This is continuing a series about multi-tenancy with Marten, Wolverine, and ASP.Net Core:
- What is it and why do you care?
- Marten’s “Conjoined” Model
- Database per Tenant with Marten (this post)
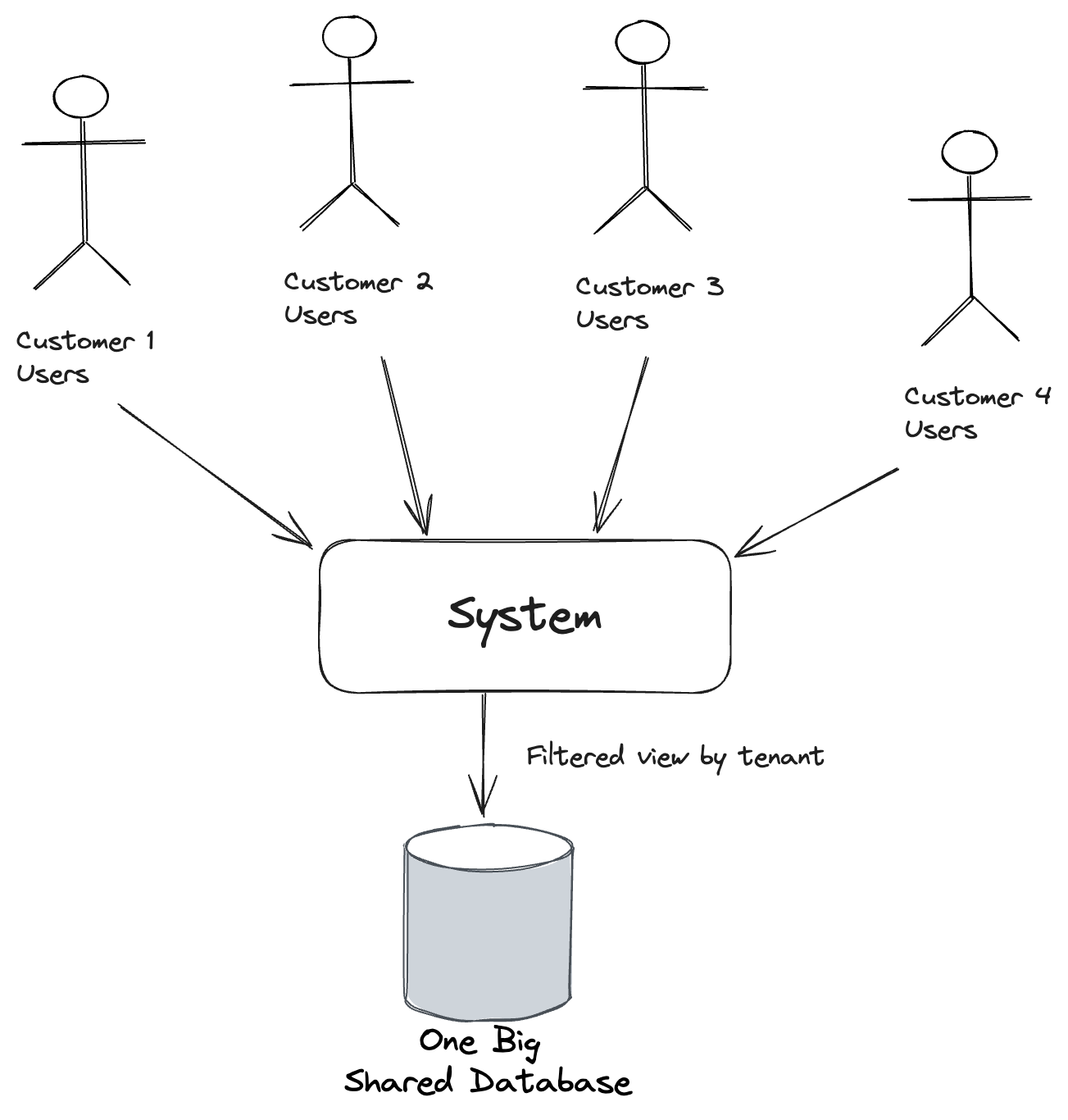
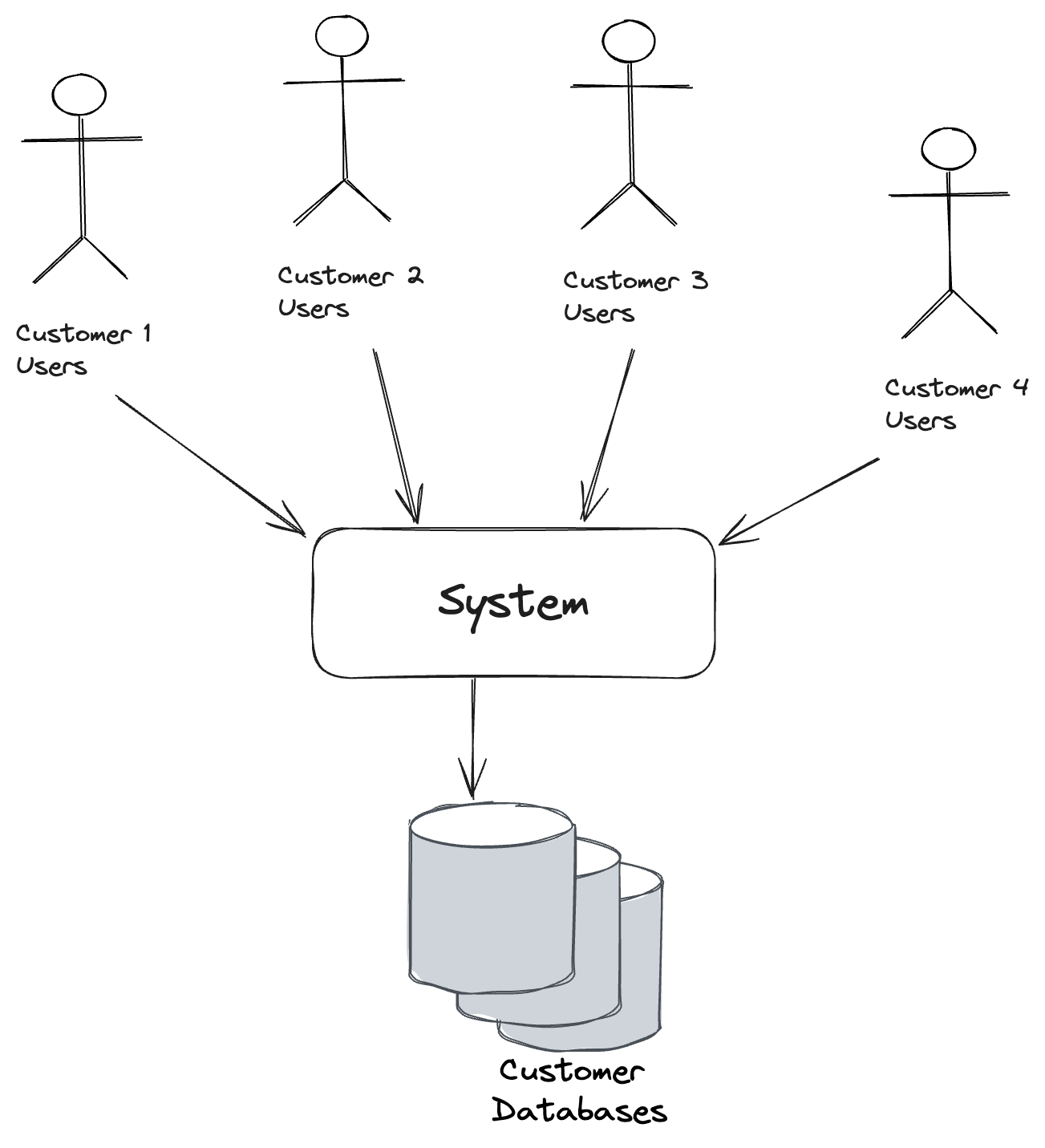
In the previous post we learned how to keep all the document or event data for each tenant in the same database, but using Marten’s “conjoined multi-tenancy” model to keep the data separated. This time out, let’s go for a much higher degree of separation by using a completely different database for each tenant with Marten.
Marten has a couple different recipes for “database per tenant multi-tenancy”, but let’s start with the simplest possible model where we’ll explicitly tell Marten about every single tenant by its id (the tenant_id values) and a connection string to that tenant’s specific database:
var builder = Host.CreateApplicationBuilder();
var configuration = builder.Configuration;
builder.Services.AddMarten(opts =>
{
// Setting up Marten to "know" about five different tenants
// and the database connection string for each
opts.MultiTenantedDatabases(tenancy =>
{
tenancy.AddSingleTenantDatabase(configuration.GetConnectionString("tenant1"), "tenant1");
tenancy.AddSingleTenantDatabase(configuration.GetConnectionString("tenant2"), "tenant2");
tenancy.AddSingleTenantDatabase(configuration.GetConnectionString("tenant3"), "tenant3");
tenancy.AddSingleTenantDatabase(configuration.GetConnectionString("tenant4"), "tenant4");
tenancy.AddSingleTenantDatabase(configuration.GetConnectionString("tenant5"), "tenant5");
});
});
using var host = builder.Build();
await host.StartAsync();
Just like in the post on conjoined tenancy, you can open a Marten document session (Marten’s unit of work abstraction for most typical operations) by supplying the tenant id like so:
// This was a recent convenience method added to
// Marten to fetch the IDocumentStore singleton
var store = host.DocumentStore();
// Open up a Marten session to the database for "tenant1"
await using var session = store.LightweightSession("tenant1");
With that session object above, you can query all the data in that one specific tenant, or write Marten documents or events to that tenant database — and only that tenant database.
Now, to answer some questions you might have:
- Marten’s
DocumentStoreis still a singleton registered service in your application’s IoC container that “knows” about multiple databases that are assumed to be identical.DocumentStoreis an expensive object to create, and an important part of Marten’s multi-tenancy strategy was to ensure that you only every needed one — even with multiple tenant databases - Marten is able to track the schema object creation completely separate for each tenant database, so the “it just works” default mode where Marten is completely able to do database migrations for you on the fly also “just works” with the multi-tenancy by separate database approach
- Marten’s (really Weasel‘s) command line tooling is absolutely able to handle multiple tenant databases. You can either migrate or patch all databases, or one database at a time through the command line tools
- Marten’s Async Daemon background processing of event projections is perfectly capable of managing the execution against multiple databases as well
- We’ll get into this in a later post, but it’s also possible to do two layers of multi-tenancy by combining both separate databases and conjoined multi-tenancy
Moving to a bit more complex case, let’s use Marten’s relatively recent “master table tenancy” model that will locate a table of tenant identifiers to tenant database connection strings in a table in a “master” database:
var builder = Host.CreateApplicationBuilder();
var configuration = builder.Configuration;
builder.Services.AddMarten(opts =>
{
var tenantDatabaseConnectionString = configuration.GetConnectionString("tenants");
opts.MultiTenantedDatabasesWithMasterDatabaseTable(tenantDatabaseConnectionString);
});
using var host = builder.Build();
await host.StartAsync();
The usage at runtime is identical to any other kind of multi-tenancy in Marten, but this model gives you the ability to add new tenants and tenant database at runtime without any down time. Marten will still be able to recognize a new tenant id and apply any necessary database changes at runtime.
Summary and What’s Next
Using separate databases for each tenant is a great way to create an even more rigid separation of data. You might opt for this model as a way to:
- Scale your system better by effectively sharding your customer databases into smaller databases
- Potentially reduce hosting costs by placing high volume tenants on different hardware than lower volume tenants
- Meet more rigid security requirements for less risk of tenant data being exposed incorrectly
To the last point, I’ve heard of several cases where regulatory concerns have trumped technical concerns and led teams to choose the tenant per database approach.
Of course, the obvious potential downsides are more complex deployments, more things to go wrong, and maybe higher hosting costs if you’re not careful. Yeah, I know I said that’s a potential cost savings, that sword can cut both ways, so just be aware of potential hosting cost changes.
As for what’s next, actually quite a bit! In subsequent posts we’ll dig into Wolverine’s multi-tenancy support, detecting the tenant id from HTTP requests, two level tenancy in Marten because’s that’s possible, and even Wolverine’s ability to spawn virtual actors by tenant id.
For my fellow Gen X’ers out there who keep hearing the words “keep the data separated” and naturally have this song stuck in your head: