It’s only a month since I’ve written an update on the Critter Stack roadmap, but it’s maybe worth some time on my part to update what I think the roadmap is now. The biggest change is the utter dominance of AI in the software development discourse and the fact that Claude usage has allowed us to chew through a shocking amount of backlog in the past 6 weeks. That’s probably also changed my own thinking about what should be next throughout this year.
First, some updates on what’s been added to the Critter Stack in just the last month:
We’ve added GroupJoin and GroupBy support to Marten (and Polecat’s) LINQ provider. This along with the “Composite Projection” feature we added earlier this year addresses the big concerns we had coming into this year for cross-document or cross-event stream views.
We also added first class EF Core Projections for Marten and Polecat as another option for creating denormalized views with Marten.
By the time you read this, we may very well have Polecat 1.0 out as well.
Short Term
The short term priority for myself and JasperFx Software is to deliver the CritterWatch MVP in a usable form by the end of March.
Marten, Wolverine, and even Polecat have no major new features planned for the short term and I think they will only get tactical releases for bug fixes and JasperFx client requests for a little while. And let me tell you, it feels *weird* to say that, but we’ve blown through a tremendous amount of the backlog so far in 2026.
Medium Term
Enhance CritterWatch until it’s the best in class monitoring tool for asynchronous messaging and event sourcing. Part of that will probably be adding quite a bit more functionality for development time as well.
For a JasperFx Software client, we’re doing PoC work on scaling Marten to be able to handle having several hundred billion events in a single system. I’m going to assume that this PoC will probably lead to enhancements in both Marten and Wolverine!
We’ll finally add some direct support to Marten for the PostGIS PostgreSQL extension
I’m a little curious to try to use the hstore extension with Marten as a possible way to optimize our new DCB support
Play with Pgvector and TimescaleDb in combination with Marten as some kind of vague “how can we say that Marten is even more awesome for AI?”
There’s going to be a new wave of releases later this year for Marten 9.0, Wolverine 6.0, and Polecat 2.0 that will mostly about performance optimizations and especially finding ways to optimize the cold start time of applications using these tools.
Babu and I (really all Babu so far) are going to be building a set of AI skills for using the Critter Stack tools that will be curated in a GitHub repository and available to JasperFx Software clients. I do not know what the full impact of AI tools are really going to be on software development, but I personally want to plan for the worst case that AI tools plus LLM-friendly documentation drastically reduces the demand for consulting and try to belatedly pivot JasperFx Software to being at least partially a product company.
Build tooling for spec driven development using the Critter Stack. I don’t have any details beyond “hey, wouldn’t that be cool?”. My initial thought is to play with Gherkin specifications that generates “best practices” Critter Stack code with the accompanying automated tests to boot.
One way or another, we’ll be building MCP support into the Critter Stack, but again, I don’t know anything more than “hey, wouldn’t that be cool?”
Long Term
Profit?
I’m playing with the idea of completely rebooting Storyteller as a new spec driven development tool. I have the Nuget rights to the “Storyteller” name and graphics from Khalid (a necessary requirement for any successful effort on my part), and I’ve always wanted to go back to it some day.
I trot out one of these posts at the beginning of each year, but this time around it’s “aspirations” instead of “plans” because a whole lot of stuff is gonna be a repeat from 2020 and 2021 and I’m not going to lose any sleep over what doesn’t get done in the New Year or not be open to brand new opportunities.
In 2022 I just want the chance to interact with other developers. I’ll be at ThatConference in Round Rock, TX in January May? speaking about Event Sourcing with Marten (my first in person conference since late 2019). Other than that, my only goal for the year (Covid-willing) is to maybe speak at a couple more in person conferences just to be able to interact with other developers in real space again.
My peak as a technical blogger was the late aughts, and I think I’m mostly good with not sweating any kind of attempt to regain that level of readership. I do plan to write material that I think would be useful for my shop, or just about what I’m doing in the OSS space when I feel like it.
Which brings me to the main part of this post, my involvement with the JasperFx (Marten, Lamar, etc). family of OSS projects (plus Storyteller) which takes up most of my extracurricular software related time. Just for an idea of the interdependencies, here’s the highlights of the JasperFx world:
.NET Transactional Document DB and Event Store on PostgreSQL
Marten took a big leap forward late in 2021 with the long running V4.0 release. I think that release might have been the single biggest, most complicated OSS release that I’ve ever been a part of — FubuMVC 1.0 notwithstanding. There’s also a 5.0-alpha release out that addresses .Net 6 support and the latest version of Npgsql.
Right now Marten is a victim of its own success, and our chat room is almost constantly hair on fire with activity, which directly led to some planned improvements for V5 (hopefully by the end of January?) in this discussion thread:
Multi-tenancy through a separate database per tenant (long planned, long delayed, finally happening now)
Some kind of ability to register and resolve services for more than one Marten database in a single application
And related to the previous two bullet points, improved database versioning and schema migrations that could accommodate there being more than one database within a single .Net codebase
Improve the “generate ahead” model to make it easier to adopt. Think faster cold start times for systems that use Marten
Beyond that, some of the things I’d like to maybe do with Marten this year are:
Investigate the usage of Postgresql table partitioning and database sharding as a way to increase scalability — especially with the event sourcing support
Projection snapshotting
In conjunction with Jasper, expand Marten’s asynchronous projection support to shard projection work across multiple running nodes, introduce some sort of optimized, no downtime projection rebuilds, and add some options for event streaming with Marten and Kafka or Pulsar
Try to build an efficient GraphQL adapter for Marten. And by efficient, I mean that you wouldn’t have to bounce through a Linq translation first and hopefully could opt into Marten’s JSON streaming wherever possible. This isn’t likely, but sounds kind of interesting to play with.
In a perfect, magic, unicorns and rainbows world, I’d love to see the Marten backlog in GitHub get under 50 items and stay there permanently. Commence laughing at me on that one:(
Jasper is a toolkit for common messaging scenarios between .Net applications with a robust in process command runner that can be used either with or without the messaging.
I started working on rebooting Jasper with a forthcoming V2 version late last year, and made quite a bit of progress before Marten got busy and .Net 6 being released necessitated other work. There’s a non-zero chance I will be using Jasper at work, which makes that a much more viable project. I’m currently in flight with:
Building Open Telemetry tracing directly into Jasper
Bi-directional compatibility with MassTransit applications (absolutely necessary to adopt this in my own shop).
Performance optimizations
.Net 6 support
Documentation overhaul
Kafka as a message transport option (Pulsar was surprisingly easy to add, and I’m hopeful that Kafka is similar)
And maybe, just maybe, I might extend Jasper’s somewhat unique middleware approach to web services utilizing the new ASP.Net Core Minimal API support. The idea there is to more or less create an improved version of the old FubuMVC idiom for building web services.
Lamar is a modern IoC container and the successor to StructureMap
I don’t have any real plans for Lamar in the new year, but there are some holes in the documentation, and a couple advanced features could sure use some additional examples. 2021 ended up being busy for Lamar though with:
Lamar v7 added support for IAsyncEnumerable (also finally), a small enhancement for the Minimal API feature in ASP.Net Core, and .Net 6 support
Add Robust Command Line Options to .Net Applications
Oakton did have a major v4/4.1 release to accommodate .Net 6 and ASP.Net Core Minimal API usage late in 2021, but I have yet to update the documentation. I would like to shift Oakton’s documentation website to VitePress first. The only plans I have for Oakton this year is to maybe see if there’d be a good way for Oakton to enable “buddy” command line tools to your application like the dotnet ef tool using the HostFactoryResolver class.
The bustling metropolis of Alba, MO
Alba is a wrapper around the ASP.Net Core TestServer for declarative, in process testing of ASP.Net Core web services. I don’t have any plans for Alba in the new year other than to respond to any issues or opportunities to smooth out usage from my shop’s usage of Alba.
Alba did get a couple major releases in 2021 though:
Solutions for creating robust, human readable acceptance tests for your .Net or CoreCLR system and a means to create “living” technical documentation.
Storyteller has been mothballed for years, and I was ready to abandon it last year, but…
We still use Storyteller for some big, long running integration style tests in both Marten and Jasper where I don’t think xUnit/NUnit is a good fit, and I think maybe I’d like to reboot Storyteller later this year. The “new” Storyteller (I’m playing with the idea of calling it “Bobcat” as it might be a different tool) would be quite a bit smaller and much more focused on enabling integration testing rather than trying to be a BDD tool.
Not sure what the approach might be, it could be:
“Just” write some extension helpers to xUnit or NUnit for more data intensive tests
“Just” write some extension helpers to SpecFlow
Rebuild the current Storyteller concept, but also support a Gherkin model
Something else altogether?
My goals if this happens is to have a tool for automated testing that maybe supports:
Much more data intensive tests
Better handles integration tests
Strong support for test parallelization and even test run sharding in CI
Could help write characterization tests with a record/replay kind of model against existing systems (I’d *love* to have this at work)
Has some kind of model that is easy to use within an IDE like Rider or VS, even if there is a separate UI like Storyteller does today
And I’d still like to rewrite a subset of the existing Storyteller UI as an excuse to refresh my front end technology skillset.
To be honest, I don’t feel like Storyteller has ever been much of a success, but it’s the OSS project of mine that I’ve most enjoyed working on and most frequently used myself.
Weasel
Weasel is a set of libraries for database schema migrations and ADO.Net helpers that we spun out of Marten during its V4 release. I’m not super excited about doing this, but Weasel is getting some sort of database migration support very soon. Weasel isn’t documented itself yet, so that’s the only major plan other than supporting whatever Marten and/or Jasper needs this year.
Baseline
Baseline is a grab bag of helpers and extension methods that dates back to the early FubuMVC project. I haven’t done much with Baseline in years, and it might be time to prune it a little bit as some of what Baseline does is now supported in the .Net framework itself. The file system helpers especially could be pruned down, but then also get asynchronous versions of what’s left.
StructureMap
I don’t think that I got a single StructureMap question last year and stopped following its Gitter room. There are still plenty of systems using StructureMap out there, but I think the mass migration to either Lamar or another DI container is well underway.
Continuing my series about automated testing. I’m wrestling quite a bit right now with the tooling for integration testing both at work and in some of my more complicated OSS projects like Marten or Jasper. I happily use xUnit.Net for unit testing on side projects, and we generally use NUnit at work. Both tools are well suited for unit testing, but lack something to be desired for integration testing in my opinion. At the same time, one of my long running OSS projects is Storyteller, which was originally meant as a Behavior Driven Development (BDD) tool (think Gherkin tools or the much older FitNesse tooling), but really turned out to mostly be advantageous for big, data intensive integration testing.
To paraphrase Miracle Max, Storyteller isn’t dead, it’s just mostly dead. Storyteller never caught on, the React UI is a bazillion versions out of date, buggy as hell, and probably isn’t worth updating. I’m busy with other things. Gherkin/Cucumber tools suck all the oxygen out of the room for alternative approaches to BDD or really even just integration testing. Plus our industry’s zombie like fixation on trying to automate all testing through Selenium is absolutely killing off all the enthusiasm for any other automated testing techniques — again, just my personal opinion.
However, I still want something better than what we have today, and there were some useful things that Storyteller provided for automated testing that I still want in automated testing tools. And of course there are also some things that I’d like to have where Storyteller fell short.
Things that I thought were valuable in Storyteller:
Rendering the test results as HTML with failures inline helps relate test failures to test inputs, expectations, or actions
BDD tests are generally expressed through a mix of “flow based” expressions (think about the English-like Given/When/Then nomenclature of Gherkin specifications) and “table based” testing that was very common in the older FIT/FitNesse style of BDD. A lot of data intensive problem domains can be best tested through declarative “table-driven” tests. For example, consider insurance quoting logic, or data transformations, or banking transactions where you’re pushing around a lot of data and also verifying matrices of expected results. I still very strongly believe that Storyteller’s focus on example tables and set verifications is the right approach for these kinds of problem domains. The example tables make the expression of the tests be both very declarative and readily reviewable by domain experts. The set verification approach in Storyteller is valuable because it will show you which values are missing or unexpected for easy test failure diagnosis. Table-driven testing is somewhat supported in the Gherkin specification, but I don’t think that’s well utilized in that space.
Being able to embed system diagnostics and logging directly into the test results such that the application logs are perfectly correlated to the integration test running has been very advantageous. As an example, in Jasper testing I pipe in all the system events around messages being sent, received, and executed so that you can use that data to understand how any given test behaved. I’ve found this feature to be incredibly helpful in solving the inevitable test failures.
Like many integration testing tools, Storyteller generally allows you to evaluate all the assertions of a long running test even after some condition or action has failed. This is the opposite of what we’re taught for fine-grained unit testing, but very advantageous in integration testing where a scenarios run very slowly and you want to maximize your feedback cycle. That approach can also easily lead to runaway test runs. Picking on Selenium testing yet again, imagine you have an integration test that uses Selenium to pull open a certain page in a web application and then verify the expected values of several screen elements. Following Selenium best practices, you have some built in “waiters” that try to slow down the test until the expected elements are visible on the screen. If the web application itself chokes completely on the web page, your Selenium heavy test might very easily loop through and timeout on the visibility of every single expected element. That’s slow. Even worse — and I’ve seen this happen in multiple shops — what if the whole web application is down, but each and every Selenium heavy test still runs and repeatedly times out all the various “waiters” in the test? That’s a hung build that can run all night (again, been there, done that). To that end, Storyteller has the concepts of “critical” or “catastrophic” errors in the test engine. For example, if you were using Storyteller to drive Selenium, you could teach Storyteller to treat the failure to load a web page as a “critical” exception that will stop the current test from continuing so you can “fail fast”. Likewise, if the very home page of the web application can’t be loaded (status code 500 y’all), you can have Storyteller throw a “catastrophic” exception that will pull the cord on the whole test suite run and stop all test executions regardless of any kind of test retry policy. Fail fast FTW!
Storyteller did a lot to make test data set up be as declarative as possible. I think this is hugely valuable for data-intensive problem domains like basically any enterprise application.
Targeted test retries in CI. You have to opt into retries on a test by test basic in Storyteller, and I think that was the right decision as opposed to letting every test failure get retried in CI.
Something I stole years ago from a former colleague at ThoughtWorks, Storyteller differentiates between tests that are “Acceptance” tests in the development lifecycle and tests that are labeled as “Regression” — meaning that those tests absolutely have to pass in CI while “Acceptance” tests are known to be a work in progress. I think that workflow is valuable for doing BDD style testing where the tests are specifications about how the system *should* behave.
Storyteller had a “step through” mode where you could manually step through the specification at execution time much like you would regular code in a debugger. That was hugely valuable.
Storyteller kept performance data about individual test steps as part of the test results, and even allowed you to specify performance thresholds that could fail a test if the performance did not satisfy that threshold. That’s not to say Storyteller specification were anything more than a good complement to real load or performance testing, but it was still very helpful to diagnose long running tests and very frequently identified real application performance bottlenecks.
Things that weren’t good about Storyteller, and you should do better:
The IDE integration was nonexistent. At a bare minimum you need easy ways to run individual or groups of specifications at will from your IDE for a quick feedback cycle. The best I ever did with Storyteller was an xUnit.Net bridge that was so so. Maybe the new “dotnet test” specification could help here
It’s a Gherkin world and the rest of us just live in it. If there was a serious attempt to reboot Storyteller, it absolutely has to be Gherkin compatible. Think there would be Storyteller customizations as well though, and I despise the silly Given/When/Then handcuffs. Any new Storyteller absolutely has to allow devs to efficiently build and run new specifications without having to jump into an external tool of some sort
It’s got to be more asynchronous code friendly because that’s the world we live in
I’ve got a lot more notes about specific use cases I’ll have to dig out later.
What am I going to do?
For Jasper & Marten where there’s no quick win to replace Storyteller, I think I might cut a quickie Storyteller v6 that updates everything to .Net 5/6 and makes the testing framework much more asynchronous code friendly as a short term thing.
Longer term, I don’t know. At work I think the best approach would be to convince myself to like SpecFlow and possibly add some Storyteller functionality as addons to SpecFlow for some of its missing functionality. I’ve got worlds of notes about a rebooted Storyteller or maybe a completely different approach I’ve nicknamed “Bobcat” that would be an xUnit-like tool that’s just very optimized for integration testing (shared setup data, teardown, smarter heuristics for parallelizing tests). I’m also somewhat curious to see if the rebooted Fixie could be molded into a better tool for integration testing.
Honestly, if a newly rebooted Storyteller happens, it’ll be an opportunity for me to refresh my UI/UX skills.
I’m strictly talking about automated testing in this post. I’m more or less leading an effort at work to improve our test automation and Test Driven Development practices at work, so I’ll be trying to blog quite a bit about related topics in the next couple months. After reviewing quite a bit of in flight code, I think I’ll try to revisit some of my old blog posts on testability design from the CodeBetter days and update those old lessons from the early days of TDD to what we’re building now.
My company builds and maintains several long running software systems with a healthy back log of feature requests, performance improvements, and stories to retire technical debt. All that is to say that we’re constantly adding to or improving existing code — which implies we’re always running some non-zero risk of creating regression defects. To keep everybody’s stress levels down, we’re taking incremental steps toward a true continuous delivery model where we can smoothly and consistently build and deploy fully tested features while being confident that we aren’t introducing regression defects.
As you’d likely guess, we’re very interested in improving our automated testing practices as a safety net to enable continuous delivery while also improving our quality in general. That leads to the next question, what kind of automated testing should we be doing? Followed by, is there automated testing we’re doing today that isn’t delivering enough bang for the buck?
To that point, let’s take a look at the classic idea of the testing pyramid at some point, as shown below:
The thinking behind the testing pyramid is that there’s a certain, healthy mix of different sorts of automated tests that efficiently lead to better results. I say a “mix” here because unit tests, though relatively cheap compared to other tests, cannot detect many defects that only come out during integration between components, code modules, or systems. From a quick search, I found worlds of memes along the lines of this one:
No integration tests, but all the unit tests pass!
To address exactly what kind of automated tests we should be writing, here’s a stream of consciousness brain dump that I later organized with a patina of organization:
On End to End User Interface Tests
Any kind of test that uses a tool like Selenium to do end to end, black-box testing is going to run slowly. These tests are also frequently be unstable because of asynchronous timing issues in modern browser applications. There’s an unhealthy tendency in many shops who adopt Selenium as a test automation solution to use it as their golden hammer to the exclusion of other testing techniques that can be much more efficient in certain circumstances. To put it bluntly, it’s very difficult to successfully author and maintain test automation suites based on Selenium against complicated applications. In my experience in shops that have attempted large scale Selenium usage, I do not believe that the benefits of those tests have ever outweighed the costs.
I would still recommend using some small number of end to end tests with a tool like Selenium, but those tests should be focused on proving out integration mechanisms between a user interface and backing server side code. For example, I’ve been working on a new integration of Open Id Connect (OIDC) authentication into our web services and web applications. I’ve used Playwright to automate browser testing to prove out the interactions and redirects between the OIDC service and our applications or services.
I also find Cypress.io interesting, but more for doing integration testing of our Angular applications by themselves with a dummy backend. For true end to end testing of .Net-backed web applications, I think I’m interested in replacing Selenium from here on out with Playwright as I think and hope it just does much more for you to make performant and reliable automated tests compared to Selenium.
Driving a browser should not be used to automate functional testing of business logic or data services or any kind of data analysis that could possibly be tested without using the full browser.
If you insist on trying to do a lot of browser automation testing, you better invest in collecting diagnostic information in test runs that can be used by developers to debug test failures. Ideally, I like to have the application’s log output correlated to the test run somehow. I’ve worked with teams that were able to pipe the console.log() tracing from the JavaScript code running in the browser to the test results and that was extremely helpful. Taking screenshots as part of the test can certainly help. As another ideal, I very strongly recommend that any kind of browser automation tests be executable by developers on their local machine on demand for easier debugging. More on this later.
Again, if you absolutely have to write Selenium/Playwright/Cypress tests despite all of my warnings, I strongly recommend you write those tests in the same programming language as the real application. That statement is going to be controversial if any real test automation engineers stumble into this post, but I think it’s important to make it as easy as possible for developers to collaborate with test automation engineers. Moreover, I despise the kind of shadow data access layers you can get from test automation code doing their own thing to write to and read from the underlying data store of the system under test. I think it’s less likely to get that kind of insidious, hidden code duplication if the test code is written in the same programming language and even uses the system’s own data access code to set up or verify database state as part of the automated tests.
Choosing Solitary/Unit Tests or Sociable/Integration Tests
I missed out on this when it was first published, but I think I like the nomenclature of solitary vs sociable tests better than thinking about unit vs integration tests. I also encourage folks to think of that as a continuum rather than a hard categorization. Moreover, I recommend that you switch between solitary and sociable tests even within the same test library where one or the other is more effective.
I would recommend organizing tests by functional area first, and only consider separating out integration tests into a separate testing project when it’s advantageous to use a “fast test, slow test” division for more efficient development.
We have formal requirements for test coverage metrics in our continuous integration builds, so I’d definitely make sure that any integration tests count toward that coverage number.
I think an emphasis on always writing classical unit tests can easily create a strong coupling between the production code and your testing code. That can and will reduce your ability to evolve your code, add new functionality, or do performance optimizations without rewriting your tests.
In many cases, integration tests that start at a natural sub-system facade or a logical controller/conductor entry point will do much better for you as a regression safety net to allow you to refactor your code to allow for new behavior or do important performance optimizations.
Case in point, I relied strictly on fine grained unit tests in my early work in StructureMap, and I definitely felt the negative consequences of that approach (I gave a talk about it in 2008 that’s still relevant). With later releases of StructureMap and now with Lamar, I lean much more heavily on integrated acceptance tests (let’s go ahead and call it Behavior Driven Development) that test from the entry point of the library down and focus on user-centric scenarios. I feel like that testing approach has led to much better results — both in the ease of adding new features, detecting regression defects in automated builds, and allowing me to evolve the functionality of the library.
On the other hand, integration tests can be harder to troubleshoot when they fail because you have more ground to cover. They also run slower of course. If you find that your feedback cycles feel too slow to efficiently run the tests continuously or especially if you find yourself doing long, marathon sessions in your debugger, stop and consider introducing more fine-grained tests first.
Running the Tests Locally vs Remotely
To the previous point, I think it’s critical that developers should be able to easily spin up and run automated integration tests on demand on their local development boxes. Tests will fail, and being able to easily troubleshoot a failing test is a prerequisite for successful test automation. If you can run an integration test locally, you’re much more likely to be able to iterate and try potential fixes quickly. There’s also the very real possibility of attaching a debugger to the testing process.
I think that our current technology set makes it much easier to do integration testing than it was when I was first getting started and the strict Michael Feathers definition of a unit test was in vogue. Just speaking from my own experience, the current .Net 5 generation is very easy to spin up and down in process for automated testing. Docker has been a great way to stand up development environments using Sql Server, Postgresql, Rabbit MQ, and other infrastructural tools.
As a follow up to the previous section, it’s also advantageous for automated tests to be able to run in process with the test harness code. For instance, I’d much rather do Alba testing of HTTP endpoints in .Net 5 where I’m able to quickly spin up an actual web service in memory and shut it down from my testing project. As opposed to the old, full .Net framework where you’d have to run the web service project in IIS or IISExpress first, then use HttpClient to address the service from your unit tests. The first, .Net 5/Alba approach is a much faster iteration and feedback cycle to support a Test Driven Development workflow than the 2nd approach.
Likewise, when given a choice between tests that can be run locally versus tests that can only be executed in a remote server location, give me the local tests every time. When and if you hit a scenario where you really need to run tests remotely *cough* serverless *cough*, that’s the one and only exception I can think of to my “never deploy from your local development box” rule. If depending on remote execution of tests, I’d at least want the ability to send my local development branch to the remote server at will. Just having a CI server build out pull request branches might get you there of course, but then you might be dependent upon being about to run that test suite in parallel with other CI builds. That’s not a show stopper, but it might make you have to invest more in your build automation to spin up isolated environments on demand.
Apollo Testing!
There’s plenty of debate over what the actual ration of UI tests to integration tests to unit tests should be, and plenty of folks have different metaphors than a “pyramid” to describe what they thing the ratio should be. I happen to like the integration test heavy ratio described in The Testing Trophy and Testing Classifications with the graphic below:
So from now on, I’m calling our intended testing approach the Apollo Testing Method!
What is the purpose of testing?
I’m just barely old enough that I started my official software development career in old fashioned waterfall models. In those days we did some unit testing with ad hoc testing tools to troubleshoot new code, but it wasn’t anywhere close to what developers do today with Test Driven Development and xUnit tools. As developers, we mostly ran the complete application on our development boxes and stepped through things manually to check out new code locally before throwing things over the wall to QA at the end of the project.
Regardless of whatever ad hoc, local testing developers did of their code locally, the only official testing that actually counted was the purely manual testing done by our testers in the testing environment that was supposed to exactly mimic the production environment (it never quite did, but that’s a story for another day). The QA team strictly used black-box testing with some direct access to the underlying database.
That old black-box testing approach at the end of the project was a much slower feedback cycle than we’re accustomed to today after the advent of Agile Software Development. The killer problem was that the testing feedback cycles were too slow to consider evolutionary design approaches because of the real fear of regression failures. It was also harder as a developer to address defects found in the testing cycle because you were frequently needing to work with code you hadn’t touched in many months that certainly wasn’t fresh in your mind. That frequently led to marathon debugging sessions while a helpful project manager came by your cubicle to cheerfully ask for any updates several times a day and crank up the pressure. As a developer you were also completely at the mercy of QA for information about what was really happening in the system when they found bugs.
In my mind, the most important element of Agile software development overall was the emphasis on improving feedback cycles. Faster feedback allowed
Testing is not about proving that our code works perfectly so much as a way to find and remove enough problems from the code that it can be deployed to production. I think this is an important approach because it allows us to use faster, finer grained testing approaches like isolated unit testing or intermediate level white-box integration tests that are generally faster running and cheaper to build than classic black-box, end to end tests.
What’s Next?
My organization has started an effort to introduce much more integration testing into our development processes as a way of improving quality and throughput. To help out on that, I’m going to attempt to write a series of blog posts going into specific areas about tools and techniques, but for right now I’m just jotting down this stream of consciousness brain dump to get started.
Based on what I think we need to establish at work, I’m thinking to cover:
.Net IHost bootstrapping and lifecycle within xUnit.Net or NUnit. I’m much more familiar with xUnit.Net from recent development, but we mostly use NUnit at work so I’ll be trying to cover that base as well.
HTTP API testing, which will inevitably feature Alba
Dealing with databases in tests, and that’s gonna have to cover both RDBMS databases and probably Mongo Db for now
Message handler testing with MassTransit and NServiceBus (we use both in different products)
Another brain dump on doing end to end testing after a meeting today about the CI of one of our big systems.
How should automated testing be integrated into the development cycle, and who should be responsible for these tests, and why is the obvious answer a very close collaboration between testers, developers, and even business experts
This will be a bigger stretch for me, but maybe get into how to do some semi-integration testing of an Angular front end with NgRX.
After talking through some of our issues with test automation at work, I think I’d like to blog about some of the positive things we did with Storyteller. I’ve been increasingly frustrated with xUnit.Net (and don’t think NUnit would be much better) for integration testing, so I’ve got quite a bit of notes about what an alternative tool optimized for integration tests could look like I wouldn’t mind publishing.
It’s now a yearly thing for me to blog about my aspirations and plans for various OSS projects at the beginning of the year. I was mostly on the nose in 2018, and way, way off in 2019. I’m hoping and planning for a much bigger year in 2020 as I’ve gotten much more enthusiastic and energetic about some ongoing efforts recently.
Most of my time and ambition next year is going toward Jasper, Marten, and Storyteller:
Jasper
Jasper is a toolkit for common messaging scenarios between .Net applications with a robust in process command runner that can be used either with or without the messaging. Jasper wholeheartedly embraces the .Net Core 3.0 ecosystem rather than trying to be its own standalone framework.
Jasper has been gestating for years, I almost gave up on it completely early last year, and purposely set it aside until after .Net Core 3.0 was released. However, I came back to it a few months ago with fresh eyes and full of new ideas from doing a lot of messaging scenario work for Calavista clients. I’m very optimistic right now about Jasper from a purely technical perspective. I’m furiously updating documentation, building sample projects, and dealing with last minute API improvements in an effort to kick out the big v1.0 release sometime in January of 2020.
Marten
Marten is a library that allows .Net developers to treat the outstanding Postgresql database as both a document database and an event store. Marten is mostly supported by a core team, but I’m hoping to be much more involved again this year. The big thing is a proposed v4 release that looks like it’s mostly going to be focused on the event sourcing functionality. There’s an initial GitHub issue for the overall work here, and I want to write a bigger post soon on some ideas about the approach. There’s going to be some new functionality, but the general theme is to make the event sourcing be much more scalable. Marten is a team effort now, and there’s plenty of room for more contributors or collaborators.
For some synergy, I’m also planning on building out some reference applications that use Jasper to integrate Marten with cloud based queueing and load distribution for the asynchronous projection support. I’m excited about this work just to level up on my cloud computing skills.
Storyteller
Storyteller is a tool I’ve worked on and used for what I prefer to call executable specification in .Net (but other folks would call Behavior Driven Development, which I don’t like only because BDD is overloaded). I did quite a bit of preliminary work last year on a proposed Storyteller v6 that would bring it more squarely into the .Net Core world, I wrote a post last year called Spitballing the Future of Storyteller that laid out all my thoughts. I liked where it was heading, but I got distracted by other things.
For more synergy, Storyteller v6 will use Jasper a little bit for its communication between the user interface and the specification process. It also dovetails nicely with my need to update my Javascript UI skillset.
Smaller Projects
Lamar — the modern successor to StructureMap and ASP.Net Core compliant IoC container. I will be getting a medium sized maintenance release out very soon as I’ve let the issue list back up. I’m only focused on dealing with problems and questions as they come in.
Alba — a library that wraps TestServer to make integration testing against ASP.Net Core HTTP endpoints easier. The big work late last year was making it support ASP.Net Core v3. I don’t have any plans to do much with it this year, but that could change quickly if I get to use it on a client project this year.
Oakton — yet another command line parser. It’s used by Jasper, Storyteller, and the Marten command line package. I feel like it’s basically done and said so last year, but I added some specific features for ASP.Net Core applications and might add more along those lines this year.
StructureMap — Same as last year. I answer questions here and there, but otherwise it’s finished/abandoned
FubuMVC — A fading memory, and I’m pleasantly surprised when someone mentions it to me about once or twice a year
I just made a little tactical release of Storyteller v5.3.5 (it took a couple “fix” releases to really knock things out) that at least addresses the critical Nuget dependency issues users were experiencing against the latest versions. While in the code, it was quickly obvious that the Storyteller codebase was in some serious need of refurbishing and modernization. Hence, this post laying out some envisioning for the next wave of Storyteller development.
Storyteller is an OSS behavior driven development / executable specifications / integration testing tool I’ve worked on and led in some form or another for years. The obvious comparison is to Cucumber-based tools (like SpecFlow in the .Net world), but Storyteller was much more influenced by FitNesse and Ward Cunningham’s original FIT library from way back. While Cucumber has sucked up almost all the Oxygen in the room for tools like this, I think Storyteller’s model has some significant advantages over Cucumber tools for more data-intensive scenarios and does a lot more to help you tackle more complicated integration testing scenarios.
It’s never been super successful in terms of adoption or mindshare, but I and others do use it successfully. I personally enjoy working on Storyteller because it’s the only significant UI/UX work I get to do (my various day jobs have all wisely kept me out of any kind of UI design for the past decade).
Sometime later this year I’d like to turn my attention back to Storyteller to:
Overhaul and modernize the user interface. There’s definitely some room for ease of use improvements. There’s also some missing features that would help for the next bullet. Mostly though, it’s a way for me personally to level up on client side development as it’s been a couple years now since I’ve done any substantial Javascript work
Improve the usability of Storyteller for non-developers and make Storyteller work better throughout the entire software development lifecycle. Storyteller today is very oriented toward technical developers and automated testing more than true Behavior Driven Development as a requirements communication and capture mechanism
Find ways to parallelize specification execution. Storyteller specifications today have to run single file, and bigger suites of heavy integration tests have proven to be very slow to run in real usage (it’s not Storyteller itself so much as things like database access and any usage of Selenium). I’d like to explore some possible ways to parallelize execution in CI pipelines. More on this later in the post.
I’d love to attract some other contributors or folks that would be willing to play with early versions and give feedback. I’d especially love help and feedback on any new user interface work.
Storyteller’s Current Architecture
If you use Storyteller’s interactive user interface today in its latest incarnation (v5), there are three processes running including the browser. Here’s a quickie visual representation of the current architecture:
The Specification Project
The actual Storyteller specifications project is analogous to an xUnit.Net/NUnit/MSTest project in that it holds all the test fixture code and specifications (tests). In Storyteller v5, this project is a console application that delegates to Storyteller in its Project.Main() entry point method to perform any kind of application set up, tear down, and Storyteller configuration you may need.
This project probably has references to your actual application assemblies. In the case of an ASP.Net Core system, this might completely bootstrap and run your entire application. It also includes your Storyteller Fixture classes that sit in between the specifications and your application code.
This executable is all you need to run Storyteller specifications from the command line as you would in continuous integration builds. This same application runs as a test execution “agent” in a buddy process to the dotnet storyteller process when you’re executing specifications from the interactive specification runner. The dotnet storyteller process starts and stops the Specification project process so you can rebuild the system under test without having to stop and restart the Storyteller UI.
Offhand, I don’t think that the Fixture model will change too much in a new version and I think I’d like it to be a goal that your existing Fixture class code would compile immediately after an upgrade. I am very interested in doing a significant overhaul to how Storyteller bootstraps or shuts down the system under test and other environmental set up actions. So far I’ve identified a few opportunities for improvement:
I bolted the async method behavior on to the Fixture model later on, and that shows. As part of the bullet point above, I want to do a big simplification of the actual specification execution internals
A facility to start and stop arbitrary command line operations as part of bootstrapping. For an example, I have a project starting soon in an existing system where we’ll have to use IISExpress for hosting the web application locally, and I’m hoping this ability would facilitate full stack integration testing of that system by starting letting Storyteller manage the IISExpress process
dotnet storyteller is a separate executable that is added to your project today through the dotnet tool extensibility. This tool runs a small ASP.Net Core application hosted locally and served via Kestrel (a “backend for frontend”). All of the client side assets (minus some on CDN’s) are embedded resources within this executable. This process communicates with the browser front end through JSON messages sent via web sockets. The communication with the running specification “buddy” process is done through JSON messages sent through raw sockets.
Honestly, more of the evident improvements will be in the actual user interface, but there’s a few things I’d like to do in the “Backend for Frontend” AspNetCore application:
Incorporate Jasper for both the HTTP handling, an in-memory command processor, and the communication with the Specification process through sockets. Mostly this is a way to prove out Jasper, but it would also remove quite a bit of one-off code in Storyteller today.
Possibly convert this to being a global tool rather than using it as a local dotnet tool.
Maybe consider making this application be an Electron application? I’ve done enough research to know that’s feasible.
Storyteller Editor Browser Application
The actual Storyteller client running in the browser is a fairly complicated React/Redux application. After the initial requests for the HTML and client assets, all other communication between the browser application and the ASP.Net Core backend is through JSON messages sent via web sockets.
The current stack is:
React.js v14 — the UI was started in v11, and you can unfortunately see a lot of different styles of building React.js components as React itself was churning so hard
Redux + react-redux — I like this combination, especially on the receiving end of web sockets. This was all retrofitted in after the application work had started and I had some growing pains with this approach. I think the Redux work could be much simpler with a redo
Webpack — it works great when it’s all set up, but it’s a brutal tool to use for someone like me who only moonlights in the JS world once in a while
Immutable.js — It did what it was supposed to do, and I think it works pretty well in combination with Redux
Postal.js — I think it was a great event aggregator in its day, but most of what it originally did in a homegrown Flux implementation was later subsumed by Redux
react-bootstrap — Former colleagues of mine were active in this project at the time of Storyteller v3 development when the UI was rebuilt, and it was a natural fit
Mocha/Chai/Karma for testing
I very briefly looked at possibly incorporating Blazor as the user interface tooling, but it’s model just doesn’t appeal much to me and it won’t have a huge amount of mindshare in the near future. I guess that WPF would be more viable in the .Net Core 3.0 stack, but I’ve never cared for it. Right now I’m leaning very heavily toward continuing to develop the user interface as a browser based application primarily built around React + Redex.
My current thinking about a future web stack is:
React.js vLatest — I personally like React.js, and there’s plenty of usable code in the existing application that I don’t feel it’s justified to switch to Vue.js or anything else at this point
Redux + react-redux — I looked at MobX and it’s interesting, but I actually like Redux and there’s existing code. I’m not buying into React’s Context API for everything
Parcel.js — I don’t think Storyteller needs all the functionality of Webpack, and I’ve been very impressed with what I’ve seen with Parcel.js so far in admittedly limited prototyping
Reactstrap or Material UI — I think that it would be easier to move to Reactstrap because the existing UI is built around Bootstrap and there are so many existing Bootstrap themes, but I like the editor support better in Material UI at a glance. I think I’m ever so slightly leaning toward Material UI and I’d love to hear from other folks.
Jest + Enzyme for testing. Time to modernize, and I’d really like to leave Karma behind. I think I’d happily continue to use Chai though. I’d really like to be more familiar with the most recent approaches to testing React components before I need to oversee real client side development at work
Typescript? I don’t think it’s absolutely necessary, but it would have helped the first time around in the more complicated data structures and the Redux reducers. Mostly this would be a chance for me to get into TypeScript I think.
Headless or Review Mode
Today you pretty well have to run your specification project to be working with Storyteller at all. That’s fine for developers who would naturally have all the prerequisites for the system under test on their box and be comfortable working with the code. That isn’t a great situation for the mass majority of testers and absolutely not at all good for non technical business experts.
For Storyteller v4, a couple former colleagues and I built some functionality where you could define all new grammar/fixture language for your project in a specialized markdown format, then be able to write specifications using the interactive editor using those stubbed grammars.
As an alternative to running fully connected against the “system under test”, I’d like Storyteller to also have a “headless mode” that would allow you to review and edit specifications, but not have to actually run the application. That architecture would look like this:
In this mode, Storyteller could run without the actual specification project process, so you’d need absolutely nothing but a web browser and the dotnet storyteller application running. You’d have to previously export the definition of the Fixture/Grammar language for your system under test to Storyteller-flavored Fixture markdown files.
As an important follow up to that headless mode, I really want to embed “language designers” directly into the Storyteller UI that would allow users to make up fixture/grammar language usage on the fly.
Storyteller already has some exposed functionality to generate the C# code for missing grammars and fixtures. My hope is that the combination of the headless mode, being able to define the specification language any time within the editor, and finally being able to generate skeleton code to match that language will hugely improve a user’s ability to use Storyteller as a requirements elicitation tool in addition to being an integration testing tool.
Use a model very similar to xUnit.Net where you can mark Fixture classes by whether they’re completely stateless or somehow “know” what fixtures can run simultaneously. The engine would then “know” how to schedule and parallelize executions
In the Storyteller bootstrapping, have some way to effectively set up multiple specification runners in the specification project. You might have to do some extra work in your setup to opt into this model. Things like using different database schemas per runner or other stateful resources
Docker all the things! For really big and slow specification suites, what if you could use something like an Azure Elastic Job to temporarily put out a whole bunch of parallel Storyteller specification runs, farm work out to all these runners, and combine the results in one place for an effective CI run. I’m assuming Docker would come into play as a way to spin up Storyteller agents.
What next?
Honestly, I need to get busy with Marten’s backlog first, but I really wanted to get some of these ideas out and onto paper, so to speak. I’d really like to gather as much feedback as possible from Storyteller’s current userbase and maybe try to attract some new folks.
EDIT 3/12: All these tests are fixed, and it wasn’t as bad as I’d thought it was going to be, but the extra logging and faster change code/run test under debugger cycle definitely helped.
This was meant to be a short post, or at least an easy to write post on my part, but it spilled out from integration testing and into some Storyteller mechanics, semi-advanced xUnit.Net usage, ASP.Net Core logging integration, and even a tepid defense of compositional architectures wrapped around an IoC container.
I’ve been working feverishly the past couple of months to push Jasper to a 1.0 release. As (knock on wood) the last big epic, I’ve been working on a large overhaul and redesign of the message persistence behind Jasper’s durable messaging. The existing code was fairly well covered by integration tests, so I felt confident that I could make the large scale changes and use the big bang integration tests to ensure the intended functionality still worked as designed.
I assume that y’all can guess how this has turned out. After a week of code changes and fixing any and all unit test and intermediate integration test failures, I got to the point where I was ready to run the big bang integration tests and, get this, they didn’t pass on the first attempt! I know, shocking right? Moreover, the tests involve all kinds of background processing and even multiple logical applications (think ASP.Net Core IWebHost objects) being started up and shut down during the tests, so it wasn’t exactly easy to spot the source of my test failures.
I thought it’d be worth talking about how I first stopped and invested in improving my test harness to make it faster to launch the test harness and to capture a lot more information about what’s going on in all the multithreading/asynchronous madness going on but…
First, an aside on Debugger Hell
You probably want to have some kind of debugger in your IDE of choice. You also want to be reasonably good using that tool, know how to use its features, and conversant in its supported keyboard shortcuts. You also want to try really hard to avoid needing to use your debugger too often because that’s just not an efficient way to get things done. Many folks in the early days of Agile development, including me, described debugger usage as a code or testing “smell.” And while “smell” is mostly used today as a pejorative to put down something that you just don’t like, it was originally just meant as a warning you should pay more attention to in your code or approach.
In the case of debugger usage, it might be telling you that your testing approach needs to be more fine grained or that you are missing crucial test coverage at lower levels. In my case, I’ll be looking for places where I’m missing smaller tests on elements of the bigger system and fill in those gaps before getting too worked up trying to solve the big integration test failures.
Storyteller Test Harness
For these big integration tests, I’m using Storyteller as my testing tool (think Cucumber, but much more optimized for integration testing as opposed to being cute). With Storyteller, I’ve created a specification language that lets me script out message failover scenarios like the one shown below (which is currently failing as I write this):
In the specification above, I’m starting and stopping Jasper applications to prove out Jasper’s ability to fail over and recover pending work from one running node to another using its Marten message persistence option. At runtime, Jasper has a background “durability agent” constantly running that is polling the database to determine if there is any unclaimed work to do or known application nodes are down (using advisory locks through Postgresql if anybody would ever be interested in a blog post about just that). Hopefully that’s enough description just to know that this isn’t particularly an easy scenario to test or code.
In my initial attempts to diagnose the failing Storyteller tests I bumped into a couple problems and sources of friction:
It was slow and awkward mechanically to get the tests running under the debugger (that’s been a long standing problem with Storyteller and I’m finally happy with the approach shown later in this post)
I could tell quickly that exceptions were being thrown and logged in the background processing, but I wasn’t capturing that log output in any kind of usable way
Since I’m pretty sure that the tests weren’t going to get resolved quickly and that I’d probably want to write even more of these damn tests, I believed that I first needed to invest in better visibility into what was happening inside the code and a much quicker way to cycle into the debugger. To that end, I took a little detour and worked on some Storyteller improvements that I’ve been meaning to do for quite a while.
Incorporating Logging into Storyteller Results
Jasper uses the ASP.Net Core logging abstractions for its own internal logging, but I didn’t have anything configured except for Debug and Console tracing to capture the logs being generated at runtime. Even with the console output, what I really wanted was all the log information correlated with both the individual test execution and which receiver or sender application the logging was from.
Fortunately, Storyteller has an extensibility model to capture custom logging and instrumentation directly into its test results. It turned out to be very simple to whip together an adapter for ASP.Net Core logging that captured the logging information in a way that can be exposed by Storyteller.
You can see the results in the image below. The table below is just showing all the logging messages received by ILogger within the “Receiver1” application during one test execution. The yellow row is an exception that was logged during the execution that I might not have been able to sense otherwise.
For the implementation, ASP.Net Core exposes the ILoggerProvider service such that you can happily plug in as many logging strategies as you want to an application in a combinatorial way. On the Storyteller side of things, you have the Report interface that let’s you plug in custom logging that can expose HTML output into Storyteller’s results.
public class StorytellerAspNetCoreLogger : Report, ILoggerProvider
The actual logging just tracks all the calls to ILogger.Log() as little model objects in memory:
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter)
{
var logRecord = new LogRecord
{
Category = _categoryName,
Level = logLevel.ToString(),
Message = formatter(state, exception),
ExceptionText = exception?.ToString()
};
// Just keep all the log records in an in memory list
_parent.Records.Add(logRecord);
}
Fortunately enough, in the Storyteller Fixture code for the test harness I bootstrap the receiver and sender applications per test execution, so it’s really easy to just add the new StorytellerAspNetCoreLogger to both the Jasper applications and the Storyteller test engine:
var registry = new ReceiverApp();
registry.Services.AddSingleton<IMessageLogger>(_messageLogger);
var logger = new StorytellerAspNetCoreLogger(key);
// Tell Storyteller about the new logger so that it'll be
// rendered as part of Storyteller's results
Context.Reporting.Log(logger);
// This is bootstrapping a Jasper application through the
// normal ASP.Net Core IWebHostBuilder
return JasperHost
.CreateDefaultBuilder()
.ConfigureLogging(x =>
{
x.SetMinimumLevel(LogLevel.Debug);
x.AddDebug();
x.AddConsole();
// Add the logger to the new Jasper app
// being built up
x.AddProvider(logger);
})
.UseJasper(registry)
.StartJasper();
And voila, the logging information is now part of the test results in a useful way so I can see a lot more information about what’s happening during the test execution.
It sucks that my code is throwing exceptions instead of just working, but at least I can see what the hell is going wrong now.
Get the debugger going quickly
To be honest, the friction of getting Storyteller tests running under a debugger has always been a drawback to Storyteller — especially compared to how fast that workflow is with tools like xUnit.Net that integrate seamlessly into your IDE. You’ve always been able to just attach your debugger to the running Storyteller process, but I’ve always found that to be clumsy and slow — especially when you’re trying to quickly cycle between attempted fixes and re-running the tests.
I made some attempts in Storyteller 5 to improve the situation (after we gave up on building a dotnet test adapter because that model is bonkers), but that still takes some set up time to make it work and even I have to always run to the documentation to remember how to do it. Sometime this weekend the solution for a quick xUnit.Net execution wrapper around Storyteller popped into my head and it honestly took about 15 minutes flat to get things working so that I could kick off individual Storyteller specifications from xUnit.Net as shown below:
Maybe that’s not super exciting, but the end result is that I can rerun a specification after making changes with or without debugging with nothing but a simple keyboard shortcut in the IDE. That’s a dramatically faster feedback cycle than what I had to begin with.
Implementation wise, I just took advantage of xUnit.Net’s [MemberData] feature for parameterized tests and Storyteller’s StorytellerRunner class that was built to allow users to run specifications from their own code. After adding a new xUnit.Net test project and referencing the original Storyteller specification project named “StorytellerSpecs, ” I added the code file shown below in its entirety::
// This only exists as a hook to dispose the static
// StorytellerRunner that is hosting the underlying
// system under test at the end of all the spec
// executions
public class StorytellerFixture : IDisposable
{
public void Dispose()
{
Runner.SpecRunner.Dispose();
}
}
public class Runner : IClassFixture<StorytellerFixture>
{
internal static readonly StoryTeller.StorytellerRunner SpecRunner;
static Runner()
{
// I'll admit this is ugly, but this establishes where the specification
// files live in the real StorytellerSpecs project
var directory = AppContext.BaseDirectory
.ParentDirectory()
.ParentDirectory()
.ParentDirectory()
.ParentDirectory()
.AppendPath("StorytellerSpecs")
.AppendPath("Specs");
SpecRunner = new StoryTeller.StorytellerRunner(new SpecSystem(), directory);
}
// Discover all the known Storyteller specifications
public static IEnumerable<object[]> GetFiles()
{
var specifications = SpecRunner.Hierarchy.Specifications.GetAll();
return specifications.Select(x => new object[] {x.path}).ToArray();
}
// Use a touch of xUnit.Net magic to be able to kick off and
// run any Storyteller specification through xUnit
[Theory]
[MemberData(nameof(GetFiles))]
public void run_specification(string path)
{
var results = SpecRunner.Run(path);
if (!results.Counts.WasSuccessful())
{
SpecRunner.OpenResultsInBrowser();
throw new Exception(results.Counts.ToString());
}
}
}
And that’s that. Something I’ve wanted to have for ages and failed to build, done in 15 minutes because I happened to remember something similar we’d done at work and realized how absurdly easy xUnit.Net made this effort.
Summary
Sometimes it’s worthwhile to take a step back from trying to solve a problem through debugging and invest in better instrumentation or write some automation scripts to make the debugging cycles faster rather than just trying to force your way through the solution
Inspiration happens at random times
Listen to that niggling voice in your head sometimes that’s telling you that you should be doing things differently in your code or tests
Using a modular architecture that’s composed by an IoC container the way that ASP.net Core does can sometimes be advantageous in integration testing scenarios. Case in point is how easy it was for me to toss in an all new logging provider that captured the log information directly into the test results for easier test failure resolution
And when I get around to it, these little Storyteller improvements will end up in Storyteller itself.
I wrote a similar post last year on My OSS Plans for 2018, and it wasn’t too far off what actually happened. I did switch jobs last May, and until recently, that dramatically slowed down my rate of OSS contributions and my ambition level for OSS work. I still enjoy building things, I’m in what’s supposed to be a mostly non-coding role now (but I absolutely still do), and working on OSS projects is just a good way to try to keep my technical skills up. So here we go:
Marten — I’m admittedly not super active with Marten these days as it’s a full fledged community driven project now. There has been a pile up of Linq related issues lately and the issue backlog is getting a bit big, so it really wouldn’t hurt for me to be more active. I happen to love Stephen King’s Dark Tower novels (don’t bother with the movie), but he used to complain that they were hard for him to get into the right head space to write more about Roland and his Ka-tet. That’s basically how I feel about the Linq provider in Marten, but it’s over due for some serious love.
Lamar (was BlueMilk) — Users are reporting some occasional memory usage problems that I think point to issues in Roslyn itself, but in the meantime I’ve got some workarounds in mind to at least alleviate the issue (maybe, hopefully, knock on wood). The one and only big feature idea for this year I have in mind is to finally do the “auto-factory” feature that I hope will knock out a series of user requests for more dynamic behavior.
Alba — I took some time at CodeMash this year and did a pretty substantial 3.0 release that repositioned Alba as a productivity helper on top of TestServer to hopefully eliminate a whole lot of compatibility issues with ASP.Net Core. I don’t know that I have any other plans for Alba this year, but it’s the one tool I work on that I actually get to use at work, so there might be some usability improvements over time.
Storyteller — I’d really love to sink into a pretty big rewrite of the user interface and some incremental — but perfectly backward compatible — improvements to the engine. After a couple years of mostly doing integration work, I suddenly have some UI centric projects ahead of me and I could definitely use some refresher on building web UIs. More on this in a later post.
Jasper — I think I’m finally on track for a 1.0 release in the next couple months, but I’m a little unsure if I want to wait for ASP.Net Core 3.0 or not. After that, it’s mostly going to be trying to build some community around Jasper. Most of my side project time and effort the past three years has been toward Jasper, I have conceptual notes on its architecture that go back at least 5 years, and counting its predecessor project FubuMVC, this has been a 10 year effort for me. Honestly, I think I’m going to finish the push to 1.0 just to feel some sense of completion.
I published the Storyteller 5.0 release last night. I punted on doing any kind of big user interface overhaul for now, and just released the back end improvements on their own with some vague idea that there’d be an improved or at least restyled user interface later this year.
The key improvements are:
Netstandard 2.0 support
An easier getting started story
Streamlined command line usage
Easier “F5 debugging” for specifications in your IDE
No changes whatsoever to your Fixture code from 4.0
Getting Started with Storyteller 5
Previous versions of Storyteller have been problematic for new users getting started and setting up projects with the right Nuget dependencies. I felt like things got a little better with the dotnet cli, but the enduring problem with that is how few .Net developers seem to be using it or familiar with it. When you use Storyteller 5, you need two dependencies in your Storyteller specification project:
A reference to the Storyteller 5.0 assembly via Nuget
The dotnet-storyteller command line tool referenced as a dotnet cli tool in your project, and that’s where most of the trouble come in.
To start up a new Storyteller 5.0 specification project, first make the directory where you want the project to live. Next, use the dotnet new console command to create a new project with a csproj file and a Program.cs file.
In your csproj file, replace the contents with this, or just add the package reference for Storyteller and the cli tool reference for dotnet-storyteller as shown below:
netcoreapp2.0
EXE
Next, we need to get into the entry point to this new console application change the Program.Main() method to activate the Storyteller engine within this new project:
public class Program
{
public static int Main(string[] args)
{
return StorytellerAgent.Run(args);
}
}
Internally, the StorytellerAgent is using Oakton to parse the arguments and carry out one of these commands:
------------------------------------------------------------------------------
Available commands:
------------------------------------------------------------------------------
agent -> Used by dotnet storyteller to remote control the Storyteller specification engine
run -> Executes Specifications and Writes Results
test -> Try to start and warmup the system under test for diagnostics
validate -> Use to validate specifications for syntax errors or missing grammars or fixtures
------------------------------------------------------------------------------
If you execute the console application with no arguments like this:
|> dotnet run
It will execute all the specifications and write the results to a file named “stresults.htm.”
You can customize the running behavior by passing in optional flags with the pattern dotnet run -- run --flag flagvalue like this example that just writes the results file to a different location:
|> dotnet run -- run Arithmetic -r ./artifacts/results.htm
If you’re not already familiar with the dotnet cli, what’s going on here is that anything to the right of the “–” double dash is considered to be the command line arguments passed into your application’s Main() method. The “run” argument tells the StorytellerAgent that you actually want to run specifications and it’s unfortunately not redundant and very much mandatory if you want to customize how Storyteller runs specifications.
Assuming that you’ve got the cli tools reference to dotnet-storyteller and you’ve executed `dotnet restore` at least once (compiling through VS.Net or Rider does this for you), the only thing you need to do to launch the specification editor tool is this from the command line:
|> dotnet storyteller
F5 Debugging
Debugging complicated Storyteller specifications has been its Achille’s Heel from the very beginning. You can always attach a debugger to a running Storyteller process, but that’s clumsy (quicker in Rider than VS.Net, but still). As a cheap but effective improvement in v5, you can run a single specification from the command line with this signature:
|> dotnet run -- run "Suite1 / ChildSuite1 / Specification Name"
This is admittedly pretty ugly, but remember that you can tell either Rider or VS.Net to pass arguments to your console application when your press F5 to run an application in debug mode. I utilize this quite a bit in Jasper development to troubleshoot individual specifications. Here’s what the configuration looks like for this in Rider:
See the “Program arguments” specifically. Once the path to the specification is configured, I can just hit F5 and jump right into a debugging session running just that specification.
We looked pretty hard at supporting the dotnet test tooling so you could run Storyteller specifications from either Visual Studio.Net’s or Rider/ReSharper’s test runners, but all I could think about after trying to reverse engineer xUnit’s tooling around that was a certain Monty Python scene.
Everything in this post is from a proof of concept project we did for the technique described here. We have not used this tooling on a real project yet, but we have a team starting a project where this might be useful, so I promised a write up for them.
In my previous post I laid out how I see the testing pyramid and test tool and technique choices against my company’s typical web application technology stack. As a reminder, our recommended stack for new development on web applications or API’s looks like this (plus a backing database):
Last week I talked through how we might test the React components and Redux store setup, including the interaction between Redux and React. I also talked about how we could go about testing the .Net backend both at a unit level and through integration tests through to the backing database. Lastly, I said we’d use a modicum of end to end, Selenium-based tests, but said that we should avoid depending on too many of those kinds of tests. That leaves us with a pretty big hole in coverage against the interaction between the Javascript code running in the browser and the .Net code and database interactions running server side.
As a possible solution for this gap, my team at work did a proof of concept for using Storyteller to do subcutaneous testing against the full application stack, but minus the actual React component “view layer.” The general idea is to use Storyteller with its Storyteller.Redux extension to host the ASP.Net Core application so that it can easily drive both test data input through the real data layer of the .Net code and then turn around and use the real system services to verify the state of the application and the backing database as the “assert” stage of the tests. The basic value proposition here is that this mechanism could be far more efficient in terms of developer time against its benefits compared to end to end, Selenium based testing. We’re also theorizing that the feedback cycles would be much tighter through faster tests and definitely more reliable tests than the equivalent tests against the browser every could be.
A couple things to note or argue:
This technique would be most useful if your React components are generally dumb and only communicate with the external world by dispatching well defined actions to the Redux store (I’m assuming that you’re utilizing Redux middleware like redux-thunk or redux-saga here).
Why Storyteller as the driver for this instead of another test runner? I’m obviously biased, but I think Storyteller has the very best story in test automation tooling for declarative set up and verification of system state. Plus, unlike any of the xUnit tools I’m aware of, Storyteller is built specifically with integration testing in mind (think configurable retries, bailing out on runaway tests, better control over the lifecycle of the test harness)
We’re theorizing that it’ll be vastly easier to make assertions against the Redux store state than it would to hunt down DOM elements with Selenium
The Storyteller.Redux extension subscribes to any changes to the store state and exposes that to the Storyteller test engine. The big win here is that it gives you a single mechanism to handle the dreaded “everything is asynchronous so how does the test harness know when it’s time to check the expected outcomes” problem that makes Selenium testing so dad gum hard in the real world.
The Storyteller.Redux extension can capture any logged messages to console.log or console.error in the running browser. Add that to any server side logging that you can also pipe into the Storyteller results
The general topology in these tests would look like this:
The test harness would consist of:
A Storyteller project that bootstraps the ASP.Net Core application and runs it within the Storyteller test engine. You can use the Storyteller.AspNetCore extension to make that easier (or you could after I update it for ASP.Net Core 2 and its breaking changes).
The Storyteller.Redux extension for Storyteller provides the Websockets glue to communicate between the launched browser with your Redux store and the running Storyteller engine
Storyteller Fixtures for setting up system state for tests, sending Redux actions directly to the running Redux store to simulate user interactions, asserting on the expected system state on the backend, and checking the expected Redux store state
An alternative Javascript bundle that includes all the reducer and middleware code in your application, along with some “special sauce” code shown in a section down below that enables Storyteller to send messages and retrieve the current state of the running Redux store via Websockets.
// "store" is your configured Redux store object.
// "transformState" is just a hook to convert your Redux
// store state to something that Storyteller could consume
function ReduxHarness(store, transformState){
if (!transformState){
transformState = s => s;
}
function getQueryVariable(variable)
{
var query = window.location.search.substring(1);
var vars = query.split("&");
for (var i=0;i<vars.length;i++) { var pair = vars[i].split("="); if(pair[0] == variable){return pair[1];} } return(false); } var revision = 1; var port = getQueryVariable('StorytellerPort'); var wsAddress = "ws://127.0.0.1:5250"; var socket = new WebSocket(wsAddress); socket.onclose = function(){ console.log('The socket closed'); }; socket.onerror = function(evt){ console.error(JSON.stringify(evt)); } socket.onmessage = function(evt){ if (evt.data == 'REFRESH'){ window.location.reload(); return; } if (evt.data == 'CLOSE'){ window.close(); return; } var message = JSON.parse(evt.data); console.log('Got: ' + JSON.stringify(message) + ' with topic ' + message.type); store.dispatch(message); }; store.subscribe(() => {
var state = store.getState();
revision = revision + 1;
var message = {
type: 'redux-state',
revision: revision,
state: transformState(state)
}
if (socket.readyState == 1){
var json = JSON.stringify(message);
console.log('Sending to engine: ' + json);
socket.send(json);
}
});
// Capturing any kind of client side logging
// and piping that into the Storyteller test results
var originalLog = console.log;
console.log = function(msg){
originalLog(msg);
var message = {
type: 'console.log',
text: msg
}
var json = JSON.stringify(message);
socket.send(json);
}
// Capture any logged errors in the JS code
// and pipe that into the Storyteller results
var originalError = console.error;
console.error = function(e){
originalError(e);
var message = {
type: 'console.error',
error: e
}
var json = JSON.stringify(message);
socket.send(json);
}
}
ReduxHarness(store, s => s.toJS())
The Storyteller System
In my proof of concept, I connected Storyteller to the Redux testing bundle like this (the real code is here):
public class Program
{
public static void Main(string[] args)
{
StorytellerAgent.Run(args, new ReduxSampleSystem());
}
}
public class ReduxSampleSystem : SimpleSystem
{
protected override void configureCellHandling(CellHandling handling)
{
// The code below is just to generate the static file I'm
// using to host the reducer + websockets code
var directory = AppContext.BaseDirectory;
while (Path.GetFileName(directory) != "ReduxSamples")
{
directory = directory.ParentDirectory();
}
var jsFile = directory.AppendPath("reduxharness.js");
Console.WriteLine("Copying the reduxharness.js file to " + directory);
var source = directory.AppendPath("..", "StorytellerRunner", "reduxharness.js");
File.Copy(source, jsFile, true);
var harnessPath = directory.AppendPath("harness.htm");
if (!File.Exists(harnessPath))
{
var doc = new HtmlDocument();
var href = "file://" + jsFile;
doc.Head.Add("script").Attr("src", href);
Console.WriteLine("Writing the harness file to " + harnessPath);
doc.WriteToFile(harnessPath);
}
var url = "file://" + harnessPath;
// Add the ReduxSagaExtension and point it at your view
handling.Extensions.Add(new ReduxSagaExtension(url));
}
}
The static HTML file generation above isn’t mandatory. You *could* do that by running the real page from the instance of the application hosted within Storyteller as long as the ReduxHarness function shown above is applied to your Redux store at some point.
Storyteller Fixtures that Drive or Check the Redux Store
For driving and checking the Redux store, we created a helper class called ReduxFixture that enables you to do simple actions and value checks in a declarative way as shown below:
public class CalculatorFixture : ReduxFixture
{
// There's a little bit of magic here. This would send a JSON action
// to the Redux store like {"type": "multiply", "operand": "5"}
[SendJson("multiply")]
public void Multiply(int operand)
{
}
// Does an assertion against a single value within the current state
// of the redux store using a JSONPath expression
public IGrammar CheckValue()
{
return CheckJsonValue("$.number", "The current number should be {number}");
}
}
You can of course skip the built in helpers and send JSON actions directly to the running browser or write your own assertions against the current state of the Redux store. There’s also some built in functionality in the ReduxFixture class to track Redux store revisions and to wait for any change to the Redux store before performing assertions.













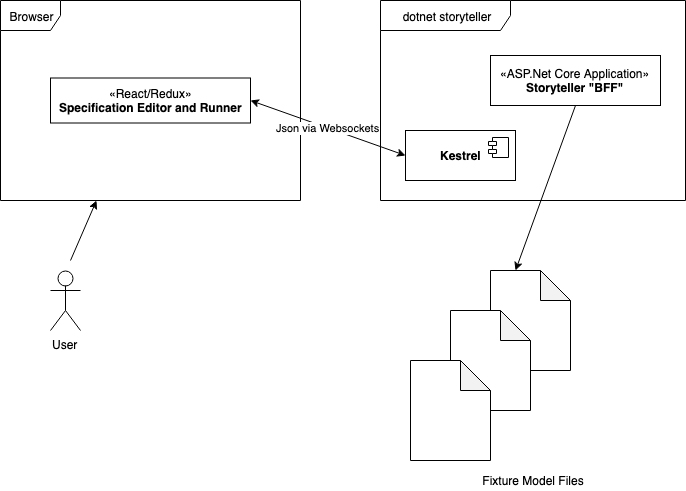


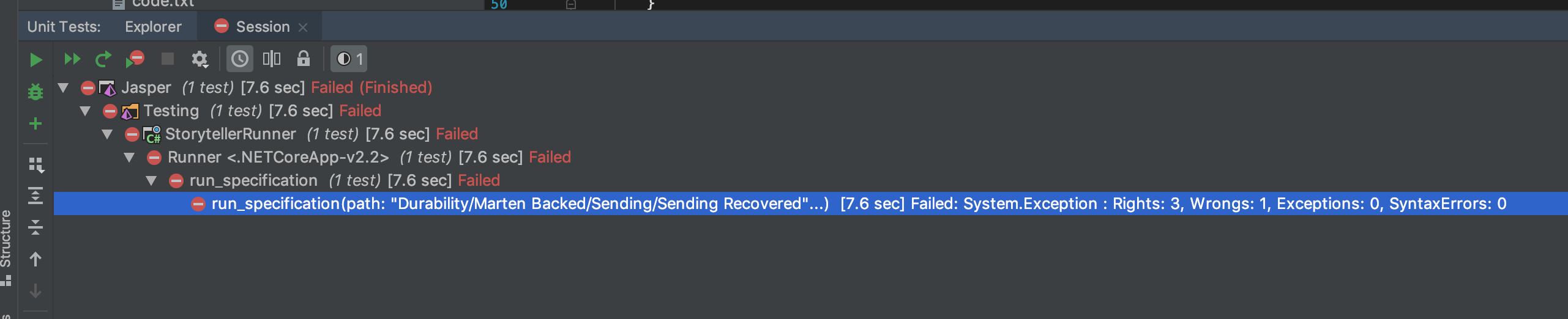




{kind=link}