our new messaging infrastructure we intend to use next year as we transition to Netstandard2 and all the modern .Net stuff. I went over my time slot before we could talk about our proposal for how we plan to handle publish/subscribe messaging and service discovery. I promised this post in the hopes of getting some feedback.
The Basic Architecture
Inside of our applications, when we need to publish or send a message to other systems, we would use some code like this:
public Task SendMessage(IServiceBus bus)
{
// In this case, we're sending an "InvoiceCreated"
// message
var @event = new InvoiceCreated
{
Time = DateTime.UtcNow,
Purchaser = "Guy Fieri",
Amount = 112.34,
Item = "Cookbook"
};
// Mandatory that there is subscribers for this message
return bus.Send(@event);
// or send the message to any subscribers for this type
// of message, but don't enforce the existence of any
// subscribers
return bus.Publish(@event);
}
The system publishing messages itself doesn’t need to know or even how to send that message to whatever the downstream system is. The infrastructure code underneath bus.Send() knows how to look up any registered subscribers for the “InvoiceCreated” event message in some kind of subscription storage and route the message accordingly.
The basic architecture is shown below:
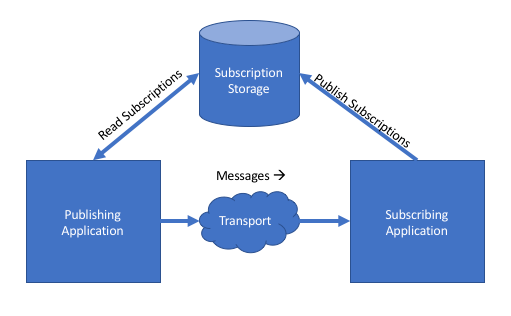
Just to make this clear, there’s no technical reason why the “subscription storage” has to be a shared resource — and therefore a single point of failure — between the systems.
Now that we’ve got the barebones basics, here are the underlying problems we’re trying to solve to make that diagram above work in real life.
The Problem Statement
Consider a fairly large scale technical ecosystem composed of many services that need to work together by exchanging messages in an asynchronous manner. You’ve got a couple challenges to consider:
- How do the various applications “know” where and how to send or publish messages?
- How do you account for the potential change in message payloads or representations between systems?
- How could you create a living document that accurately describes how information flows between the systems?
- How can you add new systems that need to publish or receive messages without having to do intrusive work on the existing systems to accomodate the new system?
- How might you detect mismatches in capabilities between all the systems without having to just let things blow up in production?
Before I lay out our working theory about how we’ll do all of the above in our development next year, let’s talk about the downsides of doing all of that very badly. When I was still wet behind the ears as a developer, I worked at a very large manufacturing company (one of the “most admired” companies in the US at the time) that had an absolutely wretched “n-squared” problem where integration between lots of applications was done in an ad hoc manner with more or less hard coded, one off mechanisms between applications. Every time we needed a new integration, we had to effectively do all new work and break into all of the applications involved in the new data exchange.
I survived that experience with plenty of scars and I’m sure many of you have similar experiences. To solve this problem going forward, my shop has come up with the “dynamic subscription” model (the docs in that link are a bit out of date) in our forthcoming “Jasper” messaging framework.
Our Proposed Goals and Approach
A lot of this is already built out today, but it’s not in production yet and now’s a perfect time for feedback (hint, hint colleagues of mine). The primary goals in the Jasper approach is to:
- Eliminate any need for a central broker or any other kind of single point of failure
- Reduce direct coupling and between services
- Make it easy to update, browse, or delete subscriptions
- Provide tooling to validate the subscriptions across services
- Allow developers to quickly visualize how messages flow in our ecosystem between senders and receivers
Now, to put this into action. First, each application should declare the messages it needs to subscribe to with code like this:
public class MyAppRegistry : JasperRegistry
{
public MyAppRegistry()
{
// Override where you want the incoming messages
// to be sent.
Subscribe.At("tcp://server1:2222");
// Declare which messages this system wants to
// receive
Subscribe.To();
Subscribe.To();
}
}
Note: the “JasperRegistry” type fulfills the same role for configuring a Jasper application as the WebHostBuilder and Startup classes do in ASP.Net Core applications.
When the application configured by the “MyAppRegistry” shown above is bootstrapped, it calculates its subscription requirements that include:
- The logical name of the message type. By default this is derived from the .Net type, but doesn’t have to be. We use the logical name to avoid forcing you to share an assembly with the DTO message types
- All of the representations of the message type that this application understands and can accept. This is done to enable version messaging between our applications and to enable alternative serialization or even custom reading/writing strategies later
- The server address where the upstream applications should send the messages. We’re envisioning that this address will be the load balancer address when we’re hosting on premises in a single data center, or left blank for when we get to jump to cloud hosting when we’ll do some additional work to figure out the network address of the subscriber that’s most appropriate within the data center where the sender is hosted.
At deployment time, whenever a service is going to be updated, our theory is that you’ll have a step in your deployment process that will publish the subscription requirements to the proper subscription storage. If you’re using the built in command line support, and your Jasper application compiles to an executable called “MyApp.exe,” you could use this command line signature to publish subscriptions:
MyApp.exe subscriptions publish
At this point, we’re working under the assumption that we’ll be primarily using Consul as our subscription storage mechanism, but we also have a Postgresql-backed option as well. We think that Consul is a good fit here because of the way that it won’t create a single point of failure while also allowing us to replicate the subscription information between nodes through its own gossip protocol.
Validating Subscriptions
To take this capability farther, Jasper will allow you to declare what messages are published by a system like so:
public class MyAppRegistry : JasperRegistry
{
public MyAppRegistry()
{
Publish.Message();
Publish.Message();
Publish.Message();
}
}
Note: You can also use an attribute directly on the published message types if you prefer, or use a convention for the braver.
When a Jasper application starts up, it combines the declaration of published message types with the known representations or message versions found in the system, and combines that information with the subscription requirements into what Jasper calls the “ServiceCapabilities” model (think of this as Swagger for Jasper messaging, or OpenAPI just in case Darrel Miller ever reads this;)).
Again, if your Jasper application compiles through dotnet publish to a file called “MyApp.exe”, you’ll get a couple more command line functions. First, to dump a JSON representation of the service to a file system folder, you can do this:
MyApp.exe subscriptions export --directory ~/subscriptions
My thinking here was that you could have a Git repository where all the services export their service capabilities at deployment time, because, that would enable you to use this command later:
MyApp.exe subscriptions validate --file subscription-report.json
The command above would read in all the service capability files in that directory, and analyze all the known message publishing and subscriptions to create a report with:
- All the valid message routes from sender to receiver by message type, the address of the receiver, and the representation or version of the message
- Any message types that are subscribed to, but not published by any service
- Message types that are published by one or more services, but not subscribed to by any other system
- Invalid message routing through mismatches in either accepted or published versions or transport mismatches (like if the sender can send messages only through TCP, but the receiver can only receive via HTTP)
Future Work
I thought we were basically done with this feature, but it’s not in production yet and we did come up with some additional items or changes before we go live:
- Build a subscription control panel that’ll be a web front end that allows you to analyze or even edit subscriptions in the subscription storage
- Publish the full service capabilities to the subscription storage (we only publish the subscriptions today)
- Get a bit more intelligent with Consul and how we would use message routing if running nodes of the named services are hosted in different data centers
- Create the idea of message “ownership,” as in “only this system should be processing this command message type”
- Some kind of cache busting in the running Jasper nodes to refresh the subscription information in memory whenever the subscription storage changes