This feature has been planned for Marten for years, but finally happened this month because a JasperFx Software client had a complicated multi-tenanted integration need for this as part of a complicated multi-tenanted and order sensitive data integration.
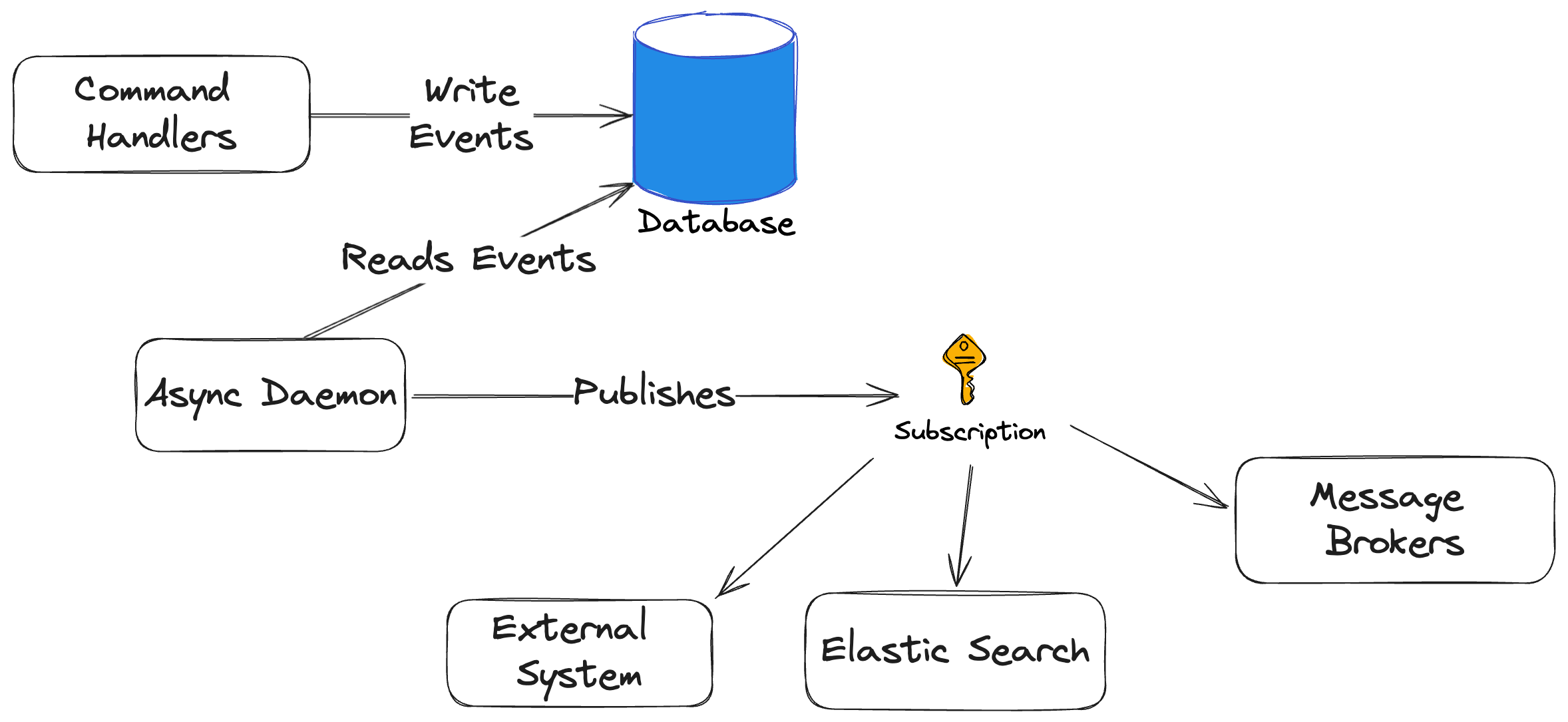
Marten recently (these samples are pulled from Marten 7.9) got a first class “event subscription” feature that allows users to take action upon events being appended to Marten’s event store in strict sequential order in a background process. While you’ve long been able to integrate Marten with other systems by using Marten’s older projection model, the newer subscription model is leaner and more efficient for background processing.
Before I get to “what” it is, let’s say that you need to carry out some kind of background processing on these events as they are captured? For example, maybe you need to:
- Publish events to an external system as some kind of integration?
- Carry out background processing based on a captured event
- Build a view representation of the events in something outside of the current PostgreSQL database, like maybe an Elastic Search view for better searching
With this recently added feature, you can utilize Marten’s ISubscription model that runs within Marten’s async daemon subsystem to “push” events into your subscriptions as events flow into your system. Note that this is a background process within your application, and happen in a completely different thread than the initial work of appending and saving events to the Marten event storage.
Subscriptions will always be an implementation of the ISubscription interface shown below:
/// <summary>
/// Basic abstraction for custom subscriptions to Marten events through the async daemon. Use this in
/// order to do custom processing against an ordered stream of the events
/// </summary>
public interface ISubscription : IAsyncDisposable
{
/// <summary>
/// Processes a page of events at a time
/// </summary>
/// <param name="page"></param>
/// <param name="controller">Use to log dead letter events that are skipped or to stop the subscription from processing based on an exception</param>
/// <param name="operations">Access to Marten queries and writes that will be committed with the progress update for this subscription</param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
Task<IChangeListener> ProcessEventsAsync(EventRange page, ISubscriptionController controller,
IDocumentOperations operations,
CancellationToken cancellationToken);
}
So far, the subscription model gives you these abilities:
- Access to the Marten
IDocumentOperationsservice that is scoped to the processing of a single page and can be used to either query additional data or to make database writes within the context of the same transaction that Marten will use to record the current progress of the subscription to the database - Error handling abilities via the
ISubscriptionControllerinterface argument that can be used to record events that were skipped by the subscription or to completely stop all further processing - By returning an
IChangeListener, the subscription can be notified right before and right after Marten commits the database transaction for any changes including recording the current progress of the subscription for the current page. This was done purposely to enable transactional outbox approaches like the one in Wolverine. See the async daemon diagnostics for more information. - The ability to filter the event types or stream types that the subscription is interested in as a way to greatly optimize the runtime performance by preventing Marten from having to fetch events that the subscription will not process
- The ability to create the actual subscription objects from the application’s IoC container when that is necessary
- Flexible control over where or when the subscription starts when it is first applied to an existing event store
- Some facility to “rewind and replay” subscriptions
To make this concrete, here’s the simplest possible subscription you can make to simply write out a console message for every event:
public class ConsoleSubscription: ISubscription
{
public Task<IChangeListener> ProcessEventsAsync(EventRange page, ISubscriptionController controller, IDocumentOperations operations,
CancellationToken cancellationToken)
{
Console.WriteLine($"Starting to process events from {page.SequenceFloor} to {page.SequenceCeiling}");
foreach (var e in page.Events)
{
Console.WriteLine($"Got event of type {e.Data.GetType().NameInCode()} from stream {e.StreamId}");
}
// If you don't care about being signaled for
return Task.FromResult(NullChangeListener.Instance);
}
public ValueTask DisposeAsync()
{
return new ValueTask();
}
}
And to register that with our Marten store:
var builder = Host.CreateApplicationBuilder();
builder.Services.AddMarten(opts =>
{
opts.Connection(builder.Configuration.GetConnectionString("marten"));
// Because this subscription has no service dependencies, we
// can use this simple mechanism
opts.Events.Subscribe(new ConsoleSubscription());
// Or with additional configuration like:
opts.Events.Subscribe(new ConsoleSubscription(), s =>
{
s.SubscriptionName = "Console"; // Override Marten's naming
s.SubscriptionVersion = 2; // Potentially version as an all new subscription
// Optionally create an allow list of
// event types to subscribe to
s.IncludeType<InvoiceApproved>();
s.IncludeType<InvoiceCreated>();
// Only subscribe to new events, and don't try
// to apply this subscription to existing events
s.Options.SubscribeFromPresent();
});
})
.AddAsyncDaemon(DaemonMode.HotCold);
using var host = builder.Build();
await host.StartAsync();
Here’s a slightly more complicated sample that publishes events to a configured Kafka topic:
public class KafkaSubscription: SubscriptionBase
{
private readonly KafkaProducerConfig _config;
public KafkaSubscription(KafkaProducerConfig config)
{
_config = config;
SubscriptionName = "Kafka";
// Access to any or all filtering rules
IncludeType<InvoiceApproved>();
// Fine grained control over how the subscription runs
// in the async daemon
Options.BatchSize = 1000;
Options.MaximumHopperSize = 10000;
// Effectively run as a hot observable
Options.SubscribeFromPresent();
}
// The daemon will "push" a page of events at a time to this subscription
public override async Task<IChangeListener> ProcessEventsAsync(
EventRange page,
ISubscriptionController controller,
IDocumentOperations operations,
CancellationToken cancellationToken)
{
using var kafkaProducer =
new ProducerBuilder<string, string>(_config.ProducerConfig).Build();
foreach (var @event in page.Events)
{
await kafkaProducer.ProduceAsync(_config.Topic,
new Message<string, string>
{
// store event type name in message Key
Key = @event.Data.GetType().Name,
// serialize event to message Value
Value = JsonConvert.SerializeObject(@event.Data)
}, cancellationToken);
}
// We don't need any kind of callback, so the nullo is fine
return NullChangeListener.Instance;
}
}
// Just assume this is registered in your IoC container
public class KafkaProducerConfig
{
public ProducerConfig? ProducerConfig { get; set; }
public string? Topic { get; set; }
}
This time, it’s requiring IoC services injected through its constructor, so we’re going to use this mechanism to add it to Marten:
var builder = Host.CreateApplicationBuilder();
builder.Services.AddMarten(opts =>
{
opts.Connection(builder.Configuration.GetConnectionString("marten"));
})
// Marten also supports a Scoped lifecycle, and quietly forward Transient
// to Scoped
.AddSubscriptionWithServices<KafkaSubscription>(ServiceLifetime.Singleton, o =>
{
// This is a default, but just showing what's possible
o.IncludeArchivedEvents = false;
o.FilterIncomingEventsOnStreamType(typeof(Invoice));
// Process no more than 10 events at a time
o.Options.BatchSize = 10;
})
.AddAsyncDaemon(DaemonMode.HotCold);
using var host = builder.Build();
await host.StartAsync();
But there’s more!
The subscriptions run with Marten’s async daemon process, which just got a world of improvements in the Marten V7 release, including the ability to distribute work across running nodes in your application at runtime.
I didn’t show it in this blog post, but there are also facilities to configure whether a new subscription will start by working through all the events from the beginning of the system, or whether the subscription should start from the current sequence of the event store, or even go back to an explicitly stated sequence or timestamp, then play forward. Marten also has support — similar to its projection rebuild functionality — to rewind and replay subscriptions.
Wolverine already has specific integrations to utilize Marten event subscriptions to process events with Wolverine message handlers, or to forward events as messages through Wolverine publishing (Kafka? Rabbit MQ? Azure Service Bus?), or to do something completely custom with batches of events at a time (which I’ll demonstrate in the next couple weeks). I’ll post about that soon after that functionality gets fully documented with decent examples.
Lastly, and this is strictly in the hopefully near term future, there will be specific support for Marten subscriptions in the planned “Critter Stack Pro” add on product to Marten & Wolverine to:
- Distribute subscription work across running nodes within your system — which actually exists in a crude, but effective form, and will absolutely be in Critter Stack Pro V1!
- User interface monitoring and control pane to manually turn on and off subscriptions, review performance, and manually “rewind” subscriptions
Hopefully much more on this soon. It’s taken much longer than I’d hoped, but it’s still coming.