I saw someone on Twitter today asking to hear how Wolverine differs from MediatR. First off, Wolverine is a much bigger, more ambitious tool than MediatR is trying to be and covers far more use cases. Secondly though, Wolverine’s middleware strategy has some significant advantages over the equivalent strategies in other .NET tools.
Wolverine got its 1.0 release yesterday and I’m hoping that gives the tool a lot more visibility and earns it some usage over the next year. Today I wanted to show how the internal runtime model in general and specifically Wolverine’s approach to middleware is quite different than other .NET tools — and certainly try to sell you on why I think Wolverine’s approach is valuable.
For the “too long, didn’t read” crowd, the Wolverine middleware approach has these advantages over other similar .NET tools:
- Potentially more efficient at runtime. Fewer object allocations, less dictionary lookups, and just a lot less runtime logic in general
- Able to be more selectively applied on a message by message or HTTP endpoint by endpoint basis
- Can show you the exact code that explains exactly what middleware is applied and how it’s used on each individual message or HTTP route
For now, let’s consider the common case of wanting to use Fluent Validation to validate HTTP inputs to web service endpoints. If the validation is successful, continue processing, but if the validation fails, use the ProblemDetails specification to instead return a response denoting the validation errors and a status code of 400 to denote an invalid request.
To do that with Wolverine, first start with an HTTP web service project and add a reference to the WolverineFx.Http.FluentValidation Nuget. When you’re configuring Wolverine HTTP endpoints, add this single line to your application bootstrapping code (follow a sample usage here):
app.MapWolverineEndpoints(opts =>
{
// more configuration for HTTP...
// Opting into the Fluent Validation middleware from
// Wolverine.Http.FluentValidation
opts.UseFluentValidationProblemDetailMiddleware();
});
The code above also adds some automatic discovery of Fluent Validation validators and registration into your application’s IoC container, but with a little twist as Wolverine is guessing at the desired IoC lifetime to try to make some runtime optimizations (i.e., a validator type that has no constructor arguments is assumed to be stateless so it doesn’t have to be recreated between requests).
And now for a simple endpoint, some request models, and Fluent Validation validator types to test this out:
public class ValidatedEndpoint
{
[WolverinePost("/validate/customer")]
public static string Post(CreateCustomer customer)
{
return "Got a new customer";
}
[WolverinePost("/validate/user")]
public static string Post(CreateUser user)
{
return "Got a new user";
}
}
public record CreateCustomer
(
string FirstName,
string LastName,
string PostalCode
)
{
public class CreateCustomerValidator : AbstractValidator<CreateCustomer>
{
public CreateCustomerValidator()
{
RuleFor(x => x.FirstName).NotNull();
RuleFor(x => x.LastName).NotNull();
RuleFor(x => x.PostalCode).NotNull();
}
}
}
public record CreateUser
(
string FirstName,
string LastName,
string PostalCode,
string Password
)
{
public class CreateUserValidator : AbstractValidator<CreateUser>
{
public CreateUserValidator()
{
RuleFor(x => x.FirstName).NotNull();
RuleFor(x => x.LastName).NotNull();
RuleFor(x => x.PostalCode).NotNull();
}
}
public class PasswordValidator : AbstractValidator<CreateUser>
{
public PasswordValidator()
{
RuleFor(x => x.Password).Length(8);
}
}
}
And with that, let’s check out our functionality with these unit tests from the Wolverine codebase itself that uses Alba to test ASP.Net Core endpoints in memory:
[Fact]
public async Task one_validator_happy_path()
{
var createCustomer = new CreateCustomer("Creed", "Humphrey", "11111");
// Succeeds w/ a 200
var result = await Scenario(x =>
{
x.Post.Json(createCustomer).ToUrl("/validate/customer");
x.ContentTypeShouldBe("text/plain");
});
}
[Fact]
public async Task one_validator_sad_path()
{
var createCustomer = new CreateCustomer(null, "Humphrey", "11111");
var results = await Scenario(x =>
{
x.Post.Json(createCustomer).ToUrl("/validate/customer");
x.ContentTypeShouldBe("application/problem+json");
x.StatusCodeShouldBe(400);
});
// Just proving that we have ProblemDetails content
// in the request
var problems = results.ReadAsJson<ProblemDetails>();
}
So what that unit test proves, is that the middleware is happily applying the Fluent Validation validators before the main request handler, and aborting the request handling with a ProblemDetails response if there are any validation failures.
At this point, an experienced .NET web developer is saying “so what, I can do this with [other .NET tool] today” — and you’d be right. Before I dive into what Wolverine does differently that makes its middleware both more efficient and potentially easier to understand, let’s take a detour into some value that Wolverine adds that other similar .NET tools cannot match.
Automatic OpenAPI Configuration FTW!
Of course we live in a world where there’s a reasonable expectation that HTTP web services today will be well described by OpenAPI metadata, and the potential usage of a ProblemDetails response should be reflected in that metadata. Not to worry though, because Wolverine’s middleware infrastructure is also able to add OpenAPI metadata automatically as a nice bonus. Here’s a screenshot of the Swashbuckle visualization of the OpenAPI metadata for the /validate/customer endpoint from earlier:

Just so you’re keeping score, I’m not aware of any other ASP.Net Core tool that can derive OpenAPI metadata as part of its middleware strategy
But there’s too much magic!
So there’s some working code that auto-magically applies middleware to your HTTP endpoint code through some type matching, assembly discovery, conventions, and ZOMG there’s magic in there! How will I ever possibly unwind any of this or understand what Wolverine is doing?
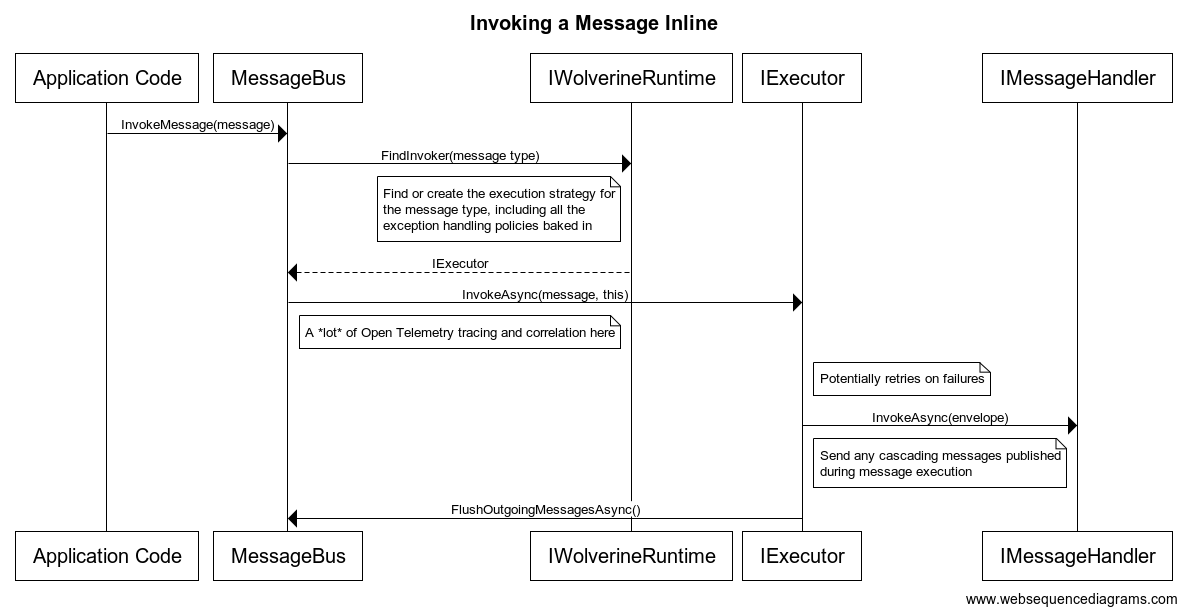
Wolverine’s runtime model depends on generating code to be the “glue” between your code, any middleware usage, and Wolverine or ASP.Net Core itself. There are other advantages to that model, but a big one is that Wolverine can reveal and to some degree even explain what it’s going at runtime through the generated code.
For the /validate/customer endpoint shown earlier with the Fluent Validation middleware applied, here’s the code that Wolverine generates (after a quick IDE reformatting to make it less ugly):
public class POST_validate_customer : Wolverine.Http.HttpHandler
{
private readonly WolverineHttpOptions _options;
private readonly IValidator<CreateCustomer> _validator;
private readonly IProblemDetailSource<CreateCustomer> _problemDetailSource;
public POST_validate_customer(WolverineHttpOptions options, IValidator<CreateCustomer> validator, ProblemDetailSource<CreateCustomer> problemDetailSource) : base(options)
{
_options = options;
_validator = validator;
_problemDetailSource = problemDetailSource;
}
public override async Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
var (customer, jsonContinue) = await ReadJsonAsync<CreateCustomer>(httpContext);
if (jsonContinue == Wolverine.HandlerContinuation.Stop) return;
var result = await FluentValidationHttpExecutor.ExecuteOne<CreateCustomer>(_validator, _problemDetailSource, customer).ConfigureAwait(false);
if (!(result is WolverineContinue))
{
await result.ExecuteAsync(httpContext).ConfigureAwait(false);
return;
}
var result_of_Post = ValidatedEndpoint.Post(customer);
await WriteString(httpContext, result_of_Post);
}
}
The code above will clearly show you the exact ordering and usage of any middleware. In the case of the Fluent Validation middleware, Wolverine is able to alter the code generation a little for:
- With no matching
IValidatorstrategies registered for the request model (CreateCustomerorCreateUserfor examples), the Fluent Validation middleware is not applied at all - With one
IValidator, you see the code above - With multiple
IValidatorstrategies for a request type, Wolverine generates slightly more complicated code to iterate through the strategies and combine the validation results
Some other significant points about that ugly, generated code up above:
- That object is only created once and directly tied to the ASP.Net Core route at runtime
- When that HTTP route is executed, there’s no usage of an IoC container whatsoever at runtime because the exact execution is set in the generated code with all the necessary references already made
- This runtime strategy leads to fewer object allocations, dictionary lookups, and service location calls than the equivalent functionality in other popular .NET tools which will lead to better performance and scalability