We do quite a bit of distributed development and inter-service messaging at work. Some of this is done through exposing HTTP services. For asynchronous messaging between systems, my shop uses FubuMVC and its .Net Core replacement “Jasper” as a service bus (translate “Jasper” to “MassTransit” or “NServiceBus” when you read this). This blog post is a draft of our architectural team’s advice to our teams on choosing which option to use for their projects as part of our nascent microservice architecture approach. If any of my colleagues see this and disagree with me, don’t worry because one way or another this is going to be a living document and you’ll get to have input to this.
Microservices will generally need to send or process messages from other microservices or clients. To that end, it’s worth considering your options for inter-service communication.
We commonly use either HTTP services or the Jasper/FubuMVC service bus to communicate between services. Before you choose what tooling to use for service to service communication, first think about what your messaging requirements are. Service to service communication is roughly going to fall into these categories:
- Publish/Subscribe – asynchronously broadcast a message to all interested subscribers without expecting an immediate response. For the purpose of differentiation with “fire and forget,” let’s say that this also implies guaranteed delivery, meaning that messages are persisted durably until they are able to be published. The Jasper/FubuMVC service bus tools accomplish guaranteed delivery through the durable “store and forward” mechanism in LightningQueues and eventually RabbitMQ as we transition to Docker’ized hosting.
- Request/Reply – invoke another service while expecting a matching response. Querying data from a web service is an example. Sending a message through the service bus with the expectation of a response is also an example. The query handlers are an example of request/reply
- Fire and Forget – sending a request and not caring about any kind of response or whether or not the response is really received. This pattern is mostly appropriate for messages where you’re more concerned about performance and it’s not vital for the messages to be processed. The intra-node communication that Jasper/FubuMVC uses to coordinate subscriptions and health checks is done through LightningQueues in its “fire and forget” mode.
Use HTTP services if:
- Your service is going to be exposed to external users of your API
- Your service will need to be consumed by a web browser client
- You are exposing data query endpoints to other services, as in the other services need to request information and use that data immediately
- You do not need guaranteed delivery
- You do not exactly know upfront what other mechanisms that future clients of your microservice will support. The idea here is that HTTP is essentially ubiquitous across platforms
- You want to expose your service to non-.Net clients. It might be perfectly possible to use our existing service bus from other platforms, but in this case, HTTP endpoints are probably much less friction
Use a Service Bus if:
- You need durable, publish/subscribe semantics. If your service does not need to wait for a reply or acknowledgement from the downstream system, you probably want publish/subscribe.
- If you need to send the same messages to multiple subscribers
- If you need to support “dynamic subscriptions” that allow other services to register with your service to receive event messages from your service
- If you want fire and forget messaging, use the service bus with the non-persistent mode in LightningQueues. (think “ZeroMQ”)
- You may need to take advantage of the “delayed messages” feature in Jasper/FubuMVC
- You need to implement some kind of long-lived, saga workflow
- While it is possible to throttle HTTP requests, it is probably easier and more effective to accommodate surge loads through the message queues behind the service bus
- If the ordering of message processing is important, you probably need to be queueing within a service bus
Gray Areas
It’s not a perfectly black and white choice between using HTTP versus messaging with a service bus. The service bus also supports the request/reply pattern and you could happily use HTTP for fire and forget messaging. Both approaches can be scaled horizontally with our current technology stack. To muddle the picture even more, Jasper will eventually include an HTTP transport as well for more efficient request/reply support. If you feel like it’s unclear which direction to go, it is more than acceptable to choose the technology that the project team is most comfortable with. In all likelihood, that is going to mean using the more common ASP.Net Core stack for HTTP services rather than the somewhat custom service bus technology we use today.
Avoid These Integration Approaches
There will inevitably be reasons why we have to use options in this list because of external clients, but all the same, it is highly recommended that you do not use these integration approaches:
- Publishing file drops to the file system and monitoring folders
- Publishing files to FTP servers
- Integration through shared databases. Relational databases aren’t efficient queueing mechanisms anyway, and we really don’t want the hard coupling between services that comes from sharing an underlying database
Disagree? Have something to add? Feel very free to help me make this list better by dropping a comment;-)

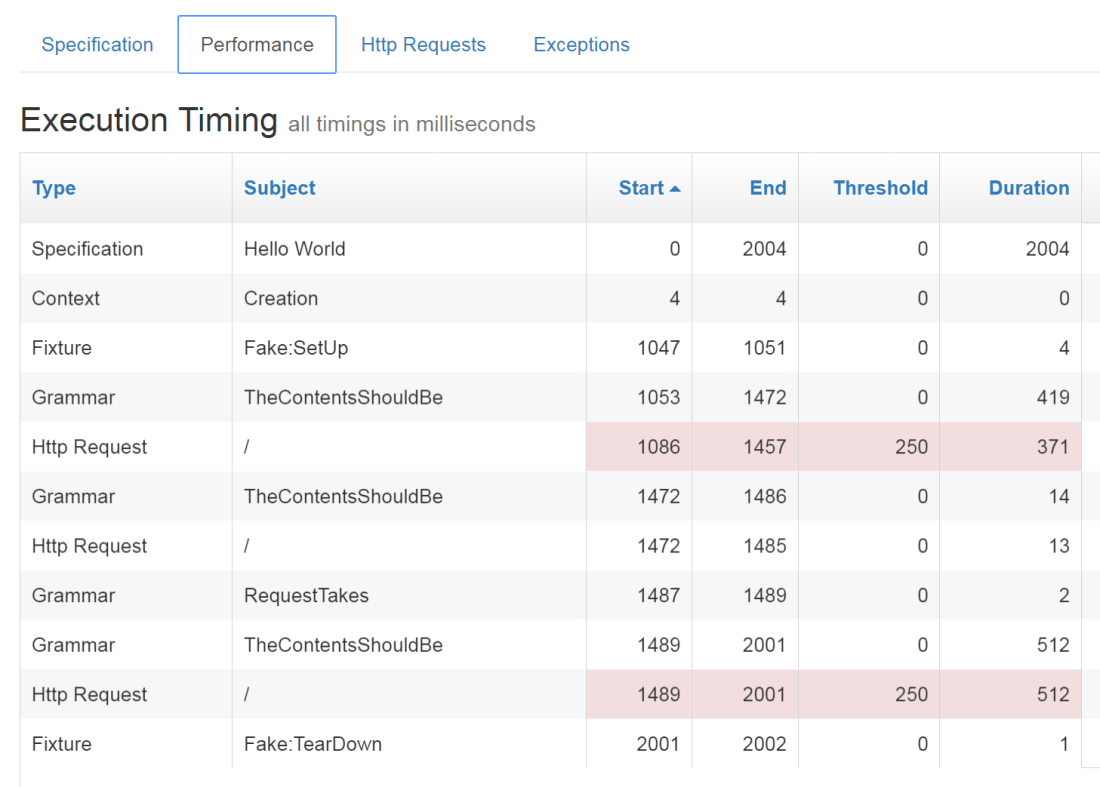
 If you’re curious, Storyteller pulls this off by using an
If you’re curious, Storyteller pulls this off by using an