This post is ostensibly about a sample usage of Wolverine middleware, but I’m going to meander a bit.
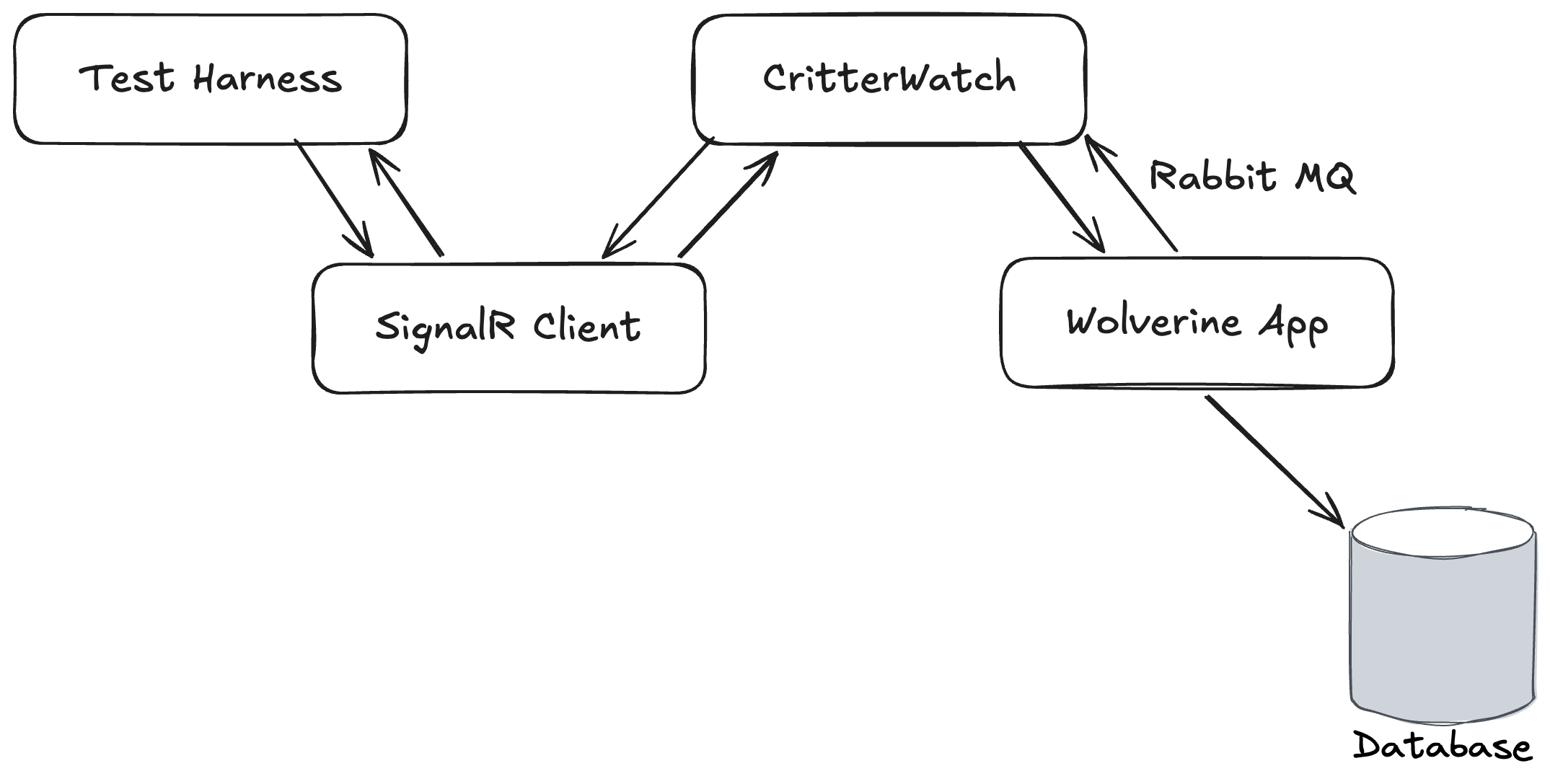
I’m working pretty hard this week trying to make some serious progress on CritterWatch, our long planned production monitoring and management console for the “Critter Stack.” At one point late in the day I was working to troubleshoot some failing tests in the CritterWatch codebase with a harness like this:
CritterWatch itself and a test Wolverine application were both running in memory as separate IHost instances. CritterWatch heavily utilizes the Wolverine SignalR messaging transport for communication between its Vue.js based user interface and the CritterWatch server. Part of Wolverine’s SignalR integration is a SignalR Client Transport option that makes it easy for us to use WebSockets communication in integration tests to mimic the client, but live completely in the world of strong typed C# objects.
The integration tests in question were trying to:
Send a message through the SignalR client to mimic commands from the user interface
Which would be relayed from CritterWatch to the right monitored Wolverine service
Which would execute a command against its database, then send a response message back to CritterWatch
Which would relay that response message right back to the original caller through SignalR
The test was failing in a very annoying way by timing out waiting for the ultimate response message to come all the way back with no real feedback about why it was failing.
More on this in a bit, but some of the handler code and automated testing code was written somewhat naively by AI agents and I have some thoughts.
As I wrote about recently in On Debugging Problems, I frequently start debugging efforts by formulating a theory about the most likely cause of the problem and trying to take a quick way to either prove or disprove that theory. This time I happened to be exactly right as I found this code:
After dithering back and forth on this, we landed on the idea of making CritterWatch a “freemium” model where all the advanced features require an installed license and I retrofitted the license protection with a little bit of help from my friend Claude — and wouldn’t you know it, in all the constant sprinting on the user interface, the test harness didn’t have a license applied so it could test through the message handler above. Easy fix to bring the tests back to green, but I wanted to improve the license guard usage by utilizing Wolverine middleware and that might be a great example for a blog post!
Then I remembered that the way that message handler is built completely sidesteps Wolverine middleware, so hold that thought.
The first problem was that we weren’t getting any obvious indication in the test harness that the test was failing because the license file wasn’t applied during tests. That’s an easy thing to fix by just changing the guard clause to this:
if (!LicenseGuard.IsOperationAllowed())
{
thrownewLicenseRequiredException();
}
And a bit of corresponding error handling configuration for Wolverine to know to discard these messages rather than let them go to the dead letter queue or waste any time retrying:
By throwing an exception — and I’m not too worried about using an exception here for flow control because after all, you’re doing something naughty if you manage to hit that message handler — I knew that would be automatically written out to any test failures with the Wolverine tracked session testing helpers that these tests were using even though the exceptions are happening in asynchronous message handling and would be handled internally by Wolverine.
The key point here is that it is very often important in your test automation strategy to think about how you can report contextual information about test failures that will help developers troubleshoot said failures.
Alright, so let’s pretend that I’m working with normal Wolverine message handlers and middleware strategies are available. In that case I can get the license guard out of the message handler code as a cross cutting concern. A way to do that is to design a new [RequiresLicense] attribute that will add middleware for the license guard to any handler class or method decorated with that attribute. Here’s the Wolverine flavor of that strategy:
With that attribute marking up either the handler class or the main message handler method, Wolverine is going to do some “code weaving” so that this line of code will appear on the first line of in the generated code that Wolverine builds around your handler code:
Just to make sure this is clear, Wolverine does not use any kind of Reflection at runtime but instead “bakes” the middleware application in on the first usage of the handler or even completely ahead of time in production usage.
Wolverine’s Configuration vs Runtime Model
It’s admittedly a goofy model that is quite different than basically every other “Russian Doll” tool out there where there’s usually some kind of wrapping model like MediatR’s IPipelineBehavior<TRequest, TResponse>. Wolverine’s model was intentionally designed to avoid the bloated object allocations that tools like MediatR accidentally cause when folks get a little slap happy with middleware usage. Wolverine’s model is also designed to minimize the dreadful exception stack traces that many application frameworks that support middleware create for you by doing so much object wrapping and delegation *cough* ASP.Net Core *cough*.
I had an extremely popular professor in college for all our heat transfer classes who had a legendary drinking game that had been passed down for generations (if Dr. Chapman gets chalk on his pants, take a drink). If there was a drinking game for me, it would be “if Jeremy quotes the original C2 Wiki or links to a Martin Fowler post…”
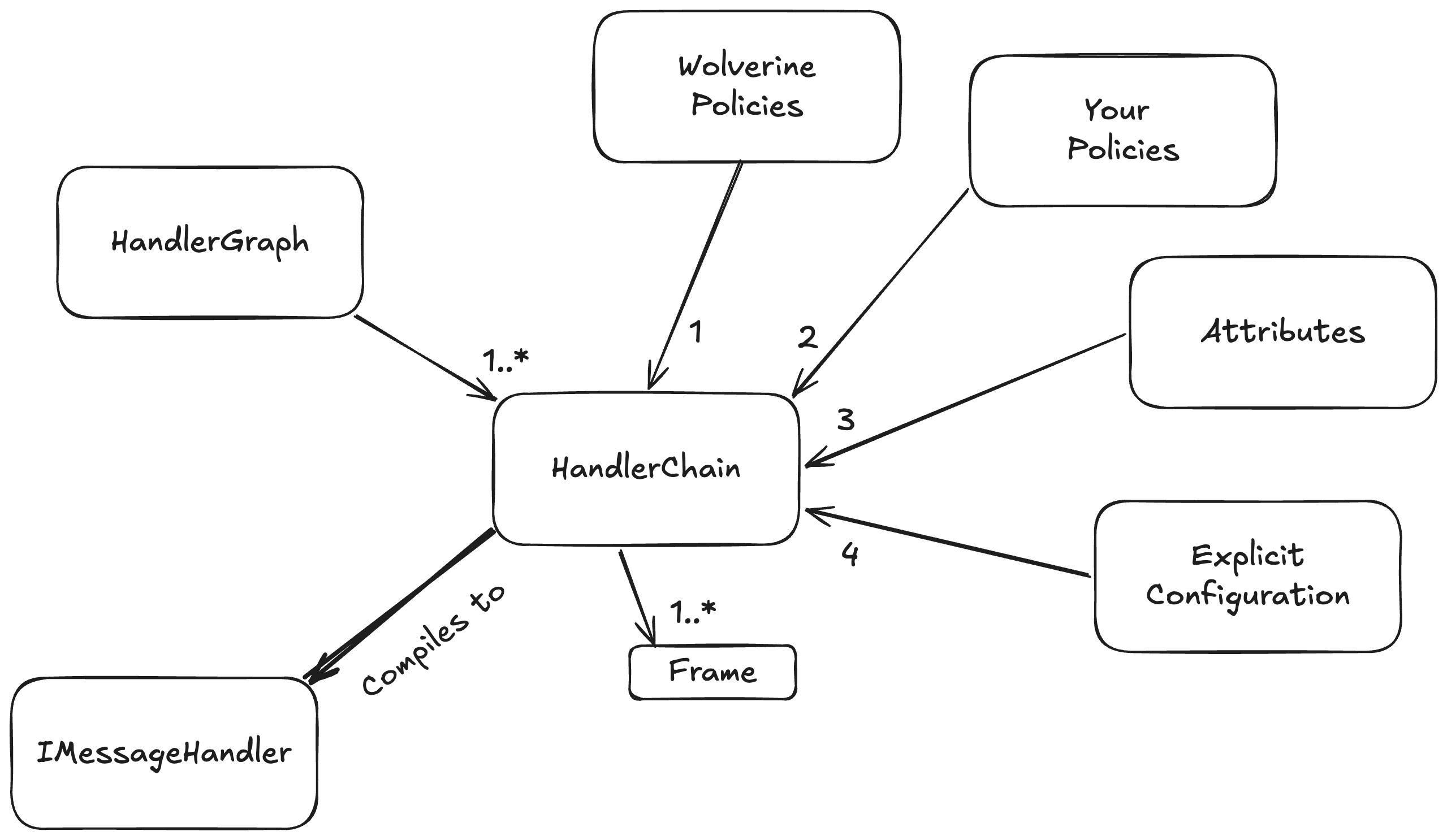
Wolverine’s middleware strategy also varies quite a bit from a MediatR or most other is our usage of an internal “Semantic Model” that is built up at configuration and bootstrapping time, then compiled into a runtime model:
At bootstrapping time, we build up a configuration model for how every discovered message handler or HTTP endpoint method will be handled. That same model also models the application of middleware, post processors, error handling for message handlers, and a ton of HTTP specific elements for each message handler or HTTP endpoint. In order, the configuration is built up by:
Built in Wolverine policies like “an HTTP endpoint method that returns a string will write out content type text/plain go first
User defined policies go next, and can override anything from the Wolverine policies
Attributes on the message handler or HTTP endpoint type and method apply individual overrides on specific message handlers or HTTP endpoint handling. We do this through the base ModifyChainAttribute or ModifyHttpChainAttribute classes that expose a method that directly modifies the HandlerChain configuration model for each message handler or likewise the HttpChain model for an HTTP endpoint. Attributes of course win out over policies
Lastly, Wolverine has a way to expose direct manipulation of the underlying HandlerChain model for individual handlers, and the more explicit mechanisms always win out over any kind of policies
This HandlerChain model is also built up with knowledge of your application’s IoC container and through that, the dependencies of any given message handler or HTTP endpoint method. Wolverine can use this to selectively apply middleware. For example:
Wolverine’s Fluent Validation middleware doesn’t apply if there are no matching validators for a message type and can effectively inline a single or collection of validators otherwise. No runtime probing of the IoC containers like you see in many validation middleware approaches out there
In a system using multiple EF Core DbContext types, Wolverine can choose the right one for a given Saga type and generate the most efficient code possible to use that DbContext without having to use any kind of wrappers or runtime IoC tricks
In a system that uses both EF Core and Marten, Wolverine can tell from the dependencies of a single handler if it should use Marten based or EF Core based transactional middleware
The key point here is that the “Semantic Model” usage and the way we do configuration in Wolverine allows you a great deal of control over the application of middleware in a fine grained way and this is frequently valuable.
NServiceBus also has their BehaviorGraph concept that is the same “Semantic Model” concept I’m discussing here that allows either Wolverine or NServiceBus users to fine tune the application of middleware to specific messaging handlers based on user or framework defined conventions. The similarity is not the slightest bit coincidental because NServiceBus’s model was taken from FubuMVC that was the spiritual predecessor of Wolverine.
About the AI Thing
Ages ago I read a quote from Martin Fowler (take a drink) something to the effect of:
The only way to know how far a new tool or technique can go is to take it too far, then back off a bit
I’m in my “back off” phase for AI assisted development after feeling completely blown away at first by how much I was able to accomplish. Up above, I explained that I ran into some trouble because of code written naively by AI that I had not reviewed well enough. I’ve also been the victim or perpetrator of several AI coding related problems in the past couple months alone that have let regression bugs slip out into the wild.
I don’t think that anybody is going all the way back to coding completely by hand, but for my part, I think that AI tempts you into trying to develop faster than you should and that you need to exert more control over the code than I apparently had before this week. I guess my only main takeaway is to slow down, not make too many risky changes just because an AI tool made it easy, and if you are responsible for code used by other people, make sure you have eyeballs on it.
I miss long form blogging
If you’ll allow me a little diversion, I used to enjoy technical blogging when that was the way that developers communicated online. Before social media took off, I would take time to formulate and craft a blog post to explain some idea I had or to share something I’d learned that I self importantly thought other developers should know too. At one point I had an hour and change commute on a train every morning, and used to occasionally write a series of mini essays I called a “Train of Thought” for topics that were on my mind but not worthy of a long form blog post by themselves. As I thought tonight about writing up a little blog post sample of Wolverine middleware, it occurred to me that that was going to touch on several other topics and that reminded me of that magic little time when I enjoyed writing technical blog posts.
Then came Twitter of course, and that acted as a release valve that let you blurt things out without ever building up a cohesive, long form post and everything changed forever. Now, of course, what was Twitter isn’t nearly as important, there’s basically no technical content on BluSky, Mastodon has “Linux on the Desktop” energy, and LinkedIn posts are nothing but non stop self-promotion. Younger developers are on Twitch or cranking out YouTube videos. I still blog, but I’m admittedly almost completely focused on promoting the “Critter Stack” tools or JasperFx Software and it’s not the same at all. For what it’s worth, I enjoyed just sitting down tonight and trying to write something by hand.
If you’re planning on coming to my workshop, you’ll want .NET 8, Git, and some kind of Docker Desktop on your box to run the sample code I’ll use in the workshop. If Docker doesn’t work for you, you maybe want a local install of PostgreSQL and Rabbit MQ.
Hey folks, I’ll be giving the first ever workshop on building an Event Driven Architecture with the full “Critter Stack” at DevUp 2024 in St. Louis next week on Wednesday the 14th bright and early at 8:30 AM.
We’ll be working through a sample backend web service that also communicates with other headless services using Event Sourcing within a general CQRS architectural approach with the whole “Critter Stack. We’ll use Marten (over PostgreSQL) for our persistence strategy using both its event sourcing support and as a document database. We’ll combine that with Wolverine as a server side framework for background processing, asynchronous messaging, and even as an alternative HTTP endpoint framework. Lastly, just for fun, there’ll be guest appearances from other JasperFx tools like Alba and Oakton for automated integration testing and command line execution respectively.
So why would you want to come to this and what might you get out of it? I’m hoping the takeaways — even if you don’t intend to use Marten or Wolverine — will be:
A good introduction to event sourcing as a technical approach and some of the real challenges you’ll face when building a system using event sourcing as a persistence strategy
An understanding of what goes into building a robust CQRS system including dealing with transient errors, observability, concurrency, and how to best segment message processing to achieve self-healing systems
Challenging the industry conventional wisdom about the efficacy of Hexagonal/Clean/Onion Architecture approaches really are when I show what a very low ceremony “vertical slice architecture” approach can be like with the Wolverine + Marten combination while still being robust, observable, highly testable, and still keeping infrastructure concerns out of the business logic
Some exposure to Open Telemetry and general observability tooling for distributed systems you absolutely want if you don’t already have that
Techniques for automating integration tests against an Event Driven Architecture
Because I’m absolutely in the business of promoting the “Critter Stack” tools, I’ll try to convince you that:
Marten is already the most robust and feature rich solution for event sourcing in the .NET ecosystem while also being arguably the easiest to get up and going with
How the Wolverine + Marten combination makes CQRS with Event Sourcing a much easier architectural pattern to use
Wolverine’s emphasis on low ceremony code approaches can help systems be more successfully maintained over time by simply having much less noise code and layering in your systems while still being robust
The “Critter Stack” has an excellent story for automated integration testing support that can do a lot to make your development efforts more successful
Both Marten & Wolverine can help your teams achieve a low “time to first pull request” by doing a lot to configure necessary infrastructure like databases or message brokers on the fly for a better development experience
I’m excited, because this is my first opportunity to do a workshop on the “Critter Stack” tools, and I think we’ve got a very compelling technical story to tell about the tools! And if nothing else, I’m looking forward to any feedback that might help us improve the tools down the line.
And for any *ahem* older folks from St. Louis in my talk, I personally at the time that Jorge Orta was out at first and the Cards should have won that game.
Hey, did you know that JasperFx Software offers formal support plans for Marten and Wolverine? Not only are we making the “Critter Stack” tools be viable long term options for your shop, we’re also interested in hearing your opinions about the tools and how they should change.We’re also certainly open to help you succeed with your software development projects on a consulting basis whether you’re using any part of the Critter Stack or some completely different .NET server side tooling.
First off, let’s say that you have a simplistic document that can “self-aggregate” itself as a “Snapshot” in Marten like this:
public record InvoiceCreated(string Description, decimal Amount);
public record InvoiceApproved;
public record InvoiceCancelled;
public record InvoicePaid;
public record InvoiceRejected;
public class Invoice
{
public Invoice()
{
}
public static Invoice Create(IEvent<InvoiceCreated> created)
{
return new Invoice
{
Amount = created.Data.Amount,
Description = created.Data.Description,
// Capture the timestamp from the event
// metadata captured by Marten
Created = created.Timestamp,
Status = InvoiceStatus.Created
};
}
public int Version { get; set; }
public decimal Amount { get; set; }
public string Description { get; set; }
public Guid Id { get; set; }
public DateTimeOffset Created { get; set; }
public InvoiceStatus Status { get; set; }
public void Apply(InvoiceCancelled _) => Status = InvoiceStatus.Cancelled;
public void Apply(InvoiceRejected _) => Status = InvoiceStatus.Rejected;
public void Apply(InvoicePaid _) => Status = InvoiceStatus.Paid;
public void Apply(InvoiceApproved _) => Status = InvoiceStatus.Approved;
}
For asynchronous projections of any kind, we have a little bit of complication for testing. In a classic “Arrange, Act, Assert” test workflow, we’d like to exercise our projection — and mind you, I strongly recommend that testing happen within its integration with Marten rather than some kind of solitary unit tests with fakes — with a workflow like this:
Pump in some new events to Marten
Somehow magically wait for Marten’s asynchronous daemon running in a background thread progress to the point where it’s handled all of our newly appended events for all known, running projections
Load the expected documents that should have been persisted or updated from our new events by the projections running in the daemon, and run some assertions on the expected system state
For right now, I want to worry about the second bullet point and introduce a new (old, but it actually works correctly now) WaitForNonStaleProjectionDataAsync API introduced in Marten 7.5. You can see the new API used in this test from the new documentation on Testing Projections:
[Fact]
public async Task test_async_aggregation_with_wait_for()
{
// In your tests, you would most likely use the IHost for your
// application as it is normally built
using var host = await Host.CreateDefaultBuilder()
.ConfigureServices(services =>
{
services.AddMarten(opts =>
{
opts.Connection(
"Host=localhost;Port=5432;Database=marten_testing;Username=postgres;password=postgres;Command Timeout=5");
opts.DatabaseSchemaName = "incidents";
// Notice that the "snapshot" is running inline
opts.Projections.Snapshot<Invoice>(SnapshotLifecycle.Async);
})
// Using Solo in tests will help it start up a little quicker
.AddAsyncDaemon(DaemonMode.Solo);
}).StartAsync();
var store = host.Services.GetRequiredService<IDocumentStore>();
var invoiceId = Guid.NewGuid();
// Pump in events
using (var session = store.LightweightSession())
{
session.Events.StartStream<Invoice>(invoiceId, new InvoiceCreated("Blue Shoes", 112.24m));
await session.SaveChangesAsync();
session.Events.Append(invoiceId,new InvoiceApproved());
session.Events.Append(invoiceId,new InvoicePaid());
await session.SaveChangesAsync();
}
// Now, this is going to pause here in this thread until the async daemon
// running in our IHost is completely caught up to at least the point of the
// last event captured at the point this method was called
await store.WaitForNonStaleProjectionDataAsync(5.Seconds());
// NOW, we should expect reliable results by just loading the already
// persisted documents built by rebuilding the projection
await using var query = store.QuerySession();
// Load the document that was "projected" from the events above
// and immediately persisted to the document store
var invoice = await query.LoadAsync<Invoice>(invoiceId);
// Run assertions
invoice.Description.ShouldBe("Blue Shoes");
invoice.Status.ShouldBe(InvoiceStatus.Paid);
}
In the example projection, I’ve been capturing the timestamp in the Invoice document from the Marten event metadata:
public static Invoice Create(IEvent<InvoiceCreated> created)
{
return new Invoice
{
Amount = created.Data.Amount,
Description = created.Data.Description,
// Capture the timestamp from the event
// metadata captured by Marten
Created = created.Timestamp,
Status = InvoiceStatus.Created
};
}
But of course, if that timestamp has some meaning later on and you have any kind of business rules that may need to key off that time, it’s very helpful to be able to control the timestamps that Marten is assigning to create predictable automated tests. As of Marten 7.5, Marten uses the newer .NET TimeProvider behind the scenes, and you can replace it in testing like so:
[Fact]
public async Task test_async_aggregation_with_wait_for_and_fake_time_provider()
{
// Hang on to this for later!!!
var eventsTimeProvider = new FakeTimeProvider();
// In your tests, you would most likely use the IHost for your
// application as it is normally built
using var host = await Host.CreateDefaultBuilder()
.ConfigureServices(services =>
{
services.AddMarten(opts =>
{
opts.Connection(
"Host=localhost;Port=5432;Database=marten_testing;Username=postgres;password=postgres;Command Timeout=5");
opts.DatabaseSchemaName = "incidents";
// Notice that the "snapshot" is running inline
opts.Projections.Snapshot<Invoice>(SnapshotLifecycle.Async);
opts.Events.TimeProvider = eventsTimeProvider;
})
// Using Solo in tests will help it start up a little quicker
.AddAsyncDaemon(DaemonMode.Solo);
}).StartAsync();
var store = host.Services.GetRequiredService<IDocumentStore>();
var invoiceId = Guid.NewGuid();
// Pump in events
using (var session = store.LightweightSession())
{
session.Events.StartStream<Invoice>(invoiceId, new InvoiceCreated("Blue Shoes", 112.24m));
await session.SaveChangesAsync();
session.Events.Append(invoiceId,new InvoiceApproved());
session.Events.Append(invoiceId,new InvoicePaid());
await session.SaveChangesAsync();
}
// Now, this is going to pause here in this thread until the async daemon
// running in our IHost is completely caught up to at least the point of the
// last event captured at the point this method was called
await store.WaitForNonStaleProjectionDataAsync(5.Seconds());
// NOW, we should expect reliable results by just loading the already
// persisted documents built by rebuilding the projection
await using var query = store.QuerySession();
// Load the document that was "projected" from the events above
// and immediately persisted to the document store
var invoice = await query.LoadAsync<Invoice>(invoiceId);
// Run assertions, and we'll use the faked timestamp
// from our time provider
invoice.Created.ShouldBe(eventsTimeProvider.Start);
}
In the sample above, I used the FakeTimeProvider from the Microsoft.Extensions.TimeProvider.Testing Nuget package.
Summary
We take testability and automated testing very seriously throughout the entire “Critter Stack.” The testing of asynchronous projections has long been a soft spot that we hope is improved by the new capabilities in this post. As always, feel free to pop into the Critter Stack Discord for any questions.
Hey, did you know that JasperFx Software offers formal support plans for Marten and Wolverine? Not only are we making the “Critter Stack” tools be viable long term options for your shop, we’re also interested in hearing your opinions about the tools and how they should change.We’re also certainly open to help you succeed with your software development projects on a consulting basis whether you’re using any part of the Critter Stack or some completely different .NET server side tooling.
Hey, when you’re building grown up software systems in a responsible way, who likes effective automated testing? Me, too! Moreover, I like automated tests that are reliable — and anyone who has ever been remotely near a large automated test suite testing through the web application layer with any kind of asynchronous behavior knows exactly how painful “flake-y” tests are that suffer from timing issues.
Wolverine of course is an application framework for performing background processing and asynchronous messaging — meaning that there’s no end of the exact kind of asynchronous behavior that is notoriously hard to deal with in automated tests. At a minimum, what you need is a way to exercise the message handling within Wolverine (the “act” in the “act, arrange, assert” test pattern), but wait until all cascading activity is really complete before allowing the automated test to continue making assertions on expected outcomes. Fortunately, Wolverine has that very functionality baked into its core library. Here’s a fake saga that we recently used to fix a bug in Wolverine:
public class LongProcessSaga : Saga
{
public Guid Id { get; init; }
[Middleware(typeof(BeginProcessMiddleware))]
public static (LongProcessSaga, OutgoingMessages) Start(BeginProcess message, RecordData? sourceData = null)
{
var outgoingMessages = new OutgoingMessages();
var saga = new LongProcessSaga
{
Id = message.DataId,
};
if (sourceData is not null)
{
outgoingMessages.Add(new ContinueProcess(saga.Id, message.DataId, sourceData.Data));
}
return (
saga,
outgoingMessages
);
}
public void Handle(ContinueProcess process)
{
Continued = true;
}
public bool Continued { get; set; }
}
When the BeginProcess message is handled by Wolverine, it might also spawn a ContinueProcess message. So let’s write a test that exercises the first message, but waits until the second message that we expect to be spawned while handling the first message before allowing the test to proceed:
[Fact]
public async Task can_compile_without_issue()
{
// Arrange -- and sorry, it's a bit of "Arrange" to get an IHost
var builder = WebApplication.CreateBuilder(Array.Empty<string>());
builder.Services
.AddMarten(options =>
{
options.Connection(Servers.PostgresConnectionString);
})
.UseLightweightSessions()
.IntegrateWithWolverine();
builder.Host.UseWolverine(options =>
{
options.Discovery.IncludeAssembly(GetType().Assembly);
options.Policies.AutoApplyTransactions();
options.Policies.UseDurableLocalQueues();
options.Policies.UseDurableOutboxOnAllSendingEndpoints();
});
builder.Services.AddScoped<IDataService, DataService>();
// This is using Alba, which uses WebApplicationFactory under the covers
await using var host = await AlbaHost.For(builder, app =>
{
app.MapWolverineEndpoints();
});
// Finally, the "Act"!
var originalMessage = new BeginProcess(Guid.NewGuid());
// This is a built in extension method to Wolverine to "wait" until
// all activity triggered by this operation is completed
var tracked = await host.InvokeMessageAndWaitAsync(originalMessage);
// And now it's okay to do assertions....
// This would have failed if there was 0 or many ContinueProcess messages
var continueMessage = tracked.Executed.SingleMessage<ContinueProcess>();
continueMessage.DataId.ShouldBe(originalMessage.DataId);
}
The IHost.InvokeMessageAndWaitAsync() is part of Wolverine’s “tracked session” feature that’s descended from an earlier system some former colleagues and I developed and used at my then employer about a decade ago. The original mechanism was quite successful for our integration testing efforts of the time, and was built into Wolverine quite early. This “tracked session” feature is very heavily used within the Wolverine test suites to test Wolverine itself.
But wait, there’s more! Here’s a bigger sample from the documentation just showing you some more things that are possible:
public async Task using_tracked_sessions_advanced(IHost otherWolverineSystem)
{
// The point here is just that you somehow have
// an IHost for your application
using var host = await Host.CreateDefaultBuilder()
.UseWolverine().StartAsync();
var debitAccount = new DebitAccount(111, 300);
var session = await host
// Start defining a tracked session
.TrackActivity()
// Override the timeout period for longer tests
.Timeout(1.Minutes())
// Be careful with this one! This makes Wolverine wait on some indication
// that messages sent externally are completed
.IncludeExternalTransports()
// Make the tracked session span across an IHost for another process
// May not be super useful to the average user, but it's been crucial
// to test Wolverine itself
.AlsoTrack(otherWolverineSystem)
// This is actually helpful if you are testing for error handling
// functionality in your system
.DoNotAssertOnExceptionsDetected()
// Again, this is testing against processes, with another IHost
.WaitForMessageToBeReceivedAt<LowBalanceDetected>(otherWolverineSystem)
// There are many other options as well
.InvokeMessageAndWaitAsync(debitAccount);
var overdrawn = session.Sent.SingleMessage<AccountOverdrawn>();
overdrawn.AccountId.ShouldBe(debitAccount.AccountId);
}
As hopefully implied by the earlier example, the “tracked session” functionality also gives you:
Recursive tracking of all message activity to wait for everything to finish
Enforces timeouts in case of hanging tests that probably won’t finish successfully
The ability to probe the exact messaging activity that happened as a result of your original message
Visibility into any exceptions recorded by Wolverine during message processing that might otherwise be hidden from you. This functionality will re-throw these exceptions to fail a test unless explicitly told to ignore processing exceptions — which you may very well want to do to test error handling logic
If a test fails because of a timeout, or doesn’t reach the expected conditions, the test failure exception will show you a (hopefully) neatly formatted textual table explaining what it did observe in terms of what messages were sent, received, started, and finished executing. Again, this is to give you more visibility into test failures, because those inevitably do happen!
Last Thoughts
Supporting a complicated OSS tool like Marten or Wolverine is a little bit like being trapped in somewhere in Jurassic Park while the raptors (users, and especially creative users) are prowling around the perimeter of your tool just looking for weak spots in your tools — a genuine bug, a use case you didn’t anticipate, an awkward API, some missing documentation, or even just some wording in your documentation that isn’t clear enough. The point is, it’s exhausting and sometimes demoralizing when raptors are getting past your defenses a little too often just because you rolled out a near complete rewrite of your LINQ provider subsystem:)
Yesterday I was fielding questions from a fellow whose team was looking to move to Wolverine from one of the older .NET messaging frameworks, and he was very complimentary of the integration testing support that’s the subject of this post. My only point here is to remember to celebrate your successes to balance out the constant worry about what’s not yet great about your tool or project or codebase.
And by success, I mean a very important feature that will absolutely help teams build reliable software more productively with Wolverine that does not exist in other .NET messaging frameworks. And certainly doesn’t exist in the yet-to-be-built Microsoft eventing framework where they haven’t even considered the idea of testability.
Hey, did you know that JasperFx Software is ready for formal support plans for Marten and Wolverine? Not only are we trying to make the “Critter Stack” tools be viable long term options for your shop, we’re also interested in hearing your opinions about the tools and how they should change.We’re also certainly open to help you succeed with your software development projects on a consulting basis whether you’re using any part of the Critter Stack or any other .NET server side tooling.
Let’s build a small web service application using the whole “Critter Stack” and their friends, one small step at a time. For right now, the “finished” code is at CritterStackHelpDesk on GitHub.
Let’s start this post by making a bold statement that I’ll probably regret, but still spend the rest of this post trying to back up:
Remembering the basic flow of our incident tracking, help desk service in this series, we’ve got this workflow:
Starting in the middle with the “Categorize Incident”, our system’s workflow is something like:
A technician will send a request to change the category of the incident
If the system determines that the request will be changing the category, the system will append a new event to mark that state, and also publish a new command message to try to assign a priority to the incident automatically based on the customer data
When the system handles that new “Try Assign Priority” command, it will look at the customer’s settings, and likewise append another event to record the change of priority for the incident. If the incident changes, it will also publish a message to an external “Notification Service” — but for this post, let’s just worry about whether we’re correctly publishing the right message
In an earlier post, I showed this version of a message handler for the CategoriseIncident command:
public static class CategoriseIncidentHandler
{
public static readonly Guid SystemId = Guid.NewGuid();
[AggregateHandler]
// The object? as return value will be interpreted
// by Wolverine as appending one or zero events
public static async Task<object?> Handle(
CategoriseIncident command,
IncidentDetails existing,
IMessageBus bus)
{
if (existing.Category != command.Category)
{
// Send the message to any and all subscribers to this message
await bus.PublishAsync(
new TryAssignPriority { IncidentId = existing.Id });
return new IncidentCategorised
{
Category = command.Category,
UserId = SystemId
};
}
// Wolverine will interpret this as "do no work"
return null;
}
}
Notice that this handler is injecting the Wolverine IMessageBus service into the handler method. We could test this code as is with a “fake” for IMessageBus just to verify whether the expected outgoing message for TryAssignPriority goes out or not. Helpfully, Wolverine even supplies a “spy” version of IMessageBus called TestMessageContext that can be used in unit tests as a stand in just to record what the outgoing messages were.
My strong preference though is to use Wolverine’s concept of cascading messages to write a pure function such that the behavioral logic can be tested without any mocks, stubs, or other fakes. In the sample code above, we had been using Wolverine as “just” a “Mediator” within an MVC Core controller. This time around, let’s ditch the unnecessary “Mediator” ceremony and use a Wolverine HTTP endpoint for the same functionality. In this case we can write the same functionality as a pure function like so:
public static class CategoriseIncidentEndpoint
{
[WolverinePost("/api/incidents/categorise"), AggregateHandler]
public static (Events, OutgoingMessages) Post(
CategoriseIncident command,
IncidentDetails existing,
User user)
{
var events = new Events();
var messages = new OutgoingMessages();
if (existing.Category != command.Category)
{
// Append a new event to the incident
// stream
events += new IncidentCategorised
{
Category = command.Category,
UserId = user.Id
};
// Send a command message to try to assign the priority
messages.Add(new TryAssignPriority
{
IncidentId = existing.Id
});
}
return (events, messages);
}
}
In the endpoint above, we’re “pushing” all of the required inputs for our business logic in the Post() method that makes a decision about what state changes should be captured and what additional actions should be done through outgoing, cascaded messages.
A couple notes about this code:
It’s using the aggregate handler workflow we introduced in an earlier post to “push” the IncidentDetails aggregate for the incident stream into the method. We’ll need this information to “decide” what to do next
The Events type is a Wolverine construct that tells Wolverine “hey, the objects in this collection are meant to be appended as events to the event stream for this aggregate.”
Likewise, the OutgoingMessages type is a Wolverine construct that — wait for it — tells Wolverine that the objects contained in that collection should be published as cascading messages after the database transaction succeeds
The Marten + Wolverine transactional middleware is calling Marten’s IDocumentSession.SaveChangesAsync() to commit the logical transaction, and also dealing with the transaction outbox mechanics for the cascading messages from the OutgoingMessages collection.
Alright, with all that said, let’s look at what a unit test for a CategoriseIncident command message that results in the category being changed:
[Fact]
public void raise_categorized_event_if_changed()
{
var command = new CategoriseIncident
{
Category = IncidentCategory.Database
};
var details = new IncidentDetails(
Guid.NewGuid(),
Guid.NewGuid(),
IncidentStatus.Closed,
Array.Empty<IncidentNote>(),
IncidentCategory.Hardware);
var user = new User(Guid.NewGuid());
var (events, messages) = CategoriseIncidentEndpoint.Post(command, details, user);
// There should be one appended event
var categorised = events.Single()
.ShouldBeOfType<IncidentCategorised>();
categorised
.Category.ShouldBe(IncidentCategory.Database);
categorised.UserId.ShouldBe(user.Id);
// And there should be a single outgoing message
var message = messages.Single()
.ShouldBeOfType<TryAssignPriority>();
message.IncidentId.ShouldBe(details.Id);
message.UserId.ShouldBe(user.Id);
}
In real life, I’d probably opt to break that unit test into a BDD-like context and individual tests to assert the expected event(s) being appended and the expected outgoing messages, but this is conceptually easier and I didn’t sleep well last night, so this is what you get!
Let’s move on to the message handler for the TryAssignPriority message, and also make this a pure function so we can easily test the behavior:
public static class TryAssignPriorityHandler
{
// Wolverine will call this method before the "real" Handler method,
// and it can "magically" connect that the Customer object should be delivered
// to the Handle() method at runtime
public static Task<Customer?> LoadAsync(IncidentDetails details, IDocumentSession session)
{
return session.LoadAsync<Customer>(details.CustomerId);
}
// There's some database lookup at runtime, but I've isolated that above, so the
// behavioral logic that "decides" what to do is a pure function below.
[AggregateHandler]
public static (Events, OutgoingMessages) Handle(
TryAssignPriority command,
IncidentDetails details,
Customer customer)
{
var events = new Events();
var messages = new OutgoingMessages();
if (details.Category.HasValue && customer.Priorities.TryGetValue(details.Category.Value, out var priority))
{
if (details.Priority != priority)
{
events.Add(new IncidentPrioritised(priority, command.UserId));
if (priority == IncidentPriority.Critical)
{
messages.Add(new RingAllTheAlarms(command.IncidentId));
}
}
}
return (events, messages);
}
}
I’d ask you to notice the LoadAsync() method above. It’s part of the logical handler workflow, but Wolverine is letting us keep that separate from the main “decider” message Handle() method. We’d have to test the entire handler with an integration test eventually, but we can happily write fast running, fine grained unit tests on the expected behavior by just “pushing” inputs into the Handle() method and measuring the events and outgoing messages just by checking the return values.
Summary and What’s Next
Wolverine’s approach has always been driven by the desire to make your application code as testable as possible. Originally that meant to just keep the framework (Wolverine itself) out of your application code as much as possible. Later on, the Wolverine community was influenced by more Functional Programming techniques and Jim Shore’s paper on Testing without Mocks.
Specifically, Wolverine embraced the idea of the “A-Frame Architecture”, with Wolverine itself in the role of the mediator/controller/conductor coordinates between infrastructural concerns like Marten and your own business logic code in message handlers or HTTP endpoint methods without creating a direct coupling between you behavioral logic code and your infrastructure:
If you take advantage of Wolverine features like cascading messages, side effects, and compound handlers to decompose your system in a more FP-esque way while letting Wolverine handle the coordination, you can arrive at much more testable code.
I said earlier that I’d get to Rabbit MQ messaging soon, and I’ll get around to that soon. To fit in with one of my CodeMash 2024 talks on this Friday, I might take a little side trip into how the “Critter Stack” plays well inside of a low ceremony vertical slice architecture as I get ready to absolutely blast away at the “Clean/Onion Architecture” this week.
Hey, did you know that JasperFx Software is ready for formal support plans for Marten and Wolverine? Not only are we trying to make the “Critter Stack” tools be viable long term options for your shop, we’re also interested in hearing your opinions about the tools and how they should change.We’re also certainly open to help you succeed with your software development projects on a consulting basis whether you’re using any part of the Critter Stack or any other .NET server side tooling.
Let’s build a small web service application using the whole “Critter Stack” and their friends, one small step at a time. For right now, the “finished” code is at CritterStackHelpDesk on GitHub.
Heretofore in this series, I’ve been using ASP.Net MVC Core controllers anytime we’ve had to build HTTP endpoints for our incident tracking, help desk system in order to introduce new concepts a little more slowly.
If you would, let’s refer back to an earlier incarnation of an HTTP endpoint to handle our LogIncident command from an earlier post in this series:
public class IncidentController : ControllerBase
{
private readonly IDocumentSession _session;
public IncidentController(IDocumentSession session)
{
_session = session;
}
[HttpPost("/api/incidents")]
public async Task<IResult> Log(
[FromBody] LogIncident command
)
{
var userId = currentUserId();
var logged = new IncidentLogged(command.CustomerId, command.Contact, command.Description, userId);
var incidentId = _session.Events.StartStream(logged).Id;
await _session.SaveChangesAsync(HttpContext.RequestAborted);
return Results.Created("/incidents/" + incidentId, incidentId);
}
private Guid currentUserId()
{
// let's say that we do something here that "finds" the
// user id as a Guid from the ClaimsPrincipal
var userIdClaim = User.FindFirst("user-id");
if (userIdClaim != null && Guid.TryParse(userIdClaim.Value, out var id))
{
return id;
}
throw new UnauthorizedAccessException("No user");
}
}
Just to be clear as possible here, the Wolverine HTTP endpoints feature introduced in this post can be mixed and matched with MVC Core and/or Minimal API or even FastEndpoints within the same application and routing tree. I think the ASP.Net team deserves some serious credit for making that last sentence a fact.
Today though, let’s use Wolverine HTTP endpoints and rewrite that controller method above the “Wolverine way.” To get started, add a Nuget reference to the help desk service like so:
dotnet add package WolverineFx.Http
Next, let’s break into our Program file and add Wolverine endpoints to our routing tree near the bottom of the file like so:
app.MapWolverineEndpoints(opts =>
{
// We'll add a little more in a bit...
});
// Just to show where the above code is within the context
// of the Program file...
return await app.RunOaktonCommands(args);
Now, let’s make our first cut at a Wolverine HTTP endpoint for the LogIncident command, but I’m purposely going to do it without introducing a lot of new concepts, so please bear with me a bit:
public record NewIncidentResponse(Guid IncidentId)
: CreationResponse("/api/incidents/" + IncidentId);
public static class LogIncidentEndpoint
{
[WolverinePost("/api/incidents")]
public static NewIncidentResponse Post(
// No [FromBody] stuff necessary
LogIncident command,
// Service injection is automatic,
// just like message handlers
IDocumentSession session,
// You can take in an argument for HttpContext
// or immediate members of HttpContext
// as method arguments
ClaimsPrincipal principal)
{
// Some ugly code to find the user id
// within a claim for the currently authenticated
// user
Guid userId = Guid.Empty;
var userIdClaim = principal.FindFirst("user-id");
if (userIdClaim != null && Guid.TryParse(userIdClaim.Value, out var claimValue))
{
userId = claimValue;
}
var logged = new IncidentLogged(command.CustomerId, command.Contact, command.Description, userId);
var id = session.Events.StartStream<Incident>(logged).Id;
return new NewIncidentResponse(id);
}
}
Here’s a few salient facts about the code above to explain what it’s doing:
Just like Wolverine message handlers, the endpoint methods are flexible and Wolverine generates code around your code to mediate between the raw HttpContext for the request and your code
We have already enabled Marten transactional middleware for our message handlers in an earlier post, and that happily applies to Wolverine HTTP endpoints as well. That helps make our endpoint method be just a synchronous method with the transactional middleware dealing with the ugly asynchronous stuff for us.
You can “inject” HttpContext and its immediate children into the method signatures as I did with the ClaimsPrincipal up above
Method injection is automatic without any silly [FromServices] attributes, and that’s what’s happening with the IDocumentSession argument
The LogIncident parameter is assumed to be the HTTP request body due to being the first argument, and it will be deserialized from the incoming JSON in the request body just like you’d probably expect
The NewIncidentResponse type is roughly the equivalent to using Results.Created() in Minimal API to create a response body with the url of the newly created Incident stream and an HTTP status code of 201 for “Created.” What’s different about Wolverine.HTTP is that it can infer OpenAPI documentation from the signature of that type without requiring you to pollute your code by manually adding [ProducesResponseType] attributes on the method to get a “proper” OpenAPI document for the endpoint.
Moving on, that user id detection from the ClaimsPrincipal looks a little bit ugly to me, and likely to be repetitive. Let’s ameliorate that by introducing Wolverine’s flavor of HTTP middleware and move that code to this class:
// Using the custom type makes it easier
// for the Wolverine code generation to route
// things around. I'm not ashamed.
public record User(Guid Id);
public static class UserDetectionMiddleware
{
public static (User, ProblemDetails) Load(ClaimsPrincipal principal)
{
var userIdClaim = principal.FindFirst("user-id");
if (userIdClaim != null && Guid.TryParse(userIdClaim.Value, out var id))
{
// Everything is good, keep on trucking with this request!
return (new User(id), WolverineContinue.NoProblems);
}
// Nope, nope, nope. We got problems, so stop the presses and emit a ProblemDetails response
// with a 400 status code telling the caller that there's no valid user for this request
return (new User(Guid.Empty), new ProblemDetails { Detail = "No valid user", Status = 400});
}
}
Do note the usage of ProblemDetails in that middleware. If there is no user-id claim on the ClaimsPrincipal, we’ll abort the request by writing out the ProblemDetails stating there’s no valid user. This pattern is baked into Wolverine.HTTP to help create one off request validations. We’ll utilize this quite a bit more later.
Next, I need to add that new bit of middleware to our application. As a shortcut, I’m going to just add it to every single Wolverine HTTP endpoint by breaking back into our Program file and adding this line of code:
app.MapWolverineEndpoints(opts =>
{
// We'll add a little more in a bit...
// Creates a User object in HTTP requests based on
// the "user-id" claim
opts.AddMiddleware(typeof(UserDetectionMiddleware));
});
Now, back to our endpoint code and I’ll take advantage of that middleware by changing the method to this:
[WolverinePost("/api/incidents")]
public static NewIncidentResponse Post(
// No [FromBody] stuff necessary
LogIncident command,
// Service injection is automatic,
// just like message handlers
IDocumentSession session,
// This will be created for us through the new user detection
// middleware
User user)
{
var logged = new IncidentLogged(
command.CustomerId,
command.Contact,
command.Description,
user.Id);
var id = session.Events.StartStream<Incident>(logged).Id;
return new NewIncidentResponse(id);
}
This is a little bit of a bonus, but let’s also get rid of the need to inject the Marten IDocumentSession service by using a Wolverine “side effect” with this equivalent code:
[WolverinePost("/api/incidents")]
public static (NewIncidentResponse, IStartStream) Post(LogIncident command, User user)
{
var logged = new IncidentLogged(
command.CustomerId,
command.Contact,
command.Description,
user.Id);
var op = MartenOps.StartStream<Incident>(logged);
return (new NewIncidentResponse(op.StreamId), op);
}
In the code above I’m using the MartenOps.StartStream() method to return a “side effect” that will create a new Marten stream as part of the request instead of directly interacting with the IDocumentSession from Marten. That’s a small thing you might not care for, but it can lead to the elimination of mock objects within your unit tests as you can now write a state-based test directly against the method above like so:
public class LogIncident_handling
{
[Fact]
public void handle_the_log_incident_command()
{
// This is trivial, but the point is that
// we now have a pure function that can be
// unit tested by pushing inputs in and measuring
// outputs without any pesky mock object setup
var contact = new Contact(ContactChannel.Email);
var theCommand = new LogIncident(BaselineData.Customer1Id, contact, "It's broken");
var theUser = new User(Guid.NewGuid());
var (_, stream) = LogIncidentEndpoint.Post(theCommand, theUser);
// Test the *decision* to emit the correct
// events and make sure all that pesky left/right
// hand mapping is correct
var logged = stream.Events.Single()
.ShouldBeOfType<IncidentLogged>();
logged.CustomerId.ShouldBe(theCommand.CustomerId);
logged.Contact.ShouldBe(theCommand.Contact);
logged.LoggedBy.ShouldBe(theUser.Id);
}
}
Hey, let’s add some validation too!
We’ve already introduced middleware, so let’s just incorporate the popular Fluent Validation library into our project and let it do some basic validation on the incoming LogIncident command body, and if any validation fails, pull the ripcord and parachute out of the request with a ProblemDetails body and 400 status code that describes the validation errors.
Next, I have to add the usage of that middleware through this new line of code:
app.MapWolverineEndpoints(opts =>
{
// Direct Wolverine.HTTP to use Fluent Validation
// middleware to validate any request bodies where
// there's a known validator (or many validators)
opts.UseFluentValidationProblemDetailMiddleware();
// Creates a User object in HTTP requests based on
// the "user-id" claim
opts.AddMiddleware(typeof(UserDetectionMiddleware));
});
And add an actual validator for our LogIncident, and in this case that model is just an internal concern of our service, so I’ll just embed that new validator as an inner type of the command type like so:
public record LogIncident(
Guid CustomerId,
Contact Contact,
string Description
)
{
public class LogIncidentValidator : AbstractValidator<LogIncident>
{
// I stole this idea of using inner classes to keep them
// close to the actual model from *someone* online,
// but don't remember who
public LogIncidentValidator()
{
RuleFor(x => x.Description).NotEmpty().NotNull();
RuleFor(x => x.Contact).NotNull();
}
}
};
Now, Wolverine does have to “know” about these validators to use them within the endpoint handling, so I’ll need to have these types registered in the application’s IoC container against the right IValidator<T> interface. This is not required, but Wolverine has a (Lamar) helper to find and register these validators within your project and do so in a way that’s most efficient at runtime (i.e., there’s a micro optimization for making these validators have a Singleton life time in the container if Wolverine can see that the types are stateless). I’ll use that little helper in our Program file within the UseWolverine() configuration like so:
builder.Host.UseWolverine(opts =>
{
// lots more stuff unfortunately, but focus on the line below
// just for now:-)
// Apply the validation middleware *and* discover and register
// Fluent Validation validators
opts.UseFluentValidation();
}
And that’s that. We’ve not got Fluent Validation validation in the request handling for the LogIncident command. In a later section, I’ll explain how Wolverine does this, and try to sell you all on the idea that Wolverine is able to do this more efficiently than other commonly used frameworks *cough* MediatR *cough* that depend on conditional runtime code.
One off validation with “Compound Handlers”
As you might have noticed, the LogIncident command has a CustomerId property that we’re using as is within our HTTP handler. We should never just trust the inputs of a random client, so let’s at least validate that the command refers to a real customer.
Now, typically I like to make Wolverine message handler or HTTP endpoint methods be the “happy path” and handle exception cases and one off validations with a Wolverine feature we inelegantly call “compound handlers.”
I’m going to add a new method to our LogIncidentHandler class like so:
// Wolverine has some naming conventions for Before/Load
// or After/AfterAsync, but you can use a more descriptive
// method name and help Wolverine out with an attribute
[WolverineBefore]
public static async Task<ProblemDetails> ValidateCustomer(
LogIncident command,
// Method injection works just fine within middleware too
IDocumentSession session)
{
var exists = await session.Query<Customer>().AnyAsync(x => x.Id == command.CustomerId);
return exists
? WolverineContinue.NoProblems
: new ProblemDetails { Detail = $"Unknown customer id {command.CustomerId}", Status = 400};
}
Integration Testing
While the individual methods and middleware can all be tested separately, you do want to put everything together with an integration test to prove out whether or not all this magic really works. As I described in an earlier post where we learned how to use Alba to create an integration testing harness for a “critter stack” application, we can write an end to end integration test against the HTTP endpoint like so (this sample doesn’t cover every permutation, but hopefully you get the point):
[Fact]
public async Task create_a_new_incident_happy_path()
{
// We'll need a user
var user = new User(Guid.NewGuid());
// Log a new incident first
var initial = await Scenario(x =>
{
var contact = new Contact(ContactChannel.Email);
x.Post.Json(new LogIncident(BaselineData.Customer1Id, contact, "It's broken")).ToUrl("/api/incidents");
x.StatusCodeShouldBe(201);
x.WithClaim(new Claim("user-id", user.Id.ToString()));
});
var incidentId = initial.ReadAsJson<NewIncidentResponse>().IncidentId;
using var session = Store.LightweightSession();
var events = await session.Events.FetchStreamAsync(incidentId);
var logged = events.First().ShouldBeOfType<IncidentLogged>();
// This deserves more assertions, but you get the point...
logged.CustomerId.ShouldBe(BaselineData.Customer1Id);
}
[Fact]
public async Task log_incident_with_invalid_customer()
{
// We'll need a user
var user = new User(Guid.NewGuid());
// Reject the new incident because the Customer for
// the command cannot be found
var initial = await Scenario(x =>
{
var contact = new Contact(ContactChannel.Email);
var nonExistentCustomerId = Guid.NewGuid();
x.Post.Json(new LogIncident(nonExistentCustomerId, contact, "It's broken")).ToUrl("/api/incidents");
x.StatusCodeShouldBe(400);
x.WithClaim(new Claim("user-id", user.Id.ToString()));
});
}
}
Um, how does this all work?
So far I’ve shown you some “magic” code, and that tends to really upset some folks. I also made some big time claims about how Wolverine is able to be more efficient at runtime (alas, there is a significant “cold start” problem you can easily work around, so don’t get upset if your first ever Wolverine request isn’t snappy).
Wolverine works by using code generation to wrap its handling code around your code. That includes the middleware, and the usage of any IoC services as well. Moreover, do you know what the fastest IoC container is in all the .NET land? I certainly think that Lamar is at least in the game for that one, but nope, the answer is no IoC container at runtime.
One of the advantages of this approach is that we can preview the generated code to unravel the “magic” and explain what Wolverine is doing at runtime. Moreover, we’ve tried to add descriptive comments to the generated code to further explain what and why code is in place.
Here’s the generated code for our LogIncident endpoint (warning, ugly generated code ahead):
// <auto-generated/>
#pragma warning disable
using FluentValidation;
using Microsoft.AspNetCore.Routing;
using System;
using System.Linq;
using Wolverine.Http;
using Wolverine.Http.FluentValidation;
using Wolverine.Marten.Publishing;
using Wolverine.Runtime;
namespace Internal.Generated.WolverineHandlers
{
// START: POST_api_incidents
public class POST_api_incidents : Wolverine.Http.HttpHandler
{
private readonly Wolverine.Http.WolverineHttpOptions _wolverineHttpOptions;
private readonly Wolverine.Runtime.IWolverineRuntime _wolverineRuntime;
private readonly Wolverine.Marten.Publishing.OutboxedSessionFactory _outboxedSessionFactory;
private readonly FluentValidation.IValidator<Helpdesk.Api.LogIncident> _validator;
private readonly Wolverine.Http.FluentValidation.IProblemDetailSource<Helpdesk.Api.LogIncident> _problemDetailSource;
public POST_api_incidents(Wolverine.Http.WolverineHttpOptions wolverineHttpOptions, Wolverine.Runtime.IWolverineRuntime wolverineRuntime, Wolverine.Marten.Publishing.OutboxedSessionFactory outboxedSessionFactory, FluentValidation.IValidator<Helpdesk.Api.LogIncident> validator, Wolverine.Http.FluentValidation.IProblemDetailSource<Helpdesk.Api.LogIncident> problemDetailSource) : base(wolverineHttpOptions)
{
_wolverineHttpOptions = wolverineHttpOptions;
_wolverineRuntime = wolverineRuntime;
_outboxedSessionFactory = outboxedSessionFactory;
_validator = validator;
_problemDetailSource = problemDetailSource;
}
public override async System.Threading.Tasks.Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
var messageContext = new Wolverine.Runtime.MessageContext(_wolverineRuntime);
// Building the Marten session
await using var documentSession = _outboxedSessionFactory.OpenSession(messageContext);
// Reading the request body via JSON deserialization
var (command, jsonContinue) = await ReadJsonAsync<Helpdesk.Api.LogIncident>(httpContext);
if (jsonContinue == Wolverine.HandlerContinuation.Stop) return;
// Execute FluentValidation validators
var result1 = await Wolverine.Http.FluentValidation.Internals.FluentValidationHttpExecutor.ExecuteOne<Helpdesk.Api.LogIncident>(_validator, _problemDetailSource, command).ConfigureAwait(false);
// Evaluate whether or not the execution should be stopped based on the IResult value
if (!(result1 is Wolverine.Http.WolverineContinue))
{
await result1.ExecuteAsync(httpContext).ConfigureAwait(false);
return;
}
(var user, var problemDetails2) = Helpdesk.Api.UserDetectionMiddleware.Load(httpContext.User);
// Evaluate whether the processing should stop if there are any problems
if (!(ReferenceEquals(problemDetails2, Wolverine.Http.WolverineContinue.NoProblems)))
{
await WriteProblems(problemDetails2, httpContext).ConfigureAwait(false);
return;
}
var problemDetails3 = await Helpdesk.Api.LogIncidentEndpoint.ValidateCustomer(command, documentSession).ConfigureAwait(false);
// Evaluate whether the processing should stop if there are any problems
if (!(ReferenceEquals(problemDetails3, Wolverine.Http.WolverineContinue.NoProblems)))
{
await WriteProblems(problemDetails3, httpContext).ConfigureAwait(false);
return;
}
// The actual HTTP request handler execution
(var newIncidentResponse_response, var startStream) = Helpdesk.Api.LogIncidentEndpoint.Post(command, user);
// Placed by Wolverine's ISideEffect policy
startStream.Execute(documentSession);
// This response type customizes the HTTP response
ApplyHttpAware(newIncidentResponse_response, httpContext);
// Commit any outstanding Marten changes
await documentSession.SaveChangesAsync(httpContext.RequestAborted).ConfigureAwait(false);
// Have to flush outgoing messages just in case Marten did nothing because of https://github.com/JasperFx/wolverine/issues/536
await messageContext.FlushOutgoingMessagesAsync().ConfigureAwait(false);
// Writing the response body to JSON because this was the first 'return variable' in the method signature
await WriteJsonAsync(httpContext, newIncidentResponse_response);
}
}
// END: POST_api_incidents
}
Summary and What’s Next
The Wolverine.HTTP library was originally built to be a supplement to MVC Core or Minimal API by allowing you to create endpoints that integrated well into Wolverine’s messaging, transactional outbox functionality, and existing transactional middleware. It has since grown into being more of a full fledged alternative for building web services, but with potential for substantially less ceremony and far more testability than MVC Core.
In later posts I’ll talk more about the runtime architecture and how Wolverine squeezes out more performance by eliminating conditional runtime switching, reducing object allocations, and sidestepping the dictionary lookups that are endemic to other “flexible” .NET frameworks like MVC Core.
Wolverine.HTTP has not yet been used with Razor at all, and I’m not sure that will ever happen. Not to worry though, you can happily use Wolverine.HTTP in the same application with MVC Core controllers or even Minimal API endpoints.
OpenAPI support has been a constant challenge with Wolverine.HTTP as the OpenAPI generation in ASP.Net Core is very MVC-centric, but I think we’re in much better shape now.
In the next post, I think we’ll introduce asynchronous messaging with Rabbit MQ. At some point in this series I’m going to talk more about how the “Critter Stack” is well suited for a lower ceremony vertical slice architecture that (hopefully) creates a maintainable and testable codebase without all the typical Clean/Onion Architecture baggage that I could personally do without.
And just for fun…
My “History” with ASP.Net MVC
There’s no useful content in this section, just some navel-gazing. Even though I really haven’t had to use ASP.Net MVC too terribly much, I do have a long history with it:
In the beginning, there was what we now call ASP Classic, and it was good. For that day and time anyway when we would happily code directly in production and before TDD and SOLID and namby-pamby “source control.” (I started my development career in “Shadow IT” if that’s not obvious here). And when we did use source control, it was VSS because on the sly because the official source control in the office was something far, far worse that was COBOL-centric that I don’t think even exists any longer.
Next there was ASP.Net WebForms and it was dreadful. I hated it.
We started collectively learning about Agile and wanted to practice Test Driven Development, and began to hate WebForms even more
Ruby on Rails came out in the middle 00’s and made what later became the ALT.Net community absolutely loathe WebForms even more than we already did
At an MVP Summit on the Microsoft campus, the one and only Scott Guthrie, the Gu himself, showed a very early prototype of ASP.Net MVC to a handful of us and I was intrigued. That continued onward through the official unveiling of MVC at the very first ALT.Net open spaces event in Austin in ’07.
A few collaborators and I decided that early ASP.Net MVC was too high ceremony and went all “Captain Ahab” trying to make an alternative, open source framework called FubuMVC go as an alternative — all while NancyFx, a “yet another Sinatra clone” became far more successful years before Microsoft finally got around to their own inevitable Sinatra clone (Minimal API)
After .NET Core came along and made .NET a helluva lot better ecosystem, I decided that whatever, MVC Core is fine, it’s not going to be the biggest problem on our project, and if the client wants to use it, there’s no need to be upset about it. It’s fine, no really.
MVC Core has gotten some incremental improvements over time that made it lower ceremony than earlier ASP.Net MVC, and that’s worth calling out as a positive
People working with MVC Core started running into the problem of bloated controllers, and started using early MediatR as a way to kind of, sort of manage controller bloat by offloading it into focused command handlers. I mocked that approach mercilessly, but that was partially because of how awful a time I had helping folks do absurdly complicated middleware schemes with MediatR using StructureMap or Lamar (MVC Core + MediatR is probably worthwhile as a forcing function to avoid the controller bloat problems with MVC Core by itself)
I worked on several long-running codebases built with MVC Core based on Clean Architecture templates that were ginormous piles of technical debt, and I absolutely blame MVC Core as a contributing factor for that
I’m back to mildly disliking MVC Core (and I’m outright hostile to Clean/Onion templates). Not that you can’t write maintainable systems with MVC Core, but I think that its idiomatic usage can easily lead to unmaintainable systems. Let’s just say that I don’t think that MVC Core — and especially combined with some kind of Clean/Onion Architecture template as it very commonly is out in the wild — leads folks to the “pit of success” in the long run
Let’s build a small web service application using the whole “Critter Stack” and their friends, one small step at a time. For right now, the “finished” code is at CritterStackHelpDesk on GitHub.
Before I go on with anything else in this series, I think we should establish some automated testing infrastructure for our incident tracking, help desk service. While we’re absolutely going to talk about how to structure code with Wolverine to make isolated unit testing as easy as possible for our domain logic, there are some elements of your system’s behavior that are best tested with automated integration tests that use the system’s infrastructure.
In this post I’m going to show you how I like to set up an integration testing harness for a “Critter Stack” service. I’m going to use xUnit.Net in this post, and while the mechanics would be a little different, I think the basic concepts should be easily transferable to other testing libraries like NUnit or MSTest. I’m also going to bring in the Alba library that we’ll use for testing HTTP calls through our system in memory, but in this first step, all you need to understand is that Alba is helping to set up the system under test in our testing harness.
Heads up a little bit, I’m skipping to the “finished” state of the help desk API code in this post, so there’s some Marten and Wolverine concepts sneaking in that haven’t been introduced until now.
First, let’s start our new testing project with:
dotnet new xunit
Then add some additional Nuget references:
dotnet add package Shouldly
dotnet add package Alba
That gives us a skeleton of the testing project. Before going on, we need to add a project reference from our new testing project to the entry point project of our help desk API. As we are worried about integration testing right now, we’re going to want the testing project to be able to start the system under test project up by calling the normal Program.Main() entrypoint so that we’re running the application the way that the system is normally configured — give or take a few overrides.
Let’s stop and talk about this a little bit because I think this is an important point. I think integration tests are more “valid” (i.e. less prone to false positives or false negatives) as they more closely reflect the actual system. I don’t want completely separate bootstrapping for the test harness that may or may not reflect the application’s production bootstrapping (don’t blow that point off, I’ve seen countless teams do partial IoC configuration for testing that can vary quite a bit from the application’s configuration).
So if you’ll accept my argument that we should be bootstrapping the system under test with its own Program.Main() entry point, our next step is to add this code to the main service to enable the test project to access that entry point:
using System.Runtime.CompilerServices;
// You have to do this in order to reference the Program
// entry point in the test harness
[assembly:InternalsVisibleTo("Helpdesk.Api.Tests")]
Switching finally to our testing project, I like to create a class I usually call AppFixture that manages the lifetime of the system under test running in our test project like so:
public class AppFixture : IAsyncLifetime
{
public IAlbaHost Host { get; private set; }
// This is a one time initialization of the
// system under test before the first usage
public async Task InitializeAsync()
{
// Sorry folks, but this is absolutely necessary if you
// use Oakton for command line processing and want to
// use WebApplicationFactory and/or Alba for integration testing
OaktonEnvironment.AutoStartHost = true;
// This is bootstrapping the actual application using
// its implied Program.Main() set up
// This is using a library named "Alba". See https://jasperfx.github.io/alba for more information
Host = await AlbaHost.For<Program>(x =>
{
x.ConfigureServices(services =>
{
// We'll be using Rabbit MQ messaging later...
services.DisableAllExternalWolverineTransports();
// We're going to establish some baseline data
// for testing
services.InitializeMartenWith<BaselineData>();
});
}, new AuthenticationStub());
}
public Task DisposeAsync()
{
if (Host != null)
{
return Host.DisposeAsync().AsTask();
}
return Task.CompletedTask;
}
}
A few notes about the code above:
Alba is using the WebApplicationFactory under the covers to bootstrap our help desk API service using the in memory TestServer in place of Kestrel. WebApplicationFactory does allow us to modify the IoC service registrations for our system and override parts of the system’s normal configuration
In this case, I’m telling Wolverine to effectively stub out all external transports. In later posts we’ll use Rabbit MQ for example to publish messages to an external process, but in this test harness we’re going to turn that off and simple have Wolverine be able to “catch” the outgoing messages in our tests. See Wolverine’s test automation support documentation for more information about this.
The DisposeAsync() method is very important. If you want to make your integration tests be repeatable and run smoothly as you iterate, you need the tests to clean up after themselves and not leave locks on resources like ports or files that could stop the next test run from functioning correctly
Pay attention to the `OaktonEnvironment.AutoStartHost = true;` call, that’s 100% necessary if your application is using Oakton for command parsing. Sorry.
As will be inevitably necessary, I’m using Alba’s facility for stubbing out web authentication that allows us to both sidestep pesky authentication infrastucture in functional testing while also happily letting us pass along user claims as test inputs in individual tests
Bootstrapping the IHost for your application can be expensive, so I prefer to share that host across tests whenever possible, and I generally rely on having individual tests establish their inputs at beginning of each test. See the xUnit.Net documentation on sharing fixtures between tests for more context about the xUnit mechanics.
For the Marten baseline data, right now I’m just making sure there’s at least one valid Customer document that we’ll need later:
public class BaselineData : IInitialData
{
public static Guid Customer1Id { get; } = Guid.NewGuid();
public async Task Populate(IDocumentStore store, CancellationToken cancellation)
{
await using var session = store.LightweightSession();
session.Store(new Customer
{
Id = Customer1Id,
Region = "West Cost",
Duration = new ContractDuration(DateOnly.FromDateTime(DateTime.Today.Subtract(100.Days())), DateOnly.FromDateTime(DateTime.Today.Add(100.Days())))
});
await session.SaveChangesAsync(cancellation);
}
}
To simplify the usage a little bit, I like to have a base class for integration tests that I like to call IntegrationContext:
[Collection("integration")]
public abstract class IntegrationContext : IAsyncLifetime
{
private readonly AppFixture _fixture;
protected IntegrationContext(AppFixture fixture)
{
_fixture = fixture;
}
// more....
public IAlbaHost Host => _fixture.Host;
public IDocumentStore Store => _fixture.Host.Services.GetRequiredService<IDocumentStore>();
async Task IAsyncLifetime.InitializeAsync()
{
// Using Marten, wipe out all data and reset the state
// back to exactly what we described in BaselineData
await Store.Advanced.ResetAllData();
}
// This is required because of the IAsyncLifetime
// interface. Note that I do *not* tear down database
// state after the test. That's purposeful
public Task DisposeAsync()
{
return Task.CompletedTask;
}
// This is just delegating to Alba to run HTTP requests
// end to end
public async Task<IScenarioResult> Scenario(Action<Scenario> configure)
{
return await Host.Scenario(configure);
}
// This method allows us to make HTTP calls into our system
// in memory with Alba, but do so within Wolverine's test support
// for message tracking to both record outgoing messages and to ensure
// that any cascaded work spawned by the initial command is completed
// before passing control back to the calling test
protected async Task<(ITrackedSession, IScenarioResult)> TrackedHttpCall(Action<Scenario> configuration)
{
IScenarioResult result = null;
// The outer part is tying into Wolverine's test support
// to "wait" for all detected message activity to complete
var tracked = await Host.ExecuteAndWaitAsync(async () =>
{
// The inner part here is actually making an HTTP request
// to the system under test with Alba
result = await Host.Scenario(configuration);
});
return (tracked, result);
}
}
The first thing I want to draw your attention to is the call to await Store.Advanced.ResetAllData(); in the InitializeAsync() method that will be called before each of our integration tests executing. In my approach, I strongly prefer to reset the state of the database before each test in order to start from a known system state. I’m also assuming that each test if necessary, will add additional state to the system’s Marten database as necessary for the test. This philosophically is what I’ve long called “Self-Contained Tests.” I also think it’s important to have the tests leave the database state alone after a test run so that if you are running tests one at a time you can use the left over database state to help troubleshoot why a test might have failed.
Other folks will try to spin up a separate database (maybe with TestContainers) per test or even a completely separate IHost per test, but I think that the cost of doing it that way is just too slow. I’d rather reset the system between tests and not incur the cost of recycling database containers and/or the system’s IHost. This comes at the cost of forcing your test suite to run tests in serial order, but I also think that xUnit.Net is not the best possible tool at parallel test runs, so I’m not sure you lose out on anything there.
And now for an actual test. We have an HTTP endpoint in our system we built early on that can process a LogIncident command, and create a new event stream for this new Incident with a single IncidentLogged event. I’ve skipped ahead a little bit and added a requirement that we capture a user id from an expected Claim on the ClaimsPrincipal for the current request that you’ll see reflected in the test below:
public class log_incident : IntegrationContext
{
public log_incident(AppFixture fixture) : base(fixture)
{
}
[Fact]
public async Task create_a_new_incident()
{
// We'll need a user
var user = new User(Guid.NewGuid());
// Log a new incident by calling the HTTP
// endpoint in our system
var initial = await Scenario(x =>
{
var contact = new Contact(ContactChannel.Email);
x.Post.Json(new LogIncident(BaselineData.Customer1Id, contact, "It's broken")).ToUrl("/api/incidents");
x.StatusCodeShouldBe(201);
x.WithClaim(new Claim("user-id", user.Id.ToString()));
});
var incidentId = initial.ReadAsJson<NewIncidentResponse>().IncidentId;
using var session = Store.LightweightSession();
var events = await session.Events.FetchStreamAsync(incidentId);
var logged = events.First().ShouldBeOfType<IncidentLogged>();
// This deserves more assertions, but you get the point...
logged.CustomerId.ShouldBe(BaselineData.Customer1Id);
}
}
Summary and What’s Next
The “Critter Stack” core team and our community care very deeply about effective testing, so we’ve invested from the very beginning in making integration testing as easy as possible with both Marten and Wolverine.
Alba is another little library from the JasperFx family that just makes it easier to write integration tests at the HTTP layer. Alba is perfect for doing integration testing of your web services. I definitely find it advantageous to be able to quickly bootstrap a web service project and run tests completely in memory on demand. That’s a much easier and quicker feedback cycle than trying to deploy the service and write tests that remotely interact with the web service through HTTP. And I shouldn’t even have to mention how absurdly slow it is in comparison to try to test the same web service functionality through the actual user interface with something like Selenium.
From the Marten side of things, PostgreSQL has a pretty small Docker image size, so it’s pretty painless to spin up on development boxes. Especially contrasted with situations where development teams share a centralized development database (shudder, hope not many folks still do that), having an isolated database for each developer that they can also tear down and rebuild at will certainly helps make it a lot easier to succeed with automated integration testing.
I think that document databases in general are a lot easier to deal with in automated testing than using a relational database with an ORM as the persistence tooling as it’s much less friction in setting up database schemas or to tear down database state. Marten goes a step farther than most persistence tools by having built in APIs to tear down database state or reset to baseline data sets in between tests.
We’ll dig deeper into Wolverine’s integration testing support later in this series with message handler testing, testing handlers that in turn spawn other messages, and dealing with external messaging in tests.
I think the next post is just going to be a quick survey of “Marten as Document Database” before I get back to Wolverine’s HTTP endpoint model.
TL;DR: The full critter stack combo can make CQRS command handler code much simpler and easier to test than any other framework on the planet. Fight me.
Hey, did you know that JasperFx Software is ready for formal support plans for Marten and Wolverine? Not only are we trying to make the “Critter Stack” tools be viable long term options for your shop, we’re also interested in hearing your opinions about the tools and how they should change.We’re also certainly open to help you succeed with your software development projects on a consulting basis whether you’re using any part of the Critter Stack or any other .NET server side tooling.
Let’s build a small web service application using the whole “Critter Stack” and their friends, one small step at a time. For right now, the “finished” code is at CritterStackHelpDesk on GitHub.
This series has been written partially in response to some constructive criticism that my writings on the “Critter Stack” suffered from introducing too many libraries or concepts all at once. As a reaction to that, this series is trying to only introduce one new capability or library at a time — which brought on some constructive criticism from someone else that the series isn’t making it obvious why anyone should care about the “Critter Stack” in the first place. So especially for Rob Conery, I give you:
Last time out we talked using Marten’s facilities for optimistic concurrency or exclusive locking to protect our system from inconsistencies due to concurrent commands being processed against the same incident event stream. In the process of that post, I showed the code for a command handler for the CategoriseIncident command shown below that I purposely wrote in a long hand form as explicitly as possible to avoid introducing too many new concepts at once:
public static class LongHandCategoriseIncidentHandler
{
public static async Task Handle(
CategoriseIncident command,
IDocumentSession session,
CancellationToken cancellationToken)
{
var stream = await session
.Events
.FetchForWriting<IncidentDetails>(command.Id, cancellationToken);
// Don't worry, we're going to clean this up later
if (stream.Aggregate == null)
{
throw new ArgumentOutOfRangeException(nameof(command), "Unknown incident id " + command.Id);
}
// We need to validate whether this command actually
// should do anything
if (stream.Aggregate.Category != command.Category)
{
var categorised = new IncidentCategorised
{
Category = command.Category,
UserId = SystemId
};
stream.AppendOne(categorised);
await session.SaveChangesAsync(cancellationToken);
}
}
Hopefully that code is relatively easy to follow, but it’s still pretty busy and there’s a mixture of business logic and fiddling with infrastructure code that’s not particularly helpful when the code inevitably gets more complicated than that as the requirements grow. As we’ll learn about later in this series, both Marten and Wolverine have some built in tooling to enable effective automated integration testing and do so much more effectively than just about any other tool out there. All the same though, you just don’t want to be testing the business logic by trudging through integration tests if you don’t have to (see my only rule of testing).
So let’s definitely look at how Wolverine plays nicely with Marten using its aggregate handler workflow recipe to simplify our handler for easier unit testing and just flat out cleaner code.
First off, I’m going to add the WolverineFx.Marten Nuget to our application:
dotnet add package WolverineFx.Marten
Next, break into our application’s Program file and add one call to the Marten configuration to incorporate some Wolverine goodness into Marten in our application:
builder.Services.AddMarten(opts =>
{
// Existing Marten configuration...
})
// This is a mild optimization
.UseLightweightSessions()
// Use this directive to add Wolverine transactional middleware for Marten
// and the Wolverine transactional outbox support as well
.IntegrateWithWolverine();
And now, let’s rewrite our CategoriseIncident command handler with a completely equivalent implementation using the “aggregate handler workflow” recipe:
public static class CategoriseIncidentHandler
{
// Kinda faked, don't pay any attention to this please!
public static readonly Guid SystemId = Guid.Parse("4773f679-dcf2-4f99-bc2d-ce196815dd29");
// This Wolverine handler appends an IncidentCategorised event to an event stream
// for the related IncidentDetails aggregate referred to by the CategoriseIncident.IncidentId
// value from the command
[AggregateHandler]
public static IEnumerable<object> Handle(CategoriseIncident command, IncidentDetails existing)
{
if (existing.Category != command.Category)
{
// This event will be appended to the incident
// stream after this method is called
yield return new IncidentCategorised
{
Category = command.Category,
UserId = SystemId
};
}
}
}
In the handler method above, the presence of the[AggregateHandler]attribute directs Wolverine to wrap some middleware around the execution of our Handle() method that:
“Knows” the aggregate type in question is the second argument to the handler method, so in this case, IncidentDetails
Scans the CategoriseIncident type looking for a property that identifies the IncidentDetails (which will make it utilize the Id property in this case, but the docs spell this convention in detail)
Does all the work to delegate and coordinate work in the logical command flow between the Marten infrastructure and our little bitty Handle() method
To visualize this, Wolverine is generating its own internal message handler for CategoriseIncident that has this simplified workflow:
And as a preview to a topic I’ll dive into in much more detail in a later post, here’s part of the (admittedly ugly in the way that only auto-generated code can be) C# code that Wolverine generates around our handler method:
public override async System.Threading.Tasks.Task HandleAsync(Wolverine.Runtime.MessageContext context, System.Threading.CancellationToken cancellation)
{
// The actual message body
var categoriseIncident = (Helpdesk.Api.CategoriseIncident)context.Envelope.Message;
await using var documentSession = _outboxedSessionFactory.OpenSession(context);
var eventStore = documentSession.Events;
// Loading Marten aggregate
var eventStream = await eventStore.FetchForWriting<Helpdesk.Api.IncidentDetails>(categoriseIncident.Id, categoriseIncident.Version, cancellation).ConfigureAwait(false);
// The actual message execution
var outgoing1 = Helpdesk.Api.CategoriseIncidentHandler.Handle(categoriseIncident, eventStream.Aggregate);
if (outgoing1 != null)
{
// Capturing any possible events returned from the command handlers
eventStream.AppendMany(outgoing1);
}
await documentSession.SaveChangesAsync(cancellation).ConfigureAwait(false);
}
And lastly, we’ve now reduced our CategoriseIncident command handler to the point where the code that we are actually having to write is a pure function, meaning that it’s a simple matter of inputs and outputs with no dependency on any kind of stateful infrastructure. You absolutely care about isolating any kind of business logic into pure functions because that code becomes much easier to unit test.
And to prove that last statement, here’s what the unit tests for our Handle(CategoriseIncident, IncidentDetails) could look like using xUnit.Net and Shouldly:
public class CategoriseIncidentTests
{
[Fact]
public void raise_categorized_event_if_changed()
{
// Arrange
var command = new CategoriseIncident
{
Category = IncidentCategory.Database
};
var details = new IncidentDetails(
Guid.NewGuid(),
Guid.NewGuid(),
IncidentStatus.Closed,
new IncidentNote[0],
IncidentCategory.Hardware);
// Act
var events = CategoriseIncidentEndpoint.Post(command, details);
// Assert
var categorised = events.Single().ShouldBeOfType<IncidentCategorised>();
categorised
.Category.ShouldBe(IncidentCategory.Database);
}
[Fact]
public void do_not_raise_event_if_the_category_would_not_change()
{
// Arrange
var command = new CategoriseIncident
{
Category = IncidentCategory.Database
};
var details = new IncidentDetails(Guid.NewGuid(), Guid.NewGuid(), IncidentStatus.Closed, new IncidentNote[0],
IncidentCategory.Database);
// Act
var events = CategoriseIncidentEndpoint.Post(command, details);
// Assert no events were appended
events.ShouldBeEmpty();
}
}
In the unit test code above, we were able to exercise the decision about what events (if any) should be appended to the incident event stream without any dependency whatsoever on any kind of infrastructure. The easiest kind of unit test to write and to read later is a test that has a clear relationship between the test inputs and outputs with minimal noise code for setting up state — and that’s exactly what we have up above. No message mock object set up, no need to setup database state, nothing. Just, “here’s the existing state and this command, now tell me what events should be appended.”
Summary and What’s Next
The full Critter Stack “aggregate handler workflow” recipe leads to very low ceremony code to implement command handlers within a CQRS style architecture. This recipe also leads to a code structure where your business logic is relatively easy to test with fast running unit testing. And we arrived at that point without having to watch umpteen hours of “Clean Architecture” YouTube snake oil videos, introducing a ton of “Ports and Adapter” style abstractions to clutter up our code, or scattering our code for the single CategoriseIncident message handler across 3-4 “Onion Architecture” projects within a massive .NET solution.
This approach was heavily inspired by the Decider pattern that originated for Event Sourcing within the F# community. But whereas the F# approach uses language tricks (and I don’t mean that pejoratively here), Wolverine is getting to a lower ceremony approach by doing that runtime code generation around our code.
If you look back to the sequence diagram up above that tries to explain the control flow, Wolverine is purposely using Jim Shore’s idea of the “A-Frame Architecture” (it’s not really an architectural style despite the name, so don’t even try to do an apples to apples comparison between it and something more prescriptive like the Clean Architecture). In this approach, Wolverine is purposely decoupling the Marten infrastructure away from the CategoriseIncident handler logic that is implementing the business logic that “decides” what to do next by mediating between Marten and the handler. The “A-Frame” name comes from visualizing that mediation like this (Wolverine calls into the infrastructure services like Marten and the business logic so the domain logic doesn’t have to):
Now, there’s a lot more stuff that our command handlers may very well need to implement, including:
Message input validation
Instrumentation and observability
Error handling and resiliency protections ’cause it’s an imperfect world!
Publishing the new events to some other internal message handler that will take additional actions after our first command has “decided” what to do next
Publishing the new events as some kind of external message to another process
Enrolling in a transactional outbox of some sort or another to keep the system in a consistent state — and you really need to care about this capability!!!
And oh, yeah, do all that with minimal code ceremony, be testable with unit tests as much as possible, and be feasible to do automated integration testing when we have to.
We’ll get to all the items in that list above in this series, but I think in the next post I’d like to introduce Wolverine’s HTTP handler recipe and build out more aggregate command handlers, but this time with an HTTP endpoint. Until next time…
I’m helping a JasperFx Software client get a new system off the ground that’s using both Hot Chocolate for GraphQL and Marten for event sourcing and general persistence. That’s led to a couple blog posts so far:
Today though, I want to talk about some early ideas for automating integration testing of GraphQL endpoints. Before I show my intended approach, here’s a video from ChiliCream (the company behind Hot Chocolate) showing their recommendations for testing:
Now, to be honest, I don’t agree with their recommended approach. I played a lot of sports growing up in a small town, and one of my coach’s favorite sayings actually applies here:
If you want to be good, practice like you play
every basketball coach I ever played for
That saying really just meant to try to do things well in practice so that it would carry right through into the real games. In the case of integration testing, I want to be testing against the “real” application configuration including the full ASP.Net Core middleware stack and the exact Marten and Hot Chocolate configuration for the application instead of against a separately constructed IoC and Hot Chocolate configuration. In this particular case, the application is using multi-tenancy through a separate database per tenant strategy with the tenant selection at runtime being ultimately dependent upon expected claims on the ClaimsPrincipal for the request.
All that being said, I’m unsurprisingly opting to use the Alba library within xUnit specifications to test through the entire application stack with just a few overrides of the application. My usual approach with xUnit.Net and Alba is to create a shared context that manages the lifecycle of the bootstrapped application in memory like so:
public class AppFixture : IAsyncLifetime
{
public IAlbaHost Host { get; private set; }
public async Task InitializeAsync()
{
// This is bootstrapping the actual application using
// its implied Program.Main() set up
Host = await AlbaHost.For<Program>(x => { });
}
Moving on to the GraphQL mechanics, what I’ve come up with so far is to put a GraphQL query and/or mutation in a flat file within the test project. I hate not having the test inputs in the same code file as the test, but I’m trying to offset that by spitting out the GraphQL query text into the test output to make it a little easier to troubleshoot failing tests. The Alba mechanics — so far — look like this (simplified a bit from the real code):
public Task<IScenarioResult> PostGraphqlQueryFile(string filename)
{
// This ugly code is just loading up the GraphQL query from
// a named file
var path = AppContext
.BaseDirectory
.ParentDirectory()
.ParentDirectory()
.ParentDirectory()
.AppendPath("GraphQL")
.AppendPath(filename);
var queryText = File.ReadAllText(path);
// Building up the right JSON to POST to the /graphql
// endpoint
var dictionary = new Dictionary<string, string>();
dictionary["query"] = queryText;
var json = JsonConvert.SerializeObject(dictionary);
// Write the GraphQL query being used to the test output
// just as information for troubleshooting
this.output.WriteLine(queryText);
// Using Alba to run a GraphQL request end to end
// in memory. This would throw an exception if the
// HTTP status code is not 200
return Host.Scenario(x =>
{
// I'm omitting some code here that we're using to mimic
// the tenant detection in the real code
x.Post.Url("/graphql").ContentType("application/json");
// Dirty hackery.
x.ConfigureHttpContext(c =>
{
var stream = c.Request.Body;
// This encoding turned out to be necessary
// Thank you Stackoverflow!
stream.WriteAsync(Encoding.UTF8.GetBytes(json));
stream.Position = 0;
});
});
}
That’s the basics of running the GraphQL request through, but part of the value of Alba in testing more traditional “JSON over HTTP” endpoints is being able to easily read the HTTP outputs with Alba’s built in helpers that use the application’s JSON serialization setup. I was missing that initially with the GraphQL usage, so I added this extra helper for testing a single GraphQL query or mutation at a time where there is a return body from the mutation:
public async Task<T> PostGraphqlQueryFile<T>(string filename)
{
// Delegating to the previous method
var result = await PostGraphqlQueryFile(filename);
// Get the raw HTTP response
var text = await result.ReadAsTextAsync();
// I'm using Newtonsoft.Json to get into the raw JSON
// a little bit
var json = (JObject)JsonConvert.DeserializeObject(text);
// Make the test fail if the GraphQL response had any errors
json.ContainsKey("errors").ShouldBeFalse($"GraphQL response had errors:\n{text}");
// Find the *actual* response within the larger GraphQL response
// wrapper structure
var data = json["data"].First().First().First().First();
// This would vary a bit in your application
var serializer = JsonSerializer.Create(new JsonSerializerSettings
{
ContractResolver = new CamelCasePropertyNamesContractResolver()
});
// Deserialize the raw JSON into the response type for
// easier access in tests because "strong typing for the win!"
return serializer.Deserialize<T>(new JTokenReader(data));
}
And after all that, that leads to integration tests in test fixture classes subclassing our IntegrationContext base type like this:
public class SomeTestFixture : IntegrationContext
{
public SomeTestFixture(ITestOutputHelper output, AppFixture fixture) : base(output, fixture)
{
}
[Fact]
public async Task perform_mutation()
{
var response = await this.PostGraphqlQueryFile<SomeResponseType>("someGraphQLMutation.txt");
// Use the strong typed response object in the
// "assert" part of your test
}
}
Summary
We’ll see how it goes, but already this harness helped me out to have some repeatable steps to tweak transaction management and multi-tenancy without breaking the actual code. With the custom harness around it, I think we’ve made the GraphQL endpoint testing be somewhat declarative.
I’m weaseling into making a second blog post about a code sample that I mostly stole from just to meet my unofficial goal of 2-3 posts a week promoting the Critter Stack.
using DailyAvailability = System.Collections.Generic.IReadOnlyList<Booking.RoomReservations.GettingRoomTypeAvailability.DailyRoomTypeAvailability>;
namespace Booking.RoomReservations.ReservingRoom;
public record ReserveRoomRequest(
RoomType RoomType,
DateOnly From,
DateOnly To,
string GuestId,
int NumberOfPeople
);
public static class ReserveRoomEndpoint
{
// More on this in a second...
public static async Task<DailyAvailability> LoadAsync(
ReserveRoomRequest request,
IDocumentSession session)
{
// Look up the availability of this room type during the requested period
return (await session.QueryAsync(new GetRoomTypeAvailabilityForPeriod(request))).ToList();
}
[WolverinePost("/api/reservations")]
public static (CreationResponse, StartStream<RoomReservation>) Post(
ReserveRoomRequest command,
DailyAvailability dailyAvailability)
{
// Make sure there is availability for every day
if (dailyAvailability.Any(x => x.AvailableRooms == 0))
{
throw new InvalidOperationException("Not enough available rooms!");
}
var reservationId = CombGuidIdGeneration.NewGuid().ToString();
// I copied this, but I'd probably eliminate the record usage in favor
// of init only properties so you can make the potentially error prone
// mapping easier to troubleshoot in the future
// That folks is the voice of experience talking
var reserved = new RoomReserved(
reservationId,
null,
command.RoomType,
command.From,
command.To,
command.GuestId,
command.NumberOfPeople,
ReservationSource.Api,
DateTimeOffset.UtcNow
);
return (
// This would be the response body, and this also helps Wolverine
// to create OpenAPI metadata for the endpoint
new CreationResponse($"/api/reservations/{reservationId}"),
// This return value is recognized by Wolverine as a "side effect"
// that will be processed as part of a Marten transaction
new StartStream<RoomReservation>(reservationId, reserved)
);
}
}
The original intent of that code sample was to show off how the full “critter stack” (Marten & Wolverine together) enables relatively low ceremony code that also promotes a high degree of testability. And does all of that without requiring developers to invest a lot of time in complicated , prescriptive architectures like a typical Clean Architecture structure.
Specifically today though, I want to zoom in on “testability” and talk about how Wolverine explicitly encourages code that exhibits what Jim Shore famously called the “A Frame Architecture” in its message handlers, but does so with functional decomposition rather than oodles of abstractions and layers.
Using the “A-Frame Architecture”, you roughly want to divide your code into three sets of functionality:
The domain logic for your system, which I would say includes “deciding” what actions to take next.
Infrastructural service providers
Conductor or mediator code that invokes both the infrastructure and domain logic code to decouple the domain logic from infrastructure code
In the message handler above for the `ReserveRoomRequest` command, Wolverine itself is acting as the “glue” around the methods of the HTTP handler code above that keeps the domain logic (the ReserveRoomEndpoint.Post() method that “decides” what event should be captured) and the raw Marten infrastructure to load existing data and persist changes back to the database.
To illustrate that in action, here’s the full generated code that Wolverine compiles to actually handle the full HTTP request (with some explanatory annotations I made by hand):
public class POST_api_reservations : Wolverine.Http.HttpHandler
{
private readonly Wolverine.Http.WolverineHttpOptions _wolverineHttpOptions;
private readonly Marten.ISessionFactory _sessionFactory;
public POST_api_reservations(Wolverine.Http.WolverineHttpOptions wolverineHttpOptions, Marten.ISessionFactory sessionFactory) : base(wolverineHttpOptions)
{
_wolverineHttpOptions = wolverineHttpOptions;
_sessionFactory = sessionFactory;
}
public override async System.Threading.Tasks.Task Handle(Microsoft.AspNetCore.Http.HttpContext httpContext)
{
await using var documentSession = _sessionFactory.OpenSession();
var (command, jsonContinue) = await ReadJsonAsync<Booking.RoomReservations.ReservingRoom.ReserveRoomRequest>(httpContext);
if (jsonContinue == Wolverine.HandlerContinuation.Stop) return;
// Wolverine has a convention to call methods named
// "LoadAsync()" before the main endpoint method, and
// to pipe data returned from this "Before" method
// to the parameter inputs of the main method
// as that actually makes sense
var dailyRoomTypeAvailabilityIReadOnlyList = await Booking.RoomReservations.ReservingRoom.ReserveRoomEndpoint.LoadAsync(command, documentSession).ConfigureAwait(false);
// Call the "real" HTTP handler method.
// The first value is the HTTP response body
// The second value is a "side effect" that
// will be part of the transaction around this
(var creationResponse, var startStream) = Booking.RoomReservations.ReservingRoom.ReserveRoomEndpoint.Post(command, dailyRoomTypeAvailabilityIReadOnlyList);
// Placed by Wolverine's ISideEffect policy
startStream.Execute(documentSession);
// This little ugly code helps get the correct
// status code for creation for those of you
// who can't be satisfied by using 200 for everything ((Wolverine.Http.IHttpAware)creationResponse).Apply(httpContext);
// Commit any outstanding Marten changes
await documentSession.SaveChangesAsync(httpContext.RequestAborted).ConfigureAwait(false);
// Write the response body as JSON
await WriteJsonAsync(httpContext, creationResponse);
}
}
Wolverine by itself as acting as the mediator between the infrastructure concerns (loading & persisting data) and the business logic function which in Wolverine world becomes a pure function that are typically much easier to unit test than code that has direct coupling to infrastructure concerns — even if that coupling is through abstractions.
Testing wise, if I were actually building a real endpoint like that shown above, I would choose to:
Unit test the Post() method itself by “pushing” inputs to it through the room availability and command data, then assert the expected outcome on the event published through the StartStream<Reservation> value returned by that method. That’s pure state-based testing for the easiest possible unit testing. As an aside, I would claim that this method is an example of the Decider pattern for testable event sourcing business logic code.
I don’t think I’d bother testing the LoadAsync() method by itself, but instead I’d opt to use something like Alba to write an end to end test at the HTTP layer to prove out the entire workflow, but only after the unit tests for the Post() method are all passing.
Responsibility Driven Design
While the “A-Frame Architecture” metaphor is a relatively recent influence upon my design thinking, I’ve long been a proponent of Responsibility Driven Design (RDD) as explained by Rebecca Wirfs-Brock’s excellent A Brief Tour of Responsibility Driven Design. Don’t dismiss that paper because of its age, because the basic concepts and strategies for identifying different responsibilities in your system as a prerequisite for designing or structuring code put forth in that paper are absolutely useful even today.
Applying Responsibility Driven Development to the sample HTTP endpoint code above, I would say that:
The Marten IDocumentSession is a “service provider”
The Wolverine generated code acts as a “coordinator”
The Post() method is responsible for “deciding” what events should be emitted and persisted. One of the most helpful pieces of advice in RDD is to sometimes treat “deciding” to do an action as a separate responsibility from actually carrying out the action. That can lead to better isolating the decision making logic away from infrastructural concerns for easier testing