A couple years ago I was in a small custom software development shop in Austin as “the .NET guy” for the company. The “Java guy” in the company asked me one day to try to name one think about .NET that he could look at that wasn’t just a copy of something older in the JVM. I almost immediately said for him to look at LINQ (Language INtegrated Query for non .NET folks who might stumble into this), as there isn’t really a one for one equivalent and I’d argue that LINQ is a real advantage within the .NET space.
As the author and primary support person for Marten’s LINQ provider support though, I have a decidedly mixed view of LINQ. It’s undoubtedly a powerful tool for .NET developers, but it’s maybe my least favorite thing to support in my entire OSS purview as a LINQ provider is a permutation hell kind of problem. To put it in perspective, I start making oodles of references to Through the Looking Glass anytime I have to spend some significant amount of time dealing with our LINQ support.
Nevertheless, Marten has an uncomfortably large backlog of LINQ related issues and we had a generous GitHub sponsorship to specifically improve the efficiency of the SQL generated for child collection queries in Marten, so I’ve been working on and off for a couple months to do a complete overhaul of our LINQ support that will land in Marten 7.0 sometime in the next couple months. Just in the last week I finally had a couple breakthroughs I’m ready to share. First though, let’s all get in the right headspace with some psychedelic music:
RIP Tom Petty!
and
And I’m going w/ Grace Potter’s cover version!
Alright, so back to the real problem. When Marten today encounters a LINQ query like this one:
Marten generates a really fugly SQL query using PostgreSQL Common Table Expressions to explode out the child collections into flat rows that can then be filtered to matching child rows, then finally uses a sub query filter on the original table to find the right rows. To translate, all that mumbo jumbo I said translates to “a big ass, slow query that doesn’t allow PostgreSQL to utilize its fancy GIN index support for faster JSONB querying.”
The Marten v7 support will be smart enough to “know” when it can generate more efficient SQL for certain child collection filtering. In the case above, Marten v7 can use the PostgreSQL containment operator to utilize the GIN indexing support and just be simpler in general with SQL like this:
select d.id, d.data from public.mt_doc_top as d where CAST(d.data ->> 'Middles' as jsonb) @> :p0 LIMIT :p1
p0: [{"Color":2,"Bottoms":[{"Name":"Bill"}]}]
p1: 2
You might have to take my word for it right now that the SQL above is significantly more efficient than the previous LINQ support.
One more sample that I’m especially proud of. Let’s say you use this LINQ query:
var result = await theSession
.Query<Root>()
.Where(r => r.ChildsLevel1.Count(c1 => c1.Name == "child-1.1") == 1)
.ToListAsync();
This one’s a little more complicated because you need to do a test of the *number* of matching child elements within a child collection. Again, Marten vCurrent will use a nasty and not terribly efficient common table expression approach to give you the right data. For Marten v7, we specifically asked the Marten user base if we could abandon support for any PostgreSQL versions lower than PostgreSQL 12. *That* is letting us use PostgreSQL’s JSONPath query support within our LINQ provider and gets us to this SQL for the LINQ query from up above:
select d.id, d.data from public.mt_doc_root as d where jsonb_array_length(jsonb_path_query_array(d.data, '$.ChildsLevel1[*] ? (@.Name == $val1)', :p0)) = :p1
p0: {"val1":"child-1.1"}
p1: 1
It’s still quite a bit away, but the point of this post is that there is some significant improvements coming to Marten’s LINQ provider soon. More importantly to me, finishing this work up and knocking out the slew of open LINQ related GitHub issues will allow the Marten core team to focus on much more exciting new functionality in the event sourcing side of things.
Wolverine 1.2.0 rolled out this morning with some enhancements for HTTP endpoints. In the realm of HTTP endpoints, Wolverine’s raison d’être is to finally deliver a development experience to .NET developers that requires very low code ceremony, maximizes testability, and does all of that with good performance. Between some feedback from early adopters and some repetitive boilerplate code I saw doing a code review for a client last week (woot, I’ve actually got paying clients now!), Wolverine.Http got a couple new tricks to speed you up.
First off,
Here’s a common pattern in HTTP service development. Based on a route argument, you first load some kind of entity from persistence. If the data is not found, return a status code 404 that means the resource was not found, but otherwise continue working against that entity data you just loaded. Here’s a short hand way of doing that now with Wolverine “compound handlers“:
public record UpdateRequest(string Name, bool IsComplete);
public static class UpdateEndpoint
{
// Find required Todo entity for the route handler below
public static Task<Todo?> LoadAsync(int id, IDocumentSession session)
=> session.LoadAsync<Todo>(id);
[WolverinePut("/todos/{id:int}")]
public static StoreDoc<Todo> Put(
// Route argument
int id,
// The request body
UpdateRequest request,
// Entity loaded by the method above,
// but note the [Required] attribute
[Required] Todo? todo)
{
todo.Name = request.Name;
todo.IsComplete = request.IsComplete;
return MartenOps.Store(todo);
}
}
You’ll notice that the LoadAsync() method is looking up the Todo entity for the route parameter, where Wolverine would normally be passing that value to the matching Todo parameter of the main Put method. In this case though, because of the [Required] attribute, Wolverine.Http will stop processing with a 404 status code if the Todo cannot be found.
By contrast, here’s some sample code of a higher ceremony alternative that helped spawn this feature in the first place:
Note in the code above how the author had to pollute his code with attributes strictly for OpenAPI (Swagger) metadata because the valid response types cannot be inferred when you’re returning the IResult value that could frankly be just about anything in the world.
In the Wolverine 1.2 version above, Wolverine.Http is able to infer the exact same OpenAPI metadata as the busier Put() method in the image above. Also, and I think this is potentially valuable, the Wolverine 1.2 version turns the behavior into a purely synchronous version that is going to be mechanically easier to unit test.
So that’s required data, now let’s turn our attention to Wolverine’s new ProblemDetails support. While there is a Fluent Validation middleware package for Wolverine.Http that supports ProblemDetails in a generic way, I’m seeing usages where you just need to do some explicit validation for an HTTP endpoint. Wolverine 1.2 added this usage:
public class ProblemDetailsUsageEndpoint
{
public ProblemDetails Before(NumberMessage message)
{
// If the number is greater than 5, fail with a
// validation message
if (message.Number > 5)
return new ProblemDetails
{
Detail = "Number is bigger than 5",
Status = 400
};
// All good, keep on going!
return WolverineContinue.NoProblems;
}
[WolverinePost("/problems")]
public static string Post(NumberMessage message)
{
return "Ok";
}
}
public record NumberMessage(int Number);
Wolverine.Http now (as of 1.2.0) has a convention that sees a return value of ProblemDetails and looks at that as a “continuation” to tell the http handler code what to do next. One of two things will happen:
1. If the ProblemDetails return value is the same instance as WolverineContinue.NoProblems, just keep going 2. Otherwise, write the ProblemDetails out to the HTTP response and exit the HTTP request handling
Just as in the first [Required] usage, Wolverine is able to infer OpenAPI metadata about your endpoint to add a “produces ‘application/problem+json` with a 400 status code” item. And for those of you who like to get fancier or more specific with your HTTP status code usage, you can happily override that behavior with your own metadata attributes like so:
// Use 418 as the status code instead
[ProducesResponseType(typeof(ProblemDetails), 418)]
As long term Agile practitioners, the folks behind the whole JasperFx / “Critter Stack” ecosystem explicitly design our tools around the quality of “testability.” Case in point, Wolverine has quite a bit of integration test helpers for testing through message handler execution.
However, while helping a Wolverine user last week, they told me that they were bypassing those built in tools because they wanted to do an integration test of an HTTP service call that publishes a message to Wolverine. That’s certainly going to be a common scenario, so let’s talk about a strategy for reliably writing integration tests that both invoke an HTTP request and can observe the ongoing Wolverine activity to “know” when the “act” part of a typical “arrange, act, assert” test is complete.
In the Wolverine codebase itself, there’s a couple projects that we use to test the Wolverine.Http library:
WolverineWebApi — a web api project that has a lot of fake endpoints that tries to cover the whole gamut of usage scenarios for Wolverine.Http, including a couple use cases of publishing messages directly from HTTP endpoint handlers to asynchronous message handling inside of Wolverine core
Wolverine.Http.Tests — an xUnit.Net project that contains a mix of unit tests and integration tests through WolverineWebApi and Wolverine.Http itself
Back to the need to write integration tests that span work from HTTP service invocations through to Wolverine message processing, Wolverine.Http uses the Alba library (another JasperFx project!) to execute and run assertions against HTTP services. At least at the moment, xUnit.Net is my goto test runner library, so Wolverine.Http.Tests has this shared fixture that is shared between test classes:
public class AppFixture : IAsyncLifetime
{
public IAlbaHost Host { get; private set; }
public async Task InitializeAsync()
{
// Sorry folks, but this is absolutely necessary if you
// use Oakton for command line processing and want to
// use WebApplicationFactory and/or Alba for integration testing
OaktonEnvironment.AutoStartHost = true;
// This is bootstrapping the actual application using
// its implied Program.Main() set up
Host = await AlbaHost.For<Program>(x => { });
}
A couple notes on this approach:
I think it’s very important to use the actual application bootstrapping for the integration testing rather than trying to have a parallel IoC container configuration for test automation as I frequently see out in the wild. That doesn’t preclude customizing that bootstrapping a little bit to substitute in fake, stand in services for problematic external infrastructure.
The approach I’m showing here with xUnit.Net does have the effect of making the tests execute serially, which might not be what you want in very large test suites
I think the xUnit.Net shared fixture approach is somewhat confusing and I always have to review the documentation on it when I try to use it
There’s also a shared base class for integrated HTTP tests called IntegrationContext, with a little bit of that shown below:
[CollectionDefinition("integration")]
public class IntegrationCollection : ICollectionFixture<AppFixture>
{
}
[Collection("integration")]
public abstract class IntegrationContext : IAsyncLifetime
{
private readonly AppFixture _fixture;
protected IntegrationContext(AppFixture fixture)
{
_fixture = fixture;
}
// more....
More germane to this particular post, here’s a helper method inside of IntegrationContext I wrote specifically to do integration testing that has to span an HTTP request through to asynchronous Wolverine message handling:
// This method allows us to make HTTP calls into our system
// in memory with Alba, but do so within Wolverine's test support
// for message tracking to both record outgoing messages and to ensure
// that any cascaded work spawned by the initial command is completed
// before passing control back to the calling test
protected async Task<(ITrackedSession, IScenarioResult)> TrackedHttpCall(Action<Scenario> configuration)
{
IScenarioResult result = null;
// The outer part is tying into Wolverine's test support
// to "wait" for all detected message activity to complete
var tracked = await Host.ExecuteAndWaitAsync(async () =>
{
// The inner part here is actually making an HTTP request
// to the system under test with Alba
result = await Host.Scenario(configuration);
});
return (tracked, result);
}
Now, for a sample usage of that test helpers, here’s a fake endpoint from WolverineWebApi that I used to prove that Wolverine.Http endpoints can publish messages through Wolverine’s cascading message approach:
// This would have a string response and a 200 status code
[WolverinePost("/spawn")]
public static (string, OutgoingMessages) Post(SpawnInput input)
{
var messages = new OutgoingMessages
{
new HttpMessage1(input.Name),
new HttpMessage2(input.Name),
new HttpMessage3(input.Name),
new HttpMessage4(input.Name)
};
return ("got it", messages);
}
Psst. Notice how the endpoint method’s signature up above is a synchronous pure function which is cleaner and easier to unit test than the equivalent functionality would be in other .NET frameworks that would have required you to call asynchronous methods on some kind of IMessageBus interface.
To test this thing, I want to run an HTTP POST to the “/span” Url in our application, then prove that there were four matching messages published through Wolverine. Here’s the test for that functionality using our earlier TrackedHttpCall() testing helper:
[Fact]
public async Task send_cascaded_messages_from_tuple_response()
{
// This would fail if the status code != 200 btw
// This method waits until *all* detectable Wolverine message
// processing has completed
var (tracked, result) = await TrackedHttpCall(x =>
{
x.Post.Json(new SpawnInput("Chris Jones")).ToUrl("/spawn");
});
result.ReadAsText().ShouldBe("got it");
// "tracked" is a Wolverine ITrackedSession object that lets us interrogate
// what messages were published, sent, and handled during the testing perioc
tracked.Sent.SingleMessage<HttpMessage1>().Name.ShouldBe("Chris Jones");
tracked.Sent.SingleMessage<HttpMessage2>().Name.ShouldBe("Chris Jones");
tracked.Sent.SingleMessage<HttpMessage3>().Name.ShouldBe("Chris Jones");
tracked.Sent.SingleMessage<HttpMessage4>().Name.ShouldBe("Chris Jones");
}
There you go. In one fell swoop, we’ve got a reliable way to do integration testing against asynchronous behavior in our system that’s triggered by an HTTP service call — including any and all configured ASP.Net Core or Wolverine.Http middleware that’s part of the execution pipeline.
By “reliable” here in regards to integration testing, I want you to think about any reasonably complicated Selenium test suite and how infuriatingly often you get “blinking” tests that are caused by race conditions between some kind of asynchronous behavior and the test harness trying to make test assertions against the browser state. Wolverine’s built in integration test support can eliminate that kind of inconsistent test behavior by removing the race condition as it tracks all ongoing work for completion.
Oh, and here’s Chris Jones sacking Joe Burrow in the AFC Championship game to seal the Chiefs win that was fresh in my mind when I originally wrote that code above:
I saw someone on Twitter today asking to hear how Wolverine differs from MediatR. First off, Wolverine is a much bigger, more ambitious tool than MediatR is trying to be and covers far more use cases. Secondly though, Wolverine’s middleware strategy has some significant advantages over the equivalent strategies in other .NET tools.
Wolverine got its 1.0 release yesterday and I’m hoping that gives the tool a lot more visibility and earns it some usage over the next year. Today I wanted to show how the internal runtime model in general and specifically Wolverine’s approach to middleware is quite different than other .NET tools — and certainly try to sell you on why I think Wolverine’s approach is valuable.
For the “too long, didn’t read” crowd, the Wolverine middleware approach has these advantages over other similar .NET tools:
Potentially more efficient at runtime. Fewer object allocations, less dictionary lookups, and just a lot less runtime logic in general
Able to be more selectively applied on a message by message or HTTP endpoint by endpoint basis
Can show you the exact code that explains exactly what middleware is applied and how it’s used on each individual message or HTTP route
For now, let’s consider the common case of wanting to use Fluent Validation to validate HTTP inputs to web service endpoints. If the validation is successful, continue processing, but if the validation fails, use the ProblemDetails specification to instead return a response denoting the validation errors and a status code of 400 to denote an invalid request.
To do that with Wolverine, first start with an HTTP web service project and add a reference to the WolverineFx.Http.FluentValidation Nuget. When you’re configuring Wolverine HTTP endpoints, add this single line to your application bootstrapping code (follow a sample usage here):
app.MapWolverineEndpoints(opts =>
{
// more configuration for HTTP...
// Opting into the Fluent Validation middleware from
// Wolverine.Http.FluentValidation
opts.UseFluentValidationProblemDetailMiddleware();
});
The code above also adds some automatic discovery of Fluent Validation validators and registration into your application’s IoC container, but with a little twist as Wolverine is guessing at the desired IoC lifetime to try to make some runtime optimizations (i.e., a validator type that has no constructor arguments is assumed to be stateless so it doesn’t have to be recreated between requests).
And now for a simple endpoint, some request models, and Fluent Validation validator types to test this out:
public class ValidatedEndpoint
{
[WolverinePost("/validate/customer")]
public static string Post(CreateCustomer customer)
{
return "Got a new customer";
}
[WolverinePost("/validate/user")]
public static string Post(CreateUser user)
{
return "Got a new user";
}
}
public record CreateCustomer
(
string FirstName,
string LastName,
string PostalCode
)
{
public class CreateCustomerValidator : AbstractValidator<CreateCustomer>
{
public CreateCustomerValidator()
{
RuleFor(x => x.FirstName).NotNull();
RuleFor(x => x.LastName).NotNull();
RuleFor(x => x.PostalCode).NotNull();
}
}
}
public record CreateUser
(
string FirstName,
string LastName,
string PostalCode,
string Password
)
{
public class CreateUserValidator : AbstractValidator<CreateUser>
{
public CreateUserValidator()
{
RuleFor(x => x.FirstName).NotNull();
RuleFor(x => x.LastName).NotNull();
RuleFor(x => x.PostalCode).NotNull();
}
}
public class PasswordValidator : AbstractValidator<CreateUser>
{
public PasswordValidator()
{
RuleFor(x => x.Password).Length(8);
}
}
}
And with that, let’s check out our functionality with these unit tests from the Wolverine codebase itself that uses Alba to test ASP.Net Core endpoints in memory:
[Fact]
public async Task one_validator_happy_path()
{
var createCustomer = new CreateCustomer("Creed", "Humphrey", "11111");
// Succeeds w/ a 200
var result = await Scenario(x =>
{
x.Post.Json(createCustomer).ToUrl("/validate/customer");
x.ContentTypeShouldBe("text/plain");
});
}
[Fact]
public async Task one_validator_sad_path()
{
var createCustomer = new CreateCustomer(null, "Humphrey", "11111");
var results = await Scenario(x =>
{
x.Post.Json(createCustomer).ToUrl("/validate/customer");
x.ContentTypeShouldBe("application/problem+json");
x.StatusCodeShouldBe(400);
});
// Just proving that we have ProblemDetails content
// in the request
var problems = results.ReadAsJson<ProblemDetails>();
}
So what that unit test proves, is that the middleware is happily applying the Fluent Validation validators before the main request handler, and aborting the request handling with a ProblemDetails response if there are any validation failures.
At this point, an experienced .NET web developer is saying “so what, I can do this with [other .NET tool] today” — and you’d be right. Before I dive into what Wolverine does differently that makes its middleware both more efficient and potentially easier to understand, let’s take a detour into some value that Wolverine adds that other similar .NET tools cannot match.
Automatic OpenAPI Configuration FTW!
Of course we live in a world where there’s a reasonable expectation that HTTP web services today will be well described by OpenAPI metadata, and the potential usage of a ProblemDetails response should be reflected in that metadata. Not to worry though, because Wolverine’s middleware infrastructure is also able to add OpenAPI metadata automatically as a nice bonus. Here’s a screenshot of the Swashbuckle visualization of the OpenAPI metadata for the /validate/customer endpoint from earlier:
Just so you’re keeping score, I’m not aware of any other ASP.Net Core tool that can derive OpenAPI metadata as part of its middleware strategy
But there’s too much magic!
So there’s some working code that auto-magically applies middleware to your HTTP endpoint code through some type matching, assembly discovery, conventions, and ZOMG there’s magic in there! How will I ever possibly unwind any of this or understand what Wolverine is doing?
Wolverine’s runtime model depends on generating code to be the “glue” between your code, any middleware usage, and Wolverine or ASP.Net Core itself. There are other advantages to that model, but a big one is that Wolverine can reveal and to some degree even explain what it’s going at runtime through the generated code.
For the /validate/customer endpoint shown earlier with the Fluent Validation middleware applied, here’s the code that Wolverine generates (after a quick IDE reformatting to make it less ugly):
public class POST_validate_customer : Wolverine.Http.HttpHandler
{
private readonly WolverineHttpOptions _options;
private readonly IValidator<CreateCustomer> _validator;
private readonly IProblemDetailSource<CreateCustomer> _problemDetailSource;
public POST_validate_customer(WolverineHttpOptions options, IValidator<CreateCustomer> validator, ProblemDetailSource<CreateCustomer> problemDetailSource) : base(options)
{
_options = options;
_validator = validator;
_problemDetailSource = problemDetailSource;
}
public override async Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
var (customer, jsonContinue) = await ReadJsonAsync<CreateCustomer>(httpContext);
if (jsonContinue == Wolverine.HandlerContinuation.Stop) return;
var result = await FluentValidationHttpExecutor.ExecuteOne<CreateCustomer>(_validator, _problemDetailSource, customer).ConfigureAwait(false);
if (!(result is WolverineContinue))
{
await result.ExecuteAsync(httpContext).ConfigureAwait(false);
return;
}
var result_of_Post = ValidatedEndpoint.Post(customer);
await WriteString(httpContext, result_of_Post);
}
}
The code above will clearly show you the exact ordering and usage of any middleware. In the case of the Fluent Validation middleware, Wolverine is able to alter the code generation a little for:
With no matching IValidator strategies registered for the request model (CreateCustomer or CreateUser for examples), the Fluent Validation middleware is not applied at all
With one IValidator, you see the code above
With multiple IValidator strategies for a request type, Wolverine generates slightly more complicated code to iterate through the strategies and combine the validation results
Some other significant points about that ugly, generated code up above:
That object is only created once and directly tied to the ASP.Net Core route at runtime
When that HTTP route is executed, there’s no usage of an IoC container whatsoever at runtime because the exact execution is set in the generated code with all the necessary references already made
This runtime strategy leads to fewer object allocations, dictionary lookups, and service location calls than the equivalent functionality in other popular .NET tools which will lead to better performance and scalability
For easier unit testing, it’s often valuable to separate responsibilities of “deciding” what to do from the actual “doing.” The side effect facility in Wolverine is an example of this strategy.You will need Wolverine 0.9.17 that just dropped for this feature.
At times, you may with to make Wolverine message handlers (or HTTP endpoints) be pure functions as a way of making the handler code itself easier to test or even just to understand. All the same, your application will almost certainly be interacting with the outside world of databases, file systems, and external infrastructure of all types. Not to worry though, Wolverine has some facility to allow you to declare the side effects as return values from your handler.
To make this concrete, let’s say that we’re building a message handler that will take in some textual content and an id, and then try to write that text to a file at a certain path. In our case, we want to be able to easily unit test the logic that “decides” what content and what file path a message should be written to without ever having any usage of the actual file system (which is notoriously irritating to use in tests).
First off, I’m going to create a new “side effect” type for writing a file like this:
// ISideEffect is a Wolverine marker interface
public class WriteFile : ISideEffect
{
public string Path { get; }
public string Contents { get; }
public WriteFile(string path, string contents)
{
Path = path;
Contents = contents;
}
// Wolverine will call this method.
public Task ExecuteAsync(PathSettings settings)
{
if (!Directory.Exists(settings.Directory))
{
Directory.CreateDirectory(settings.Directory);
}
return File.WriteAllTextAsync(Path, Contents);
}
}
And the matching message type, message handler, and a settings class for configuration:
// An options class
public class PathSettings
{
public string Directory { get; set; }
= Environment.CurrentDirectory.AppendPath("files");
}
public record RecordText(Guid Id, string Text);
public class RecordTextHandler
{
public WriteFile Handle(RecordText command)
{
return new WriteFile(command.Id + ".txt", command.Text);
}
}
At runtime, Wolverine is generating this code to handle the RecordText message:
public class RecordTextHandler597515455 : Wolverine.Runtime.Handlers.MessageHandler
{
public override System.Threading.Tasks.Task HandleAsync(Wolverine.Runtime.MessageContext context, System.Threading.CancellationToken cancellation)
{
var recordTextHandler = new CoreTests.Acceptance.RecordTextHandler();
var recordText = (CoreTests.Acceptance.RecordText)context.Envelope.Message;
var pathSettings = new CoreTests.Acceptance.PathSettings();
var outgoing1 = recordTextHandler.Handle(recordText);
// Placed by Wolverine's ISideEffect policy
return outgoing1.ExecuteAsync(pathSettings);
}
}
To explain what is happening up above, when Wolverine sees that any return value from a message handler implements the Wolverine.ISideEffect interface, Wolverine knows that that value should have a method named either Execute or ExecuteAsync() that should be executed instead of treating the return value as a cascaded message. The method discovery is completely by method name, and it’s perfectly legal to use arguments for any of the same types available to the actual message handler like:
Service dependencies from the application’s IoC container
The actual message
Any objects created by middleware
CancellationToken
Message metadata from Envelope
Taking this functionality farther, here’s a new example from the WolverineFx.Marten library that exploits this new side effect model to allow you to start event streams or store/insert/update documents from a side effect return value without having to directly touch Marten‘s IDocumentSession:
public static class StartStreamMessageHandler
{
// This message handler is creating a brand new Marten event stream
// of aggregate type NamedDocument. No services, no async junk,
// pure function mechanics. You could unit test the method by doing
// state based assertions on the StartStream object coming back out
public static StartStream Handle(StartStreamMessage message)
{
return MartenOps.StartStream<NamedDocument>(message.Id, new AEvent(), new BEvent());
}
public static StartStream Handle(StartStreamMessage2 message)
{
return MartenOps.StartStream<NamedDocument>(message.Id, new CEvent(), new BEvent());
}
}
As I get a little more time and maybe ambition, I want to start blogging more about how Wolverine is quite different from the “IHandler of T” model tools like MediatR, MassTransit, or NServiceBus. The “pure function” usage above potentially makes for a big benefit in terms of testability and longer term maintainability.
Today I’m going to continue with a contrived example from the “payment ingestion service,” this time on what I’m so far calling “compound handlers” in Wolverine. When building a system with any amount of business logic or workflow logic, there’s some philosophical choices that Wolverine is trying to make:
To maximize testability, business or workflow logic — as much as possible — should be in pure functions that are easily testable in isolated unit tests. In other words, you should be able to test this code without integration tests or mock objects. Just data in, and state-based assertions.
Of course your message handler will absolutely need to read data from our database in the course of actually handling messages. It’ll also need to write data to the underlying database. Yet we still want to push toward the pure function approach for all logic. To get there, I like Jim Shore’s A-Frame metaphor for how code should be organized to isolate business logic away from infrastructure and into nicely testable code.
I certainly didn’t set out this way years ago when what’s now Wolverine was first theorized, but Wolverine is trending toward using more functional decomposition with fewer abstractions rather than “traditional” class centric C# usage with lots of interfaces, constructor injection, and IoC usage. You’ll see what I mean when we hit the actual code
I don’t think that mock objects are evil per se, but they’re absolutely over-used in our industry. All I’m trying to suggest in this post is to structure code such that you don’t have to depend on stubs or any other kind of fake to set up test inputs to business or workflow logic code.
Consider the case of a message handler that needs to process a command message to apply a payment to principal within an existing loan. Depending on the amount and the account in question, the handler may need to raise domain events for early principle payment penalties (or alerts or whatever you actually do in this situation). That logic is going to need to know about both the related loan and account information in order to make that decision. The handler will also make changes to the loan to reflect the payment made as well, and commit those changes back to the database.
Just to sum things up, this message handler needs to:
Look up loan and account data
Use that data to carry out the business logic
Potentially persist the changed state
Alright, on to the handler, which I’m going to accomplish with a single class that uses two separate methods:
public record PayPrincipal(Guid LoanId, decimal Amount, DateOnly EffectiveDate);
public static class PayPrincipalHandler
{
// Wolverine will call this method first by naming convention.
// If you prefer being more explicit, you can use any name you like and decorate
// this with [Before]
public static async Task<(Account, LoanInformation)> LoadAsync(PayPrincipal command, IDocumentSession session,
CancellationToken cancellation)
{
Account? account = null;
var loan = await session
.Query<LoanInformation>()
.Include<Account>(x => x.AccountId, a => account = a)
.Where(x => x.Id == command.LoanId)
.FirstOrDefaultAsync(token: cancellation);
if (loan == null) throw new UnknownLoanException(command.LoanId);
if (account == null) throw new UnknownAccountException(loan.AccountId);
return (account, loan);
}
// This is the main handler, but it's able to use the data built
// up by the first method
public static IEnumerable<object> Handle(
// The command
PayPrincipal command,
// The information loaded from the LoadAsync() method above
LoanInformation loan,
Account account,
// We need this only to mark items as changed
IDocumentSession session)
{
// The next post will switch this to event sourcing I think
var status = loan.AcceptPrincipalPayment(command.Amount, command.EffectiveDate);
switch (status)
{
case PrincipalStatus.BehindSchedule:
// Maybe send an alert? Act on this in some other way?
yield return new PrincipalBehindSchedule(loan.Id);
break;
case PrincipalStatus.EarlyPayment:
if (!account.AllowsEarlyPayment)
{
// Maybe just a notification?
yield return new EarlyPrincipalPaymentDetected(loan.Id);
}
break;
}
// Mark the loan as being needing to be persisted
session.Store(loan);
}
}
Wolverine itself is weaving in the call first to LoadAsync(), and piping the results of that method to the inputs of the inner Handle() method, which now gets to be almost a pure function with just the call to IDocumentSession.Store() being “impure” — but at least that one single method is relatively painless to mock.
The point of doing this is really just to make the main Handle() method where the actual business logic is happening be very easily testable with unit tests as you can just push in the Account and Loan information. Especially in cases where there’s likely many permutations of inputs leading to different behaviors, it’s very advantageous to be able to walk right up to just the business rules and push inputs right into that, then do assertions on the messages returned from the Handle() function and/or assert on modifications to the Loan object.
TL:DR — Repository abstractions over persistence tooling can cause more harm than good.
Also notice that I directly used a reference to the Marten IDocumentSession rather than wrapping some kind of IRepository<Loan> or IAccountRepository abstraction right around Marten. That was very purposeful. I think those abstractions — especially narrow, entity-centric abstractions around basic CRUD or load methods cause more harm than good in nontrivial enterprise systems. In the case above, I was using a touch of advanced, Marten-specific behavior to load related documents in one network round trip as a performance optimization. That’s the exact kind of powerful ability of specific persistence tools that’s thrown away by generic “IRepository of T” strategies “just in case we decide to change database technologies later” that I believe to be harmful in larger enterprise systems. Moreover, I think that kind of abstraction bloats the codebase and leads to poorly performing systems.
We’re dogfooding Wolverine at work and the Critter Stack Discord is pretty active right now. All of that means that issues and opportunities to improve Wolverine are coming in fast right now. I just pushed Wolverine 0.9.13 (the Nugets are all named “WolverineFx” something because someone is squatting on the “Wolverine” name in Nuget).
First, quick thanks to Robin Arrowsmith for finding and fixing an issue with Wolverine’s Azure Service Bus support. And a more general thank you to the nascent Wolverine community for being so helpful working with me in Discord to improve Wolverine.
A few folks are reporting various issues with Wolverine handler discovery. To help alleviate whatever those issues turn out to be, Wolverine has a new mechanism to troubleshoot “why is my handler not being found by Wolverine?!?” issues.
We’re converting a service at work that lives within a giant distributed system that’s using NServiceBus for messaging today, so weirdly enough, there’s some important improvements for Wolverine’s interoperability with NServiceBus.
This will be worth a full blog post soon, but there’s some ability to add contextual logging about your domain (account numbers, tenants, product numbers, etc.) to Wolverine’s open telemetry and/or logging support. My personal goal here is to have all the necessary and valuable correlation between system activity, performance, and logged problems without forcing the development team to write repetitive code throughout their message handler code.
And one massive bug fix for how Wolverine generates runtime code in conjunction with your IoC service registrations for objects created by Wolverine itself. That’s a huge amount of technical mumbo jumbo that amounts to “even though Jeremy really doesn’t approve, you can inject Marten IDocumentSession or EF Core DbContext objects into repository classes while still using Wolverine transactional middleware and outbox support.” See this issue for more context. It’s a hugely important fix for folks who choose to use Wolverine with a typical, .NET Onion/Clean architecture with lots of constructor injection, repository wrappers, and making the garbage collection work like crazy at runtime.
This post is mostly an attempt to gather feedback from anyone out there interested enough to respond. Comment here, or better yet, tell us and the community what you’re interested in in the Critter Stack Discord community.
The so called “Critter Stack” is Marten, Wolverine, and a host of smaller, shared supporting projects within the greater JasperFx umbrella. Marten has been around for while now, just hit the “1,000 closed pull request” milestone, and will reach the 4 million download mark sometime next week. Wolverine is getting some early adopter love right now, and the feedback is being very encouraging to me right now.
The goal for this year is to make the Critter Stack the best technical choice for a CQRS with Event Sourcing style architecture across every technical ecosystem — and a strong candidate for server side development on the .NET platform for other types of architectural strategies. That’s a bold goal, and there’s a lot to do to fill in missing features and increase the ability of the Critter Stack to scale up to extremely large workloads. To keep things moving, the core team banged out our immediate road map for the next couple months:
Marten 6.0 within a couple weeks. This isn’t a huge release in terms of API changes, but sets us up for the future
Wolverine 1.0 shortly after. I think I’m to the point of saying the main priority is finishing the documentation website and conducting some serious load and chaos testing against the Rabbit MQ and Marten integrations (weirdly enough the exact technical stack we’ll be using at my job)
Marten 6.1: Formal event subscription mechanisms as part of Marten (ability to selectively publish events to a listener of some sort or a messaging broker). You can do this today as shown in Oskar’s blog post, but it’s not a first class citizen and not as efficient as it should be. Plus you’d want both “hot” and “cold” subscriptions.
Wolverine 1.1: Direct support for the subscription model within Marten so that you have ready recipes to publish events from Marten with Wolverine’s messaging capabilities. Technically, you can already do this with Wolverine + Marten’s outbox integration, but that only works through Wolverine handlers. Adding the first class recipe for “Marten to Wolverine messaging” I think will make it awfully easy to get up and going with event subscriptions fast.
Right now, Marten 6 and Wolverine 1.0 have lingered for awhile, so it’s time to get them out. After that, subscriptions seem to be the biggest source of user questions and requests right now, so that’s the obvious next thing to do. After that though, here’s a rundown of some of the major initiatives we could pursue in either Marten or Wolverine this year (and some straddle the line):
End to end multi-tenancy support in Wolverine, Marten, and ASP.Net Core. Marten has strong support for multi-tenancy, but users have to piece things together themselves together within their applications. Wolverine’s Marten integration is currently limited to only one Marten database per application
Hot/cold storage for active vs archived events. This is all about massive scalability for the event sourcing storage
Sharding the asynchronous projections to distribute work across multiple running nodes. More about scaling the event sourcing
Zero down time projection rebuilds. Big user ask. Probably also includes trying to optimize the heck out of the performance of this feature too
More advanced message broker feature support. AWS SNS support. Azure Service Bus topics support. Message batching in Rabbit MQ
Improving the Linq querying in Marten. At some point soon, I’d like to try to utilize the sql/json support within Postgresql to try to improve the Linq query performance and fill in more gaps in the support. Especially for querying within child collections. And better Select() transform support. That’s a neverending battle.
Optimized serverless story in Wolverine. Not exactly sure what this means, but I’m thinking to do something that tries to drastically reduce the “cold start” time
Open Telemetry support within Marten. It’s baked in with Wolverine, but not Marten yet. I think that’s going to be an opt in feature though
More persistence options within Wolverine. I’ll always be more interested in the full Wolverine + Marten stack, but I’d be curious to try out DynamoDb or CosmosDb support as well
There’s tons of other things to possibly do, but that list is what I’m personally most interested in our community getting to this year. No way there’s enough bandwidth for everything, so it’s time to start asking folks what they want out of these tools in the near future.
Today I’m taking a left turn in Albuquerque to talk about how to deal with injecting fake services in integration test scenarios for external service gateways in Wolverine applications using some tricks in the underlying Lamar IoC container — or really just anything that turns out to be difficult to deal with in automated tests.
Since this is a headless service, I’m not too keen on introducing Alba or WebApplicationFactory and all their humongous tail of ASP.Net Core dependencies. Instead, I made a mild change to the Program file of the main application to revert back to the “old” .NET 6 style of bootstrapping instead of the newer, implied Program.Main() style strictly to facilitate integration testing:
public static class Program
{
public static Task<int> Main(string[] args)
{
return CreateHostBuilder().RunOaktonCommands(args);
}
// This method is a really easy way to bootstrap the application
// in testing later
public static IHostBuilder CreateHostBuilder()
{
return Host.CreateDefaultBuilder()
.UseWolverine((context, opts) =>
{
// And a lot of necessary configuration here....
});
}
}
Now, I’m going to start a new xUnit.Net project to test the main application (NUnit or MSTest would certainly be viable as well). In the testing project, I want to test the payment ingestion service from the prior blog posts with basically the exact same set up as the main application, with the exception of replacing the service gateway for the “very unreliable 3rd party service” with a stub that we can control at will during testing. That stub could look like this:
// More on this later...
public interface IStatefulStub
{
void ClearState();
}
public class ThirdPartyServiceStub : IThirdPartyServiceGateway, IStatefulStub
{
public Dictionary<Guid, LoanInformation> LoanInformation { get; } = new();
public Task<LoanInformation> FindLoanInformationAsync(Guid loanId, CancellationToken cancellation)
{
if (LoanInformation.TryGetValue(loanId, out var information))
{
return Task.FromResult(information);
}
// I suppose you'd throw a more specific exception type, but I'm lazy, so....
throw new ArgumentOutOfRangeException(nameof(loanId), "Unknown load id");
}
public Task PostPaymentScheduleAsync(PaymentSchedule schedule, CancellationToken cancellation)
{
PostedSchedules.Add(schedule);
return Task.CompletedTask;
}
public List<PaymentSchedule> PostedSchedules { get; } = new();
public void ClearState()
{
PostedSchedules.Clear();
LoanInformation.Clear();
}
}
Now that we have a usable stub for later, let’s build up a test harness for our application. Right off the bat, I’m going to say that we won’t even try to run integration tests in parallel, so I’m going for a shared context that bootstraps the applications IHost:
public class AppFixture : IAsyncLifetime
{
public async Task InitializeAsync()
{
// This is bootstrapping the actual application using
// its implied Program.Main() set up
Host = await Program.CreateHostBuilder()
// This is from Lamar, this will override the service registrations
// no matter what order registrations are done. This was specifically
// intended for automated testing scenarios
.OverrideServices(services =>
{
// Override the existing application's registration with a stub
// for the third party service gateway
services.AddSingleton<IThirdPartyServiceGateway>(ThirdPartyService);
}).StartAsync();
}
// Just a convenient way to get at this later
public ThirdPartyServiceStub ThirdPartyService { get; } = new();
public IHost Host { get; private set; }
public Task DisposeAsync()
{
return Host.StopAsync();
}
}
So a couple comments about the code up above:
I’m delegating to the Program.CreateHostBuilder() method from our real application to create an IHostBuilder that is exactly the application itself. I think it’s important to do integration tests as close to the real application as possible so you don’t get false positives or false negatives from some sort of different bootstrapping or configuration of the application.
That being said, it’s absolutely going to be a pain in the ass to use the real “unreliable 3rd party service” in integration testing, so it would be very convenient to have a nice, easily controlled stub or “spy” we can use to capture data sent to the 3rd party or to set up responses from the 3rd party service
And no, we don’t know if your application actually works end to end if we use the whitebox testing approach, and there is very likely going to be unforeseen issues when we integrate with the real 3rd party service. All that being said, it’s very helpful to first know that our code works exactly the way we intended it to before we tackle fully end to end tests.
But if this were a real project, I’d spike the actual 3rd party gateway code ASAP because that’s likely where the major project risk is. In the real life project this was based on, that gateway code was not under my purview at first and I might have gotten myself temporarily banned from the client site after finally snapping at the developer “responsible” for that after about a year of misery. Moving on!
Lamar is StructureMap’s descendent, but it’s nowhere near as loosey-goosey flexible about runtime service overrides as StructureMap. That was very purposeful on my part as that led to Lamar having vastly better (1-3 orders of magnitude improvement) performance, and also to reduce my stress level by simplifying the Lamar usage over StructureMap’s endlessly complicated rules for service overrides. Long story short, that requires you to think through in advance a little bit about what services are going to be overridden in tests and to frankly use that sparingly compared to what was easy in StructureMap years ago.
Next, I’ll add the necessary xUnit ICollectionFixture type that I almost always forget to do at first unless I’m copy/pasting code from somewhere else:
[CollectionDefinition("integration")]
public class ScenarioCollection : ICollectionFixture<AppFixture>
{
}
Now, I like to have a base class for integration tests that just adds a tiny bit of reusable helpers and lifecycle methods to clean up the system state before all tests:
public abstract class IntegrationContext : IAsyncLifetime
{
public IntegrationContext(AppFixture fixture)
{
Host = fixture.Host;
Store = Host.Services.GetRequiredService<IDocumentStore>();
ThirdPartyService = fixture.ThirdPartyService;
}
public ThirdPartyServiceStub ThirdPartyService { get; set; }
public IHost Host { get; }
public IDocumentStore Store { get; }
async Task IAsyncLifetime.InitializeAsync()
{
// Using Marten, wipe out all data and reset the state
// back to exactly what we described in InitialAccountData
await Store.Advanced.ResetAllData();
// Clear out all the stateful stub state too!
// First, I'm getting at the broader Lamar service
// signature to do Lamar-specific things...
var container = (IContainer)Host.Services;
// Find every possible service that's registered in Lamar that implements
// the IStatefulStub interface, resolve them, and loop though them
// like so
foreach (var stub in container.Model.GetAllPossible<IStatefulStub>())
{
stub.ClearState();
}
}
// This is required because of the IAsyncLifetime
// interface. Note that I do *not* tear down database
// state after the test. That's purposeful
public Task DisposeAsync()
{
return Task.CompletedTask;
}
}
And now, some comments about that bit of code. You generally want a clean slate of system state going into each test, and our stub for the 3rd party system is stateful, so we’d want to clear it out between tests to keep from polluting the next test. That what the `IStatefulStub` interface and the calls to GetAllPossible() is helping us do with the Lamar container. If the system grows and we use more stubs, we can use that mechanism to have a one stop shop to clear out any stateful objects in the container between tests.
Lastly, here’s a taste of how the full test harness might be used:
public class ASampleTestHarness : IntegrationContext
{
public ASampleTestHarness(AppFixture fixture) : base(fixture)
{
}
[Fact]
public async Task how_the_test_might_work()
{
// Do the Arrange and Act part of the tests....
await Host.InvokeMessageAndWaitAsync(new PaymentValidated(new Payment()));
// Our test *should* have posted a single payment schedule
// within the larger workflow, and this will blow up if there's
// none or many
var schedule = ThirdPartyService.PostedSchedules.Single();
// Write assertions against the expected data for the schedule maybe?
}
}
I don’t like piecing together special application bootstrapping in the test automation projects, as that tends to drift apart from the actual application over time. Instead, I’d rather use the application’s own bootstrapping — in this case how it builds up an IHostBuilder — then apply some limited number of testing overrides.
Lamar has a couple helpers for test automation, including the OverrideServices() method and the GetAllPossible() helper that can be useful for clearing out state between tests in stubs or caches or who knows what else in a systematic way.
So far I’ve probably mostly blogged about things that Wolverine does that other tools like NServiceBus, MassTransit, or MediatR do as well. Next time out, I want to go completely off road where those tools can’t follow and into Wolverine’s “compound handler” strategy for maximum testability using Jim Shore’s A-Frame Architecture approach.
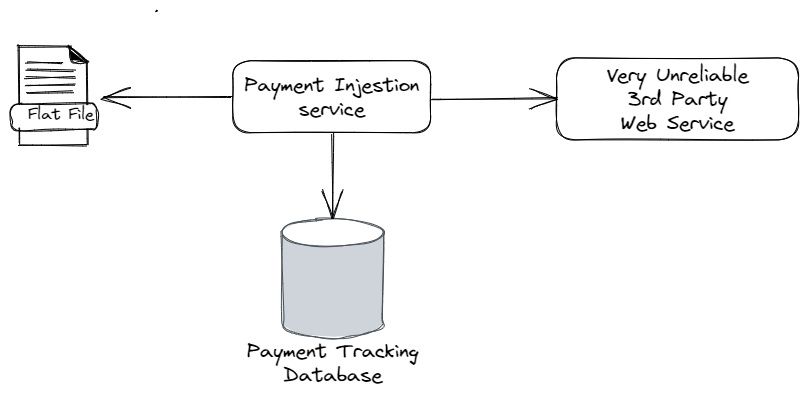
To review, I was describing a project I worked on years ago that involved some interactions with a very unreliable 3rd party web service system to handle payments originating from a flat file:
Just based on that diagram above, and admittedly some bad experiences in the shake down cruise of the historical system that diagram was based on, here’s some of the things that can go wrong:
The system blows up and dies while the payments from a particular file are only half way processed
Transient errors from database connectivity. Network hiccups
File IO errors from reading the flat files (I tend to treat direct file system access a lot like a poisonous snake due to very bad experiences early in my career)
HTTP errors from timeouts calling the web service
The 3rd party system is under distress and performing very poorly, such that a high percentage of requests are timing out
The 3rd party system can be misconfigured after code migrations on its system so that it’s technically “up” and responsive, but nothing actually works
The 3rd party system is completely down
Man, it’s a scary world sometimes!
Let’s say right now that our goal is as much as possible to have a system that is:
Able to recover from errors without losing any ongoing work
Doesn’t allow the system to permanently get into an inconsistent state — i.e. a file is marked as completely read, but somehow some of the payments from that file got lost along the way
Rarely needs manual intervention from production support to recover work or restart work
Heavens forbid, when something does happen that the system can’t recover from, it notifies production support
Now let’s go onto how to utilize Wolverine features to satisfy those goals in the face of all the potential problems I identified.
What if the system dies halfway through a file?
If you read through the last post, I used the local queueing mechanism in Wolverine to effectively create a producer/consumer workflow. Great! But what if the current process manages to die before all the ongoing work is completed? That’s where the durable inbox support in Wolverine comes in.
Pulling Marten in as our persistence strategy (but EF Core with either Postgresql or Sql Server is fully supported for this use case as well), I’m going to set up the application to opt into durable inbox mechanics for all locally queued messages like so (after adding the WolverineFx.Marten Nuget):
using Marten;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Oakton;
using Wolverine;
using Wolverine.Marten;
using WolverineIngestionService;
return await Host.CreateDefaultBuilder()
.UseWolverine((context, opts) =>
{
// There'd obviously be a LOT more set up and service registrations
// to be a real application
var connectionString = context.Configuration.GetConnectionString("marten");
opts.Services
.AddMarten(connectionString)
.IntegrateWithWolverine();
// I want all local queues in the application to be durable
opts.Policies.UseDurableLocalQueues();
opts.LocalQueueFor<PaymentValidated>().Sequential();
opts.LocalQueueFor<PostPaymentSchedule>().Sequential();
}).RunOaktonCommands(args);
And with those changes, all in flight messages in the local queues are also stored durably in the backing database. If the application process happens to fail in flight, the persisted messages will fail over to either another running node or be picked up by restarting the system process.
So far, so good? Onward…
Getting Over transient hiccups
Sometimes database interactions will fail with transient errors and will very well succeed if retried later. This is especially common when the database is under stress. Wolverine’s error handling policies easily accommodate that, and in this case I’m going to add some retry capabilities for basic database exceptions like so:
// Retry on basic database exceptions with some cooldown time in
// between retries
opts
.Policies
.OnException<NpgsqlException>()
.Or<MartenCommandException>()
.RetryWithCooldown(100.Milliseconds(), 250.Milliseconds(), 500.Milliseconds());
opts
.OnException<TimeoutException>()
.RetryWithCooldown(250.Milliseconds(), 500.Milliseconds());
Notice how I’ve specified some “cooldown” times for subsequent failures. This is more or less an example of exponential back off error handling that’s meant to effectively throttle a distressed subsystem to allow it to catch up and recover.
Now though, not every exception implies that the message may magically succeed at a later time, so in that case…
Walk away from bad apples
Over time we can recognize exceptions that pretty well mean that the message can never succeed. In that case we should just throw out the message instead of allowing it to suck down resources by being retried multiple times. Wolverine happily supports that as well. Let’s say that payment messages can never work if it refers to an account that cannot be found, so let’s do this:
// Just get out of there if the account referenced by a message
// does not exist!
opts
.OnException<UnknownAccountException>()
.Discard();
I should also note that Wolverine is writing to your application log when this happens.
Circuit Breakers to give the 3rd party system a timeout
As I’ve repeatedly said in this blog series so far, the “very unreliable 3rd party system” was somewhat less than reliable. What we found in practice was that the service would fail in bunches when it fell behind, but could recover over time. However, what would happen — even with the exponential back off policy — was that when the system was distressed it still couldn’t recover in time and continuing to pound it with retries just led to everything ending up in dead letter queues where it eventually required manual intervention to recover. That was exhausting and led to much teeth gnashing (and fingers pointed at me in angry meetings). In response to that, Wolverine comes with circuit breaker support as shown below:
// These are the queues that handle calls to the 3rd party web service
opts.LocalQueueFor<PaymentValidated>()
.Sequential()
// Add the circuit breaker
.CircuitBreaker(cb =>
{
// If the conditions are met to stop processing messages,
// Wolverine will attempt to restart in 5 minutes
cb.PauseTime = 5.Minutes();
// Stop listening if there are more than 20% failures
// over the tracking period
cb.FailurePercentageThreshold = 20;
// Consider the failures over the past minute
cb.TrackingPeriod = 1.Minutes();
// Get specific about what exceptions should
// be considered as part of the circuit breaker
// criteria
cb.Include<TimeoutException>();
// This is our fault, so don't shut off the listener
// when this happens
cb.Exclude<InvalidRequestException>();
});
opts.LocalQueueFor<PostPaymentSchedule>()
.Sequential()
// Or the defaults might be just fine
.CircuitBreaker();
With the set up above, if Wolverine detects too high a rate of message failures in a given time, it will completely stop message processing for that particular local queue. Since we’ve isolated the message processing for the two types of calls to the 3rd party web service, we’re allowing everything else to continue when the circuit breaker stops message processing. Do note that the circuit breaker functionality will try to restart message processing later after the designated pause time. Hopefully the pause time allows for the 3rd party system to recover — or for production support to make it recover. All of this without making all the backed up messages continuously fail and end up landing in the dead letter queues where it will take manual intervention to recover the work in progress.
Hold the line, the 3rd party system is broken!
On top of every thing else, the “very unreliable 3rd party system” was easily misconfigured at the drop of a hat such that it would become completely nonfunctional even though it appeared to be responsive. When this happened, every single message to that service would fail. So again, instead of letting all our pending work end up in the dead letter queue, let’s instead completely pause all message handling on the current local queue (wherever the error happened) if we can tell from the exception that the 3rd party system is nonfunctional like so:
// If we encounter this specific exception with this particular error code,
// it means that the 3rd party system is 100% nonfunctional even though it appears
// to be up, so let's pause all processing for 10 minutes
opts.OnException<ThirdPartyOperationException>(e => e.ErrorCode == 235)
.Requeue().AndPauseProcessing(10.Minutes());
Summary and next time!
It’s helpful to assign work within message handlers in such a way to maximize your error handling. Think hard about what actions in your system are prone to failure and may deserve to be their own individual message handler and messaging endpoint to allow for exact error handling policies like the way I used a circuit breaker on the queues that handled calls to the unreliable 3rd party service.
For my next post in this series, I think I want to make a diversion into integration testing using a stand in stub for the 3rd party service using the application setup with Lamar.