If you’re planning on coming to my workshop, you’ll want .NET 8, Git, and some kind of Docker Desktop on your box to run the sample code I’ll use in the workshop. If Docker doesn’t work for you, you maybe want a local install of PostgreSQL and Rabbit MQ.
Hey folks, I’ll be giving the first ever workshop on building an Event Driven Architecture with the full “Critter Stack” at DevUp 2024 in St. Louis next week on Wednesday the 14th bright and early at 8:30 AM.
We’ll be working through a sample backend web service that also communicates with other headless services using Event Sourcing within a general CQRS architectural approach with the whole “Critter Stack. We’ll use Marten (over PostgreSQL) for our persistence strategy using both its event sourcing support and as a document database. We’ll combine that with Wolverine as a server side framework for background processing, asynchronous messaging, and even as an alternative HTTP endpoint framework. Lastly, just for fun, there’ll be guest appearances from other JasperFx tools like Alba and Oakton for automated integration testing and command line execution respectively.
So why would you want to come to this and what might you get out of it? I’m hoping the takeaways — even if you don’t intend to use Marten or Wolverine — will be:
A good introduction to event sourcing as a technical approach and some of the real challenges you’ll face when building a system using event sourcing as a persistence strategy
An understanding of what goes into building a robust CQRS system including dealing with transient errors, observability, concurrency, and how to best segment message processing to achieve self-healing systems
Challenging the industry conventional wisdom about the efficacy of Hexagonal/Clean/Onion Architecture approaches really are when I show what a very low ceremony “vertical slice architecture” approach can be like with the Wolverine + Marten combination while still being robust, observable, highly testable, and still keeping infrastructure concerns out of the business logic
Some exposure to Open Telemetry and general observability tooling for distributed systems you absolutely want if you don’t already have that
Techniques for automating integration tests against an Event Driven Architecture
Because I’m absolutely in the business of promoting the “Critter Stack” tools, I’ll try to convince you that:
Marten is already the most robust and feature rich solution for event sourcing in the .NET ecosystem while also being arguably the easiest to get up and going with
How the Wolverine + Marten combination makes CQRS with Event Sourcing a much easier architectural pattern to use
Wolverine’s emphasis on low ceremony code approaches can help systems be more successfully maintained over time by simply having much less noise code and layering in your systems while still being robust
The “Critter Stack” has an excellent story for automated integration testing support that can do a lot to make your development efforts more successful
Both Marten & Wolverine can help your teams achieve a low “time to first pull request” by doing a lot to configure necessary infrastructure like databases or message brokers on the fly for a better development experience
I’m excited, because this is my first opportunity to do a workshop on the “Critter Stack” tools, and I think we’ve got a very compelling technical story to tell about the tools! And if nothing else, I’m looking forward to any feedback that might help us improve the tools down the line.
And for any *ahem* older folks from St. Louis in my talk, I personally at the time that Jorge Orta was out at first and the Cards should have won that game.
It’s been a little bit since I’ve written any kind of update on the unofficial “Critter Stack” roadmap, with the last update in February. A ton of new, important strategic features have been added to especially Marten since then, with plenty of expansion of Wolverine to boot. Before jumping into what’s to come, let me indulge in a bit of retrospective about what new features or improvements have been delivered in 2024 so far before getting into the road map in the next section.
More parsimonious usage of database connections for better scalability and improved integration with GraphQL via Hot Chocolate
Some ability to do zero down time deployments event with asynchronous projections
Blue/green deployment capabilities for “write” model projections (that’s a big deal)
Ability to add new tenanted databases at runtime for both Marten and Wolverine with zero downtime
There’s only one user so far, but CritterStackPro.Projections is the first paid add on model for Marten & Wolverine that allows for better load distribution of asynchronous projections and event subscriptions within a clustered application
Marten has first class support for strong typed identifiers now — which was a long requested feature that got put off because of how much effort I feared that would require (rightly as it turned out, but it’s all done now)
At this point I feel like we’ve crossed off the mass majority of the features I thought we needed to add to Marten this year to be able to stand Marten up against basically any other event store infrastructure tooling on the whole damn planet. What that also means is that I think that Marten development probably slows down to nothing but bug fixes and community contributions as folks run into things. There are still some features in the backlog that I might personally work on, but that will be in the course of some ongoing and potential JasperFx client work.
That being said, let’s talk about the rest of the year!
The Roadmap for the Back Half of 2024
Obviously, this roadmap is just a snapshot in time and client needs, community requests, and who knows what changes from Microsoft or other related tools could easily change priorities from any of this. All that being said, this is the Critter Stack core team & I’s current vision of the next big steps.
RavenDb integration with Wolverine. This is some client sponsored work that I’m hoping will set Wolverine up for easier integration with other database engines in the near future
“Critter Watch” — an ongoing effort to build out a management and monitoring console application for any combination of Marten, Wolverine, and future critters. This will be a paid product. We’ve already had a huge amount of feedback from Marten & Wolverine users, and I’m personally eager to get this moving in the 3rd quarter
Marten 8.0 and Wolverine 4.0 — the goal here is mostly a rearrangement of dependencies underneath both Marten & Wolverine to eliminate duplication and spin out a lot of the functionality around projections and the async daemon. This will also be a significant effort to spin off some new helper libraries for the “Critter Stack” to enable the next bullet point
“Ermine” — a port of Marten’s event store capabilities and a subset of its document database capabilities to SQL Server. My thought is that this will share a ton of guts with Marten. I’m voting that Ermine will have direct integration with Wolverine from the very beginning as well for subscriptions and middleware similar to the existing Wolverine.Marten integration
If Ermine goes halfway well, I’d love to attempt a CosmosDb and maybe a DynamoDb backed event store in 2025
As usual, that list is a guess and unlikely to ever play out exactly that way. All the same though, there’s my hopes and dreams for the next 6 months or so.
Did I miss something you were hoping for? Does any of that concern you? Let me and the rest of the Critter Stack community know either here or anywhere in our Discord room!
As Houston gets drenched by Hurricane Beryl as I write this, I’m reminded of a formative set of continuing education courses I took when I was living in Houston in the late 90’s and plotting my formal move into software development. Whatever we learned about VB6 in those MSDN classes is long, long since obsolete, but one pithy saying from one of our instructors (who went on to become a Marten user and contributor!) stuck with me all these years later:
His point then, and my point now quite frequently working with JasperFx Software clients, is that round trips between browsers to backend web servers or between application servers and the database need to be treated as expensive operations and some level of request, query, or command batching is often a very valuable optimization in systems design.
Consider my family’s current kitchen predicament as diagrammed above. The very expensive, original refrigerator from our 20 year old house finally gave up the ghost, and we’ve had it completely removed while we wait on a different one to be delivered. Fortunately, we have a second refrigerator in the garage. When cooking now though, it’s suddenly a lot more time consuming to go to the refrigerator for an ingredient since I can’t just turn around and grab something when the kitchen refrigerator was just a step away. Now that we have to walk across the house from the kitchen to the garage to get anything from the other refrigerator, it’s becoming very helpful to try to grab as many things as you can at one time so you’re not constantly running back and forth.
While this issue certainly arises from user interfaces or browser applications making a series of little requests to a backing server, I’m going to focus on database access for the rest of this post. Using a simple example from Marten usage, consider this code where I’m just creating five little documents and persisting them to a database:
public static async Task storing_many(IDocumentSession session)
{
var user1 = new User { FirstName = "Magic", LastName = "Johnson" };
var user2 = new User { FirstName = "James", LastName = "Worthy" };
var user3 = new User { FirstName = "Michael", LastName = "Cooper" };
var user4 = new User { FirstName = "Mychal", LastName = "Thompson" };
var user5 = new User { FirstName = "Kurt", LastName = "Rambis" };
session.Store(user1);
session.Store(user2);
session.Store(user3);
session.Store(user4);
session.Store(user5);
// Marten will *only* make a single database request here that
// bundles up "upsert" statements for all five users added above
await session.SaveChangesAsync();
}
In the code above, Marten is only issuing a single batched command to the backing database that performs all five “upsert” operations in one network round trip. We were very performance conscious in the very early days of Marten development and did quite a bit of experimentation with different options for JSON serialization or how exactly to write SQL that queried inside of JSONB or even table structure. Consistently and unsurprisingly though, the biggest jump in performance was when we introduced command batching to reduce the number of network round trips between code using Marten and the backing PostgreSQL database. That early performance testing also led us to early investments in Marten’s batch querying support and the Include() query functionality that allows Marten users to fetch related data with fewer network hops to the database.
Just based on my own experience, here are two trends I see about interacting with databases in real world systems:
There’s a huge performance gain to be made by finding ways to batch database queries
It’s very common for systems in the real world to suffer from performance problems that can at least partially be traced to unnecessary chattiness between an application and its backing database(s)
At a guess, I think the underlying reasons for the chattiness problem are something like:
Developers who just aren’t aware of the expense of network round trips or aren’t aware of how to utilize any kind of database query batching to reduce the problems
Wrapper abstractions around the raw database persistence tooling that hides more powerful APIs that might alleviate the chattiness problem
Wrapper abstractions that encourage a pattern of only loading data by keys one row/object/document at a time
Wrapper abstractions around the raw database persistence that discourage developers from learning more about the underlying persistence tooling they’re using. Don’t underestimate how common that problem is. And I’ve absolutely been guilty of causing that issue as a younger “architect” in the past who created those abstractions.
Complicated architectural layering that can make it quite difficult to easily reason about the cause and effect between system inputs and the database queries that those inputs spawn. Big call stacks of a controller calling a mediator tool that calls one service that calls other services that call different repository abstractions that all make database queries is a common source of chattiness because it’s hard to even see where all the chattiness is coming from by reading the code.
As you might know if you’ve stumbled across any of my writings or conference talks from the last couple years, I’m not a big fan of typical Clean/Onion Architecture approaches. I think these approaches introduce a lot of ceremony code into the mix that I think causes more harm overall than whatever benefits they bring.
Here’s an example that’s somewhat contrived, but also quite typical in terms of the performance issues I do see in real life systems. Let’s say you’ve got a command handler for a ShipOrder command that will need to access data for both a related Invoice and Order entity that could look something like this:
public class ShipOrderHandler
{
private readonly IInvoiceRepository _invoiceRepository;
private readonly IOrderRepository _orderRepository;
private readonly IUnitOfWork _unitOfWork;
public ShipOrderHandler(
IInvoiceRepository invoiceRepository,
IOrderRepository orderRepository,
IUnitOfWork unitOfWork)
{
_invoiceRepository = invoiceRepository;
_orderRepository = orderRepository;
_unitOfWork = unitOfWork;
}
public async Task Handle(ShipOrder command)
{
// Making one round trip to get an Invoice
var invoice = await _invoiceRepository.LoadAsync(command.InvoiceId);
// Then a second round trip using the results of the first pass
// to get follow up data
var order = await _orderRepository.LoadAsync(invoice.OrderId);
// do some logic that changes the state of one or both of these entities
// Commit the transaction that spans the two entities
await _unitOfWork.SaveChangesAsync();
}
}
The code is pretty simple in this case, but we’re still making more database round trips than we absolutely have to — and real enterprise systems can get much, much bigger than my little contrived example and incur a lot more overhead because of the chattiness problem that the repository abstractions naturally let in.
Let’s try this functionality again, but this time just depending on the raw persistence tooling (Marten’s IDocumentSession and use a Wolverine-style command handler to boot to further reduce the code noise:
public static class ShipOrderHandler
{
// We're still keeping some separation of concerns to separate the infrastructure from the business
// logic, but Wolverine lets us do that just through separate functions instead of having to use
// all the limiting repository abstractions
public static async Task<(Order, Invoice)> LoadAsync(IDocumentSession session, ShipOrder command)
{
// This is important (I think:)), the admittedly complicated
// Marten usage below fetches both the invoice and its related order in a
// single network round trip to the database and can lead to substantially
// better system performance
Order order = null;
var invoice = await session
.Query<Invoice>()
.Include<Order>(i => i.OrderId, o => order = o)
.Where(x => x.Id == command.InvoiceId)
.FirstOrDefaultAsync();
return (order, invoice);
}
public static void Handle(ShipOrder command, Order order, Invoice invoice)
{
// do some logic that changes the state of one or both of these entities
// I'm assuming that Wolverine is handling the transaction boundaries through
// middleware here
}
}
In the second code sample, we’ve been able to go right at the Marten tooling to take advantage of its more advanced functionality to batch up data fetching for better performance that wasn’t easily possible when we were putting repository abstractions between our command handler and the underlying persistence tooling. Moreover, we can even reason about the resulting database operations that are happening as a result of our command that can be somewhat obfuscated by more layers and more code separation as is common in Onion/Clean/Ports and Adapters style approaches.
It’s not just repository abstractions that cause problems, sometimes it’s just happily useful little extension methods that can be the source of chattiness. Here’s a pair of helper extension methods around Marten’s event store functionality that help you start a new event stream in a single line of code or append a single event to an existing event stream in a single line of code:
public static class DocumentSessionExtensions
{
public static Task Add<T>(this IDocumentSession documentSession, Guid id, object @event, CancellationToken ct)
where T : class
{
documentSession.Events.StartStream<T>(id, @event);
return documentSession.SaveChangesAsync(token: ct);
}
public static Task GetAndUpdate<T>(
this IDocumentSession documentSession,
Guid id,
int version,
// If we're being finicky about performance here, these kinds of inline
// lambdas are NOT cheap at runtime and I'm recommending against
// continuation passing style APIs in application hot paths for
// my clients
Func<T, object> handle,
CancellationToken ct
) where T : class =>
documentSession.Events.WriteToAggregate<T>(id, version, stream =>
stream.AppendOne(handle(stream.Aggregate)), ct);
}
Fine, right? These potentially make your code cleaner and simpler but of course, they’re also potentially harmful. Here’s an example of these two extension methods that were similar to some code I saw in the wild last week:
public static class Handler
{
public static async Task Handle(Command command, IDocumentSession session, CancellationToken token)
{
var id = CombGuidIdGeneration.NewGuid();
// One round trip
await session.Add<Aggregate>(id, new FirstEvent(), token);
if (command.SomeCondition)
{
// This actually makes a pair of round trips, one to fetch the current state
// of the Aggregate compiled from the first event appended above, then
// a second to append the SecondEvent
await session.GetAndUpdate<Aggregate>(id, 1, _ => new SecondEvent(), token);
}
}
}
I got involved with this code in reaction to some load testing that was resulting in disappointing results. When I was pulled in, I saw the extra round trips that snuck in because of the usage of the convenience extension methods they had been using, and suggested a change to something like this (but with Wolverine’s aggregate handler workflow that simplified the code more than this):
public static class Handler
{
public static async Task Handle(Command command, IDocumentSession session, CancellationToken token)
{
var events = determineEvents(command).ToArray();
var id = CombGuidIdGeneration.NewGuid();
session.Events.StartStream<Aggregate>(id, events);
await session.SaveChangesAsync(token);
}
// This was isolated so you can easily unit test the business
// logic that "decides" what events to append
public static IEnumerable<object> determineEvents(Command command)
{
yield return new FirstEvent();
if (command.SomeCondition)
{
yield return new SecondEvent();
}
}
}
The code above cut down the number of network round trips to the database and greatly improved the results of the load testing.
Summary
If system performance is a concern in your system (it’s not always), you probably need to be cognizant of how chatty your application is in regards to its communication and interaction with the backing database. Or any other remote system or infrastructure that your system interacts with at runtime.
Personally, I think that higher ceremony code structures make it much more likely to incur issues with database chattiness especially by first obfuscating your code so you don’t even easily recognize where there’s chattiness, then second by wrapping simplifying abstractions around your database persistence tooling that eliminate the usage of more advanced functionality for query batching.
And of course, both Wolverine and Marten put a heavy emphasis on reducing code ceremony and generally on code noise in general because I personally think that’s very valuable to help teams succeed over time with software systems in the wild. My theory of the case is that even at the cost of a little bit of “magic”, simply reducing the amount of code you have to wade through in existing systems will make those systems easier to maintain and troubleshoot over time.
And on that note, I’m basically on vacation for the next week, and you can address your complaints about my harsh criticism of Clean/Onion Architectures to the ether:-)
By the way, JasperFx Software offers support contracts or tailored consulting engagements to help your shop maximize your success with Wolverine.
It’s an unfortunate fact of long running software tooling projects like Wolverine that decisions made years earlier won’t hold up perfectly as the usage requirements, underlying platform, and other tools it’s integrated with change over time. In the case of Wolverine, it’s time for a medium sized 3.0 release to make some potentially breaking API changes and changes to its original model to accommodate some use cases that weren’t part of the original vision.
This is all subject to change based on whatever feedback comes in, but right now I think the items that are absolutely in scope are:
De-coupling Wolverine from Lamar. That work has been unfortunately huge so far, but almost complete as I type this. At a minimum, Wolverine is going to be functional with both the build in ServiceProvider container and still Lamar itself. To a large degree, this was actually a prerequisite for the next bullet point
Get Wolverine completely on the .NET Aspire train. Really just making sure that all the external infrastructure integrations with Wolverine that also have Aspire integrations like PostgreSQL, Sql Server, Rabbit MQ, Azure Service Bus, Kafka, and AWS SQS are able to correctly use the Aspire configuration. That’s really just a matter of using some IoC container integration and not a huge deal. I think that testing and documentation will be more work on that front than the actual development. I know that there are mixed opinions about whether or not Aspire is valuable, but this can’t be a reason why folks won’t consider using Wolverine in the future, so here we go.
Beyond that, I think there are some additive features I just didn’t want to work on right now until the 3.0 work is complete:
An HTTP messaging transport — which I think we really want inside of Wolverine as a precursor to the long planned “Critter Stack Pro” add on tooling. Which also might help enable:
Some improvements for dynamic multi-tenancy where you want to spin up or down tenants in a running application without downtime
Improving the EF Core integration with Wolverine to bring it a bit up to parity with the existing Marten integrations. That would potentially include multi-tenancy support and more middleware and productivity shortcuts for Wolverine
I’d like to completely reconsider our bootstrapping, especially in an application that combines both Marten & Wolverine. I think there’s some room for a customized CritterStackApplicationBuilder or CritterStackWebApplication model. More on this later.
I don’t really want this to be a huge release that takes very long, and I absolutely don’t want this to require very many changes at all for our users to adopt this.
The goal for the “Critter Stack” tools is to be the absolute best set of tools for building server side .NET applications, and especially for any usage of Event Driven Architecture approaches. To go even farther, I would like there to be a day where organizations purposely choose the .NET ecosystem just because of the benefits that the “Critter Stack” provides over other options. But for now, that’s the journey we’re on. This post demonstrates an important new feature that I think fills in a huge capability gap that has long bothered me.
And as always, JasperFx Software is happy to work with any “Critter Stack” users through either support contracts or consulting engagements to help you wring the most value out of our tools and help you succeed with what you’re building.
I recently wrote some posts about the whole “Modular Monolith” architecture approach:
This week I’m helping a JasperFx client who has some complicated multi-tenancy requirements. In one of their services they have some types of event streams that need to use “conjoined multi-tenancy“, but at least one type of event stream (and related aggregate) that is global across all tenants. Marten event stores are either multi-tenanted or they’re not, with no mixing and matching. It occurred to me that we could solve this issue by putting the one type of global event streams in a separate Marten store. Even though the 2nd Marten store will still target the exact same PostgreSQL database (but in a different schema), we can give this second schema a different configuration to accommodate the different tenancy rules. Moreover, this would even be a good way to improve performance and scalability of their service by effectively sharding the events and streams tables (smaller tables generally mean better performance).
At the same time, I’m also helping them introduce Wolverine message handlers as well, and I really wanted to be able to use the aggregate handler workflow for commands that spawn new Marten events (effectively the Critter Stack version of the “Decider” pattern, but lower ceremony). I finally took some time — and stumbled onto a workable approach — that finally adds far better support for modular monolith architectures with the Wolverine 2.13.0 release that hit today.
To see a sneak peek, let’s say that you have two additional Marten stores for your application like these two:
public interface IPlayerStore : IDocumentStore;
public interface IThingStore : IDocumentStore;
You can now bootstrap a Marten + Wolverine application (using the WolverineFx.Marten Nuget dependency) like so:
theHost = await Host.CreateDefaultBuilder()
.UseWolverine(opts =>
{
opts.Services.AddMarten(Servers.PostgresConnectionString).IntegrateWithWolverine();
opts.Policies.AutoApplyTransactions();
opts.Durability.Mode = DurabilityMode.Solo;
opts.Services.AddMartenStore<IPlayerStore>(m =>
{
m.Connection(Servers.PostgresConnectionString);
m.DatabaseSchemaName = "players";
})
// THIS AND BELOW IS WHAT IS NEW FOR WOLVERINE 2.13
.IntegrateWithWolverine()
// Add a subscription
.SubscribeToEvents(new ColorsSubscription())
// Forward events to wolverine handlers
.PublishEventsToWolverine("PlayerEvents", x =>
{
x.PublishEvent<ColorsUpdated>();
});
// Look at that, it even works with Marten multi-tenancy through separate databases!
opts.Services.AddMartenStore<IThingStore>(m =>
{
m.MultiTenantedDatabases(tenancy =>
{
tenancy.AddSingleTenantDatabase(tenant1ConnectionString, "tenant1");
tenancy.AddSingleTenantDatabase(tenant2ConnectionString, "tenant2");
tenancy.AddSingleTenantDatabase(tenant3ConnectionString, "tenant3");
});
m.DatabaseSchemaName = "things";
}).IntegrateWithWolverine(masterDatabaseConnectionString:Servers.PostgresConnectionString);
opts.Services.AddResourceSetupOnStartup();
}).StartAsync();
Now, moving to message handlers or HTTP endpoints, you will have to explicitly tag either the containing class or individual messages with the [MartenStore(store type)] attribute like this simple example below:
// This will use a Marten session from the
// IPlayerStore rather than the main IDocumentStore
[MartenStore(typeof(IPlayerStore))]
public static class PlayerMessageHandler
{
// Using a Marten side effect just like normal
public static IMartenOp Handle(PlayerMessage message)
{
return MartenOps.Store(new Player{Id = message.Id});
}
}
Boom! Even that minor sample is using transactional middleware targeting Marten and able to work with the separate IPlayerStore. This new integration includes:
Transactional outbox support for all configured Marten stores
Transactional middleware
The “aggregate handler workflow”
Marten side effects
Subscriptions to Marten events
Multi-tenancy, both “conjoined” Marten multi-tenancy and multi-tenancy through separate databases
I’m maybe a little too excited for a feature that most users will never touch, but for those who do see this, the “Critter Stack” now has first class modular monolith support across a wide range of the features that make the “Critter Stack” a desirable platform in the first place.
I’m always on the lookout for ideas about how to endlessly promote both Marten & Wolverine. Since I’ve been fielding a lot of questions, issues, and client requests around multi-tenancy support in both tools the past couple weeks, now seems to be a good time for a new series exploring the existing foundation in both critter stack tools for handling quite a few basic to advanced multi-tenancy scenarios. But first, let’s start by just talking about what the phrase “multi-tenancy” even means for architecting software systems.
In the course of building systems, you’re frequently going to have a single system that needs to serve different sets of users or clients. Some examples I’ve run across have been systems that need to segregate data for different partner companies, different regions within the same company, or just flat out different users like online email services do today.
I don’t know the origin of the terminology, but we refer to those logical separations within the system data as “tenants.”
My youngest is very quickly outgrowing Dr. Seuss books, but we still read “Because a Bug went Kachoo!” above
It’s certainly going to be important many times to keep the data accessed through the system segregated so that nobody is able to access data that they should not. For example, I probably shouldn’t be able to read you email inbox when I lot into my gmail account. For another example from my early career, I worked with an early web application system that was used to gather pricing quotes from my very large manufacturing company’s suppliers for a range of parts. Due to a series of unfortunate design decisions (because a bug went kachoo!), that application did a very poor job being able to segregate data, and I figured out that some of our suppliers were able to see the quoted prices from their competitors and get unfair advantages.
So we can all agree that mixing up the data between users who shouldn’t see each other’s data is a bad thing, so what can we do about that? The most extreme solution is to just flat out deploy a completely different set of servers for each segregated group of users as shown below:
While there are some valid reasons once in awhile to do the completely separate deployments, that’s potentially a lot of overhead and extra hosting costs. At best, this is probably only viable for a finite number of deployments (Gmail is certainly not building out a separate web server for every one of us with a Gmail account for example).
When a single deployed system is able to serve different tenants, we call that “multi-tenancy.”
With multi-tenancy, we’re ensuring that one single deployment of the logical service can handle requests for multiple tenants without allowing users from one tenant to inappropriately see data from other tenants.
Roughly speaking, I’m familiar with three different ways to achieve multi-tenancy.
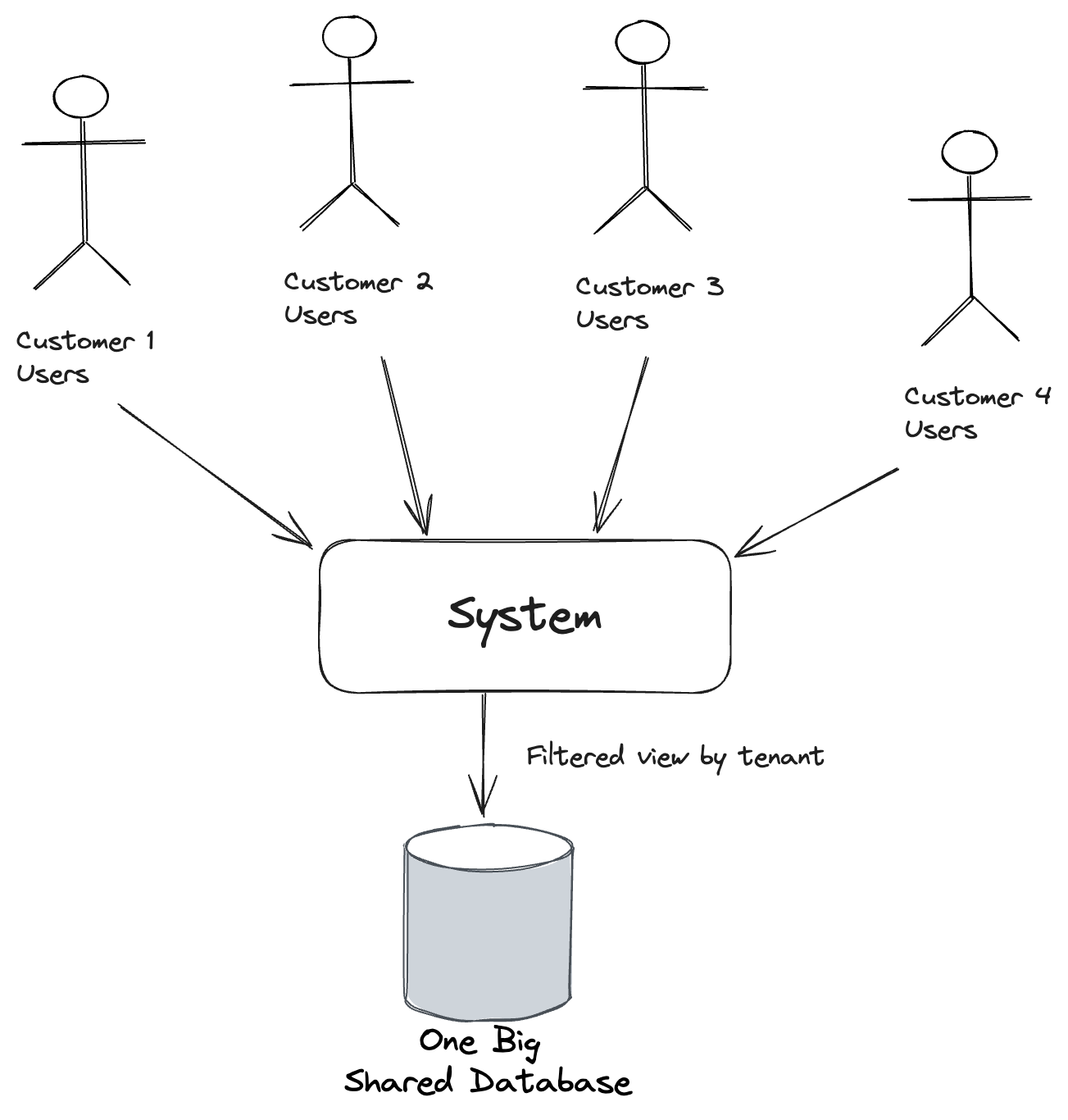
The first approach is to use one database for all tenant data, but to use some sort of tenant id field that just denotes which tenant the data belongs to. This is what I termed “Conjoined Tenancy” in Marten. This approach is simpler in terms of the database deployment and database change management because after all, there’s only one of them! It is potentially more complex within your codebase because your persistence layer will always need to apply filters on the data being modified and accessed by the user and whichever tenant they are part of.
There’s some inherent risk with this approach as developers aren’t perfectly omniscient, and there’s always a chance that we miss some scenarios and let data leak out inappropriately to the wrong users. I think this approach is much more viable when using persistence tooling that has strong support (like Marten!) for this type of “conjoined multi-tenancy” and mostly takes care of the tenancy filters for you.
The second approach is to use a separate schema for each tenant within the same database. I’ve never used this approach myself, and I’m not aware of any tooling in my own .NET ecosystem that supports this approach out of the box. I think this would be a good approach if you were building something on top of a relational database from scratch with a custom data layer — but I think it would be a lot of extra overhead managing the database schema migrations.
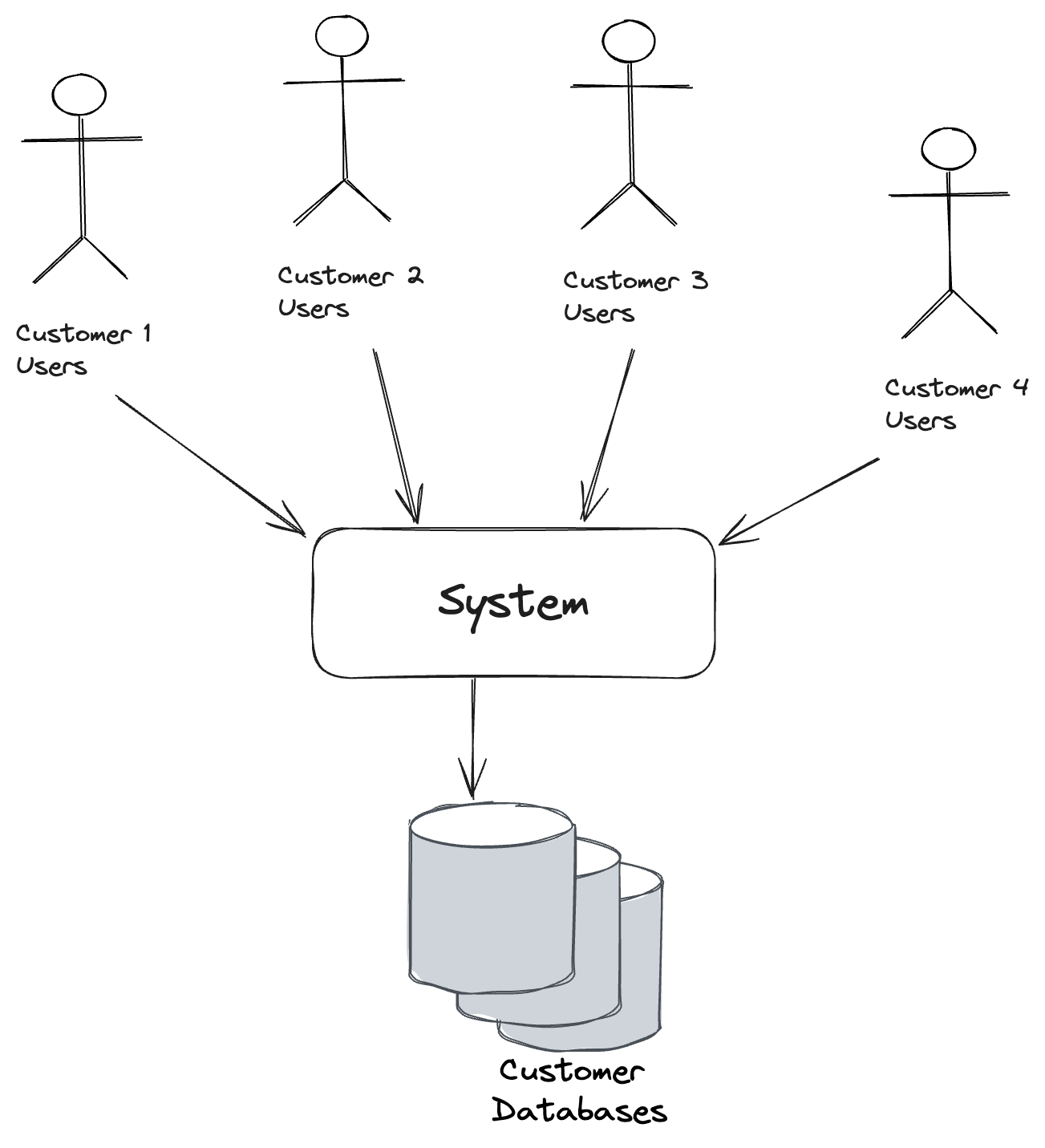
The third way to do multi-tenancy is to use a separate database for each tenant, but the single deployed system is smart enough to connect to the correct database throughout its persistence layer based on the current user (or through metadata on messages as we’ll see in a later entry on Wolverine multi-tenancy). This approach is shown below:
There’s of course some challenges to this approach as well. First off, there’s more databases to worry about, and subsequently more overhead for database migrations and management. This approach does give you rock solid data segregation between tenants, and I’ve heard of strong business or regulatory requirements to take this approach even when the data volume wouldn’t require this. As my last statement hints at, we all know that the system database is very commonly the bottleneck for performance and scalability, so segregating different tenant data into separate databases may be a good way to improve the scalability of your system.
It’s obviously going to be more difficult to do any kind of per-tenant data rollup or summary with the separate database approach, but some cloud providers have specialized infrastructure for per tenant database multi-tenancy.
A Note about Scalability
I was taught very early on that an effective way to scale systems was to design for any given server to be able to handle all the possible types of operations, then add more servers to the horizontal cluster. I think at the time this was in reaction to several systems we had where teams had tried to scale bigger systems by segregating all operations for one region to one set of servers, and a different set of servers for other regions. The end result was an explosion of deployed servers and frequently having servers absolutely pegged on CPU or memory while North America factories were in full swing while the servers tasked with handling factories on the Pacific Rim were completely dormant when their factories were closed. An architecture that can spread all the work across the cluster of running nodes might often be a much cheaper solution in the end than standing up many more nodes that can only service a subset of tenants.
Then again, you might also want to prioritize some tenants over others, so take everything I just said with a grain of “it depends” salt.
Thar be Dragons!
In the next set of posts, I’ll get into first Marten, then Wolverine capabilities for multi-tenancy, but just know first that there’s a significant set of challenges ahead:
Managing multiple database schemas if using separate databases per tenant
Needing to use per-tenant filters if using the conjoined storage model for query segregation — and trust me as the author of a persistence tool, there’s plenty of edge case dragons here
Detecting the current tenant based on HTTP requests or messaging metadata
Communicating the tenant information when using asynchronous messaging
Querying across tenants
Dynamically spinning up new tenant databases at runtime — or tearing them down! — or even moving them at runtime?!?
Isolated data processing by tenant database
Multi-level tenancy!?! JasperFx helped a customer build this out with Marten
Transactional outbox support in a multi-tenanted work — which Wolverine can do today!
The two “Critter Stack” tools help with most of these challenges today, and I’ll get around to some discussion about future work to help fill in the more advanced usages that some real users are busy running into right now.
I’m working on fixing a reported bug with Wolverine today and its event forwarding from Marten feature. I can’t say that I yet know why this should-be-very-straightforward-and-looks-exactly-like-the-currently-passing-tests bug is happening, but it’s a good time to demonstrate Wolverine’s automated testing support and even how it can help you to understand test failures.
First off, and I’ll admit that there’s some missing context here, I’m setting up a system such that when this message handler is executed:
public record CreateShoppingList();
public static class CreateShoppingListHandler
{
public static string Handle(CreateShoppingList _, IDocumentSession session)
{
var shoppingListId = CombGuidIdGeneration.NewGuid().ToString();
session.Events.StartStream<ShoppingList>(shoppingListId, new ShoppingListCreated(shoppingListId));
return shoppingListId;
}
}
The configured Wolverine + Marten integration should be kicking in to publish the event appended in the handler above to a completely different handler shown below with the Marten IEvent wrapper so that you can use Marten event store metadata within the secondary, cascaded message:
public static class IntegrationHandler
{
public static void Handle(IEvent<ShoppingListCreated> _)
{
// Don't need a body here, and I'll show why not
// next
}
}
Knowing those two things, here’s the test I wrote to reproduce the problem:
[Fact]
public async Task publish_ievent_of_t()
{
// The "Arrange"
using var host = await Host.CreateDefaultBuilder()
.UseWolverine(opts =>
{
opts.Policies.AutoApplyTransactions();
opts.Services.AddMarten(m =>
{
m.Connection(Servers.PostgresConnectionString);
m.DatabaseSchemaName = "forwarding";
m.Events.StreamIdentity = StreamIdentity.AsString;
m.Projections.LiveStreamAggregation<ShoppingList>();
}).UseLightweightSessions()
.IntegrateWithWolverine()
.EventForwardingToWolverine();;
}).StartAsync();
// The "Act". This method is an extension method in Wolverine
// specifically for facilitating integration testing that should
// invoke the given message with Wolverine, then wait until all
// additional "work" is complete
var session = await host.InvokeMessageAndWaitAsync(new CreateShoppingList());
// And finally, just assert that a single message of
// type IEvent<ShoppingListCreated> was executed
session.Executed.SingleMessage<IEvent<ShoppingListCreated>>()
.ShouldNotBeNull();
}
And now, when I run the test — which “helpfully” reproduces reported bug from earlier today — I get this output:
System.Exception: No messages of type Marten.Events.IEvent<MartenTests.Bugs.ShoppingListCreated> were received
System.Exception
No messages of type Marten.Events.IEvent<MartenTests.Bugs.ShoppingListCreated> were received
Activity detected:
----------------------------------------------------------------------------------------------------------------------
| Message Id | Message Type | Time (ms) | Event |
----------------------------------------------------------------------------------------------------------------------
| 018f82a9-166d-4c71-919e-3bcb04a93067 | MartenTests.Bugs.CreateShoppingList | 873| ExecutionStarted |
| 018f82a9-1726-47a6-b657-2a59d0a097cc | System.String | 1057| NoRoutes |
| 018f82a9-17b1-4078-9997-f6117fd25e5c | EventShoppingListCreated | 1242| Sent |
| 018f82a9-166d-4c71-919e-3bcb04a93067 | MartenTests.Bugs.CreateShoppingList | 1243| ExecutionFinished |
| 018f82a9-17b1-4078-9997-f6117fd25e5c | EventShoppingListCreated | 1243| Received |
| 018f82a9-17b1-4078-9997-f6117fd25e5c | EventShoppingListCreated | 1244| NoHandlers |
----------------------------------------------------------------------------------------------------------------------
EDIT: If I’d read this more closely before, I would have noticed that the problem was somewhere different than the routing that I first suspected from a too casual read.
The textual table above is Wolverine telling me what it did do during the failed test. In this case, the output does tip me off that there’s some kind of issue with the internal message routing in Wolverine that should be applying some special rules for IEvent<T> wrappers, but was not in this case. While that work fixing the real bug continues for me, what I hope you get out of this is how Wolverine is trying to help you diagnose test failures by providing diagnostic information about what was actually happening internally during all the asynchronous processing. As a long veteran of test automation efforts, I will vociferously say that it’s important for test automation harnesses to be able to adequately explain the inevitable test failures. Like Wolverine helpfully does.
Now, back to work trying to actually fix the problem…
Wolverine has the ability to schedule the delivery of messages for a later time. While Wolverine certainly isn’t trying to be Hangfire or Quartz.Net, the message scheduling in Wolverine today is valuable for “timeout” messages in sagas, or “retry this evening” type scenarios, or reminders of all sorts.
If using the Azure Service Bus transport, scheduled messages sent to Azure Service Bus queues or topics will use native Azure Service Bus scheduled delivery. For everything else today, Wolverine is doing the scheduled delivery for you. To make those scheduled messages be durable (i.e. not completely lost when the application is shut down), you’re going to want to add message persistence to your Wolverine application as shown in the sample below using SQL Server:
// This is good enough for what we're trying to do
// at the moment
builder.Host.UseWolverine(opts =>
{
// Just normal .NET stuff to get the connection string to our Sql Server database
// for this service
var connectionString = builder.Configuration.GetConnectionString("SqlServer");
// Telling Wolverine to build out message storage with Sql Server at
// this database and using the "wolverine" schema to somewhat segregate the
// wolverine tables away from the rest of the real application
opts.PersistMessagesWithSqlServer(connectionString, "wolverine");
// In one fell swoop, let's tell Wolverine to make *all* local
// queues be durable and backed up by Sql Server
opts.Policies.UseDurableLocalQueues();
});
Finally, with all that said, here’s one of the ways to schedule message deliveries:
public static async Task use_message_bus(IMessageBus bus)
{
// Send a message to be sent or executed at a specific time
await bus.ScheduleAsync(new DebitAccount(1111, 100), DateTimeOffset.UtcNow.AddDays(1));
// Or do the same, but this time express the time as a delay
await bus.ScheduleAsync(new DebitAccount(1111, 225), 1.Days());
// ScheduleAsync is really just syntactic sugar for this:
await bus.PublishAsync(new DebitAccount(1111, 225), new DeliveryOptions { ScheduleDelay = 1.Days() });
}
Or, if you want to utilize Wolverine’s cascading message functionality to keep most if not all of your handler method signatures “pure”, you can use this syntax within message handlers or HTTP endpoints:
public static IEnumerable<object> Consume(Incoming incoming)
{
// Delay the message delivery by 10 minutes
yield return new Message1().DelayedFor(10.Minutes());
// Schedule the message delivery for a certain time
yield return new Message2().ScheduledAt(new DateTimeOffset(DateTime.Today.AddDays(2)));
}
Finally, one last alternative that was primarily meant for saga usage, subclassing TimeoutMessage like so:
public record EnforceAccountOverdrawnDeadline(Guid AccountId) : TimeoutMessage(10.Days()), IAccountCommand;
By subclassing TimeoutMessage, the message type above is “scheduled” for a later time when it’s returned as a cascading message.
One of the things I’m wrestling with right now is frankly how to sell Wolverine as a server side toolset. Yes, it’s technically a message library like MassTransit or NServiceBus. It can also be used as “just” a mediator tool like MediatR. With Wolverine.HTTP, it’s even an alternative HTTP endpoint framework that’s technically an alternative to FastEndpoints, MVC Core, or Minimal API. You’ve got to categorize Wolverine somehow, and we humans naturally understand something new by comparing it to some older thing we’re already familiar with. In the case of Wolverine, it’s drastically selling the toolset short by comparing it to any of the older application frameworks I rattled off above because Wolverine fundamentally does much more to remove code ceremony, improve testability throughout your codebase, and generally just let you focus more on core application functionality than older application frameworks.
This post was triggered by a conversation I had with a friend last week who told me he was happy with his current toolset for HTTP API creation and couldn’t imagine how Wolverine’s HTTP endpoint model could possibly reduce his efforts. Challenge accepted!
For just this moment, consider a simplistic HTTP service that works on this little entity:
public record Counter(Guid Id, int Count);
Now, let’s build an HTTP endpoint that will:
Receive route arguments for the Counter.Id and the current tenant id because of course let’s say that we’re using multi-tenancy with a separate database per tenant
Try to look up the existing Counter entity by its id from the right tenant database
If the entity doesn’t exist, return a status code 404 and get out of there
If the entity does exist, increment the Count property and save the entity to the database and return a status code 204 for a successful request with an empty body
Just to make it easier on me because I already had this example code, we’re going to use Marten for persistence which happens to have much stronger multi-tenancy built in than EF Core. Knowing all that, here’s a sample MVC Core controller to implement the functionality I described above:
public class CounterController : ControllerBase
{
[HttpPost("/api/tenants/{tenant}/counters/{id}")]
[ProducesResponseType(204)] // empty response
[ProducesResponseType(404)]
public async Task<IResult> Increment(
Guid id,
string tenant,
[FromServices] IDocumentStore store)
{
// Open a Marten session for the right tenant database
await using var session = store.LightweightSession(tenant);
var counter = await session.LoadAsync<Counter>(id, HttpContext.RequestAborted);
if (counter == null)
{
return Results.NotFound();
}
else
{
counter = counter with { Count = counter.Count + 1 };
await session.SaveChangesAsync(HttpContext.RequestAborted);
return Results.Empty;
}
}
}
I’m completely open to recreating the multi-tenancy support from the Marten + Wolverine combo for EF Core and SQL Server through Wolverine, but I’m shamelessly waiting until another company is willing to engage with JasperFx Software to deliver that.
Alright, now let’s switch over to using Wolverine.HTTP with its WolverineFx.Http.Marten add on Nuget setup. Let’s drink some Wolverine koolaid and write a functionally identical endpoint the Wolverine way:
Seriously, this is the same functionality and even the same generated OpenAPI documentation. Some things to note:
Wolverine is able to derive much more of the OpenAPI documentation from the type signatures and from policies applied to the endpoint method, like…
The usage of the Document(Required = true) tells Wolverine that it will be trying to load a document of type Counter from Marten, and by default it’s going to do that through a route argument named “id”. The Required property tells Wolverine to return a 404 NotFound status code automatically if the Counter document doesn’t exist. This attribute usage also applies some OpenAPI smarts to tag the route as potentially returning a 404
The return value of the method is an IMartenOp “side effect” just saying “go save this document”, which Wolverine will do as part of this endpoint execution. Using the side effect makes this method a nice, simple pure function that’s completely synchronous. No wrestling with async Task, await, or schlepping around CancellationToken every which way
Because Wolverine can see there will not be any kind of response body, it’s going to use a 204 status code to denote the empty body and tag the OpenAPI with that as well.
There is absolutely zero Reflection happening at runtime because Wolverine is generating and compiling code at runtime (or ahead of time for faster cold starts) that “bakes” in all of this knowledge for fast execution
Wolverine + Marten has a far more robust support for multi-tenancy all the way through the technology stack than any other application framework I know of in .NET (web frameworks, mediators, or messaging libraries), and you can see that evident in the code above where Marten & Wolverine would already know how to detect tenant usage in an HTTP request and do all the wiring for you all the way through the stack so you can focus on just writing business functionality.
To make this all more concrete, here’s the generated code:
// <auto-generated/>
#pragma warning disable
using Microsoft.AspNetCore.Routing;
using System;
using System.Linq;
using Wolverine.Http;
using Wolverine.Marten.Publishing;
using Wolverine.Runtime;
namespace Internal.Generated.WolverineHandlers
{
// START: POST_api_tenants_tenant_counters_id_inc2
public class POST_api_tenants_tenant_counters_id_inc2 : Wolverine.Http.HttpHandler
{
private readonly Wolverine.Http.WolverineHttpOptions _wolverineHttpOptions;
private readonly Wolverine.Runtime.IWolverineRuntime _wolverineRuntime;
private readonly Wolverine.Marten.Publishing.OutboxedSessionFactory _outboxedSessionFactory;
public POST_api_tenants_tenant_counters_id_inc2(Wolverine.Http.WolverineHttpOptions wolverineHttpOptions, Wolverine.Runtime.IWolverineRuntime wolverineRuntime, Wolverine.Marten.Publishing.OutboxedSessionFactory outboxedSessionFactory) : base(wolverineHttpOptions)
{
_wolverineHttpOptions = wolverineHttpOptions;
_wolverineRuntime = wolverineRuntime;
_outboxedSessionFactory = outboxedSessionFactory;
}
public override async System.Threading.Tasks.Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
var messageContext = new Wolverine.Runtime.MessageContext(_wolverineRuntime);
// Building the Marten session
await using var documentSession = _outboxedSessionFactory.OpenSession(messageContext);
if (!System.Guid.TryParse((string)httpContext.GetRouteValue("id"), out var id))
{
httpContext.Response.StatusCode = 404;
return;
}
var counter = await documentSession.LoadAsync<Wolverine.Http.Tests.Bugs.Counter>(id, httpContext.RequestAborted).ConfigureAwait(false);
// 404 if this required object is null
if (counter == null)
{
httpContext.Response.StatusCode = 404;
return;
}
// The actual HTTP request handler execution
var martenOp = Wolverine.Http.Tests.Bugs.CounterEndpoint.Increment(counter);
if (martenOp != null)
{
// Placed by Wolverine's ISideEffect policy
martenOp.Execute(documentSession);
}
// Commit any outstanding Marten changes
await documentSession.SaveChangesAsync(httpContext.RequestAborted).ConfigureAwait(false);
// Have to flush outgoing messages just in case Marten did nothing because of https://github.com/JasperFx/wolverine/issues/536
await messageContext.FlushOutgoingMessagesAsync().ConfigureAwait(false);
// Wolverine automatically sets the status code to 204 for empty responses
if (!httpContext.Response.HasStarted) httpContext.Response.StatusCode = 204;
}
}
// END: POST_api_tenants_tenant_counters_id_inc2
}
Summary
Wolverine isn’t “just another messaging library / mediator / HTTP endpoint alternative.” Rather, Wolverine is a completely different animal that while fulfilling those application framework roles for server side .NET, potentially does a helluva lot more than older frameworks to help you write systems that are maintainable, testable, and resilient. And do all of that with a lot less of the typical “Clean/Onion/Hexagonal Architecture” cruft that shines in software conference talks and YouTube videos but helps lead teams into a morass of unmaintainable code in larger systems in the real world.
But yes, the Wolverine community needs to find a better way to communicate how Wolverine adds value above and beyond the more traditional server side application frameworks in .NET. I’m completely open to suggestions — and fully aware that some folks won’t like the “magic” in the “drank all the Wolverine Koolaid” approach I used.
You can of course use Wolverine with 100% explicit code and none of the magic.
In this post, let’s look at how Wolverine allows you to either control the parallelism of your background processing, or restrict the processing to be strictly sequential.
To review, in previous posts we were “publishing” a SignupRequest message from a Minimal API endpoint to Wolverine like so:
In this particular case, our application has a message handler for SignupRequest, so Wolverine has a sensible default behavior of publishing the message to a local, in memory queue where each message will be processed in a separate thread from the original HTTP request, and do so asynchronously in the background.
So far, so good? By default, each message type gets its own local, in memory queue, with a default “maximum degree of parallelism” equal to the number of detected processors (Environment.ProcessorCount). In addition, the local queues do not enforce strict ordering by default.
But now, what if you do need to strict sequential ordering? Or if you want to restrict or expand the number of parallel messages that can be processed? Or the get really wild, constrain some messages to running sequentially while other messages run in parallel?
First, let’s see how we could alter the parallelism of our SignUpRequest to an absurd degree and say that up to 20 messages could theoretically be processed at one time by the system. We’ll do that by breaking into the UseWolverine() configuration and adding this:
builder.Host.UseWolverine(opts =>
{
// The other stuff...
// Make the SignUpRequest messages be published with even
// more parallelization!
opts.LocalQueueFor<SignUpRequest>()
// A maximum of 20 at a time because why not!
.MaximumParallelMessages(20);
});
Easy enough, but now let’s say that we want all logical event messages in our system to be handled in the sequential order that our process publishes these messages. An easy way to do that with Wolverine is to have each event message type implement Wolverine’s IEvent marker interface like so:
public record Event1 : IEvent;
public record Event2 : IEvent;
public record Event3 : IEvent;
To be honest, the IEvent and corresponding IMessage and ICommand interfaces were added to Wolverine originally just to make it easier to transition a codebase from using NServiceBus to Wolverine, but those types have little actual meaning to Wolverine. The only way that Wolverine even uses them is for the purpose of “knowing” that a type is an outbound message so that Wolverine can preview the message routing for a type implementing one of these interfaces automatically in diagnostics.
Revisiting our UseWolverine() code block again, we’ll add that publishing rule like this:
builder.Host.UseWolverine(opts =>
{
// Other stuff...
opts.Publish(x =>
{
x.MessagesImplementing<IEvent>();
x.ToLocalQueue("events")
// Force every event message to be processed in the
// strict order they are enqueued, and one at a
// time
.Sequential();
});
});
With the code above, our application would be publishing every single message where the message type implements IEvent to that one local queue named “events” that has been configured to process messages in strict sequential order.
Summary and What’s Next
Wolverine makes it very easy to do work in background processing within your application, and even to easily control the desired parallelism in your application, or to make a subset of messages be processed in strict sequential order when that’s valuable instead.
To be honest, this series is what I go to when I feel like I need to write more Critter Stack content for the week, so it might be a minute or two before there’s a follow up. There’ll be at least two more posts, one on scheduling message execution and an example of using the local processing capabilities in Wolverine to implement the producer/consumer pattern.